交通×ディープラーニング 。信号機にDQNを用いて、交通渋滞を改善させる
今回紹介するのは、つい2,3日ほど前にAAAI(アメリカ人工知能学会) 2019という会議で紹介されていた交通×ディープラーニングの論文です。この論文自体は少し古いのですが、現在AIの研究の中でも注目を集めている分野で、とても実用的で面白い内容となっています。
紹介論文 Coordinated Deep Reinforcement Learners for Traffic Light Control
目次
➀交通渋滞は大きな経済損失
➁信号をディープラーニング で抑制してみる
➂DQN
➃交通情報を視覚的に捉えて画像として扱う
➄実用化は期待されるが一歩で課題も
交通渋滞は大きな経済損失

交通渋滞による経済損失は実は甚大であり、EUではGDPの1%に相当すると推測されています。渋滞、特に事故や台風等に関係なく発生する『自然渋滞』はなくせないのでしょうか。
高度なIT化・自動化が進んでいる現在、この渋滞問題に関してもITソリューションが期待されています。ところがそもそも交通制御の要である信号機に着目してみると、多くの信号機は交通状態に関係なくマイペースに色を変えており、良くも悪くも知性的ではなさそうな制御をしていることに気が付きます。(実際にはセンサーを使って制御を行っている場所も一部あります。)
今回紹介する論文は、信号機をより賢く交通状況により適応できるように制御できないかと考え、信号機×AIを試してみたという内容になっています。
信号機をディープラーニングで制御してみる
信号機の制御をAI、特にディープラーニングに任せようと思っても、多くのディープラーニング系の手法のようにデータと正解ラベルのセットが用意できるわけではありません。そこで登場するのがロボットの制御やゲームなどによく使われている強化学習、特に深層強化学習という手法で、詳しい説明は過去記事に委ねますが、信号機をエージェント(操作するキャラクター)だと捉え深層強化学習の基本的なモデルである『DQN』を使って制御を行います。
DQN
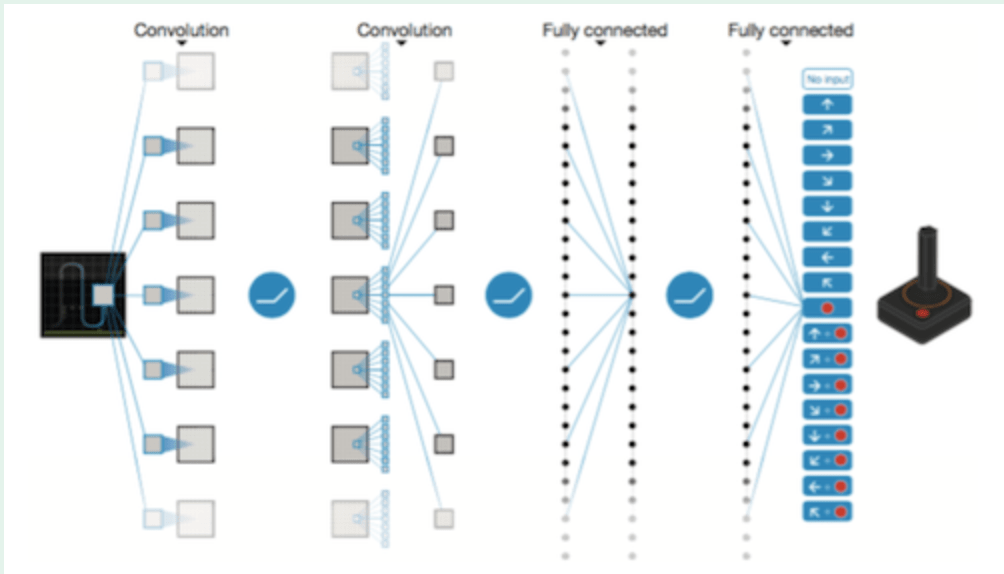
DQNは、例えばゲームに使うDQNであれば画像や映像を入力として受け取り次のコマンドを出力するようなAIとなっています。ゲームのスコアや勝敗などの報酬情報をもとに、あらゆるゲーム画面におけるあらゆるコマンドの良し悪しを記憶・修正するようにしてゲーム全体を通して上手にプレイできるようになります。
今回扱う信号機には、『交通状況』を入力とし『信号の色』を出力するようなDQNを使います。
交通状況を視覚的に捉えて画像として扱う
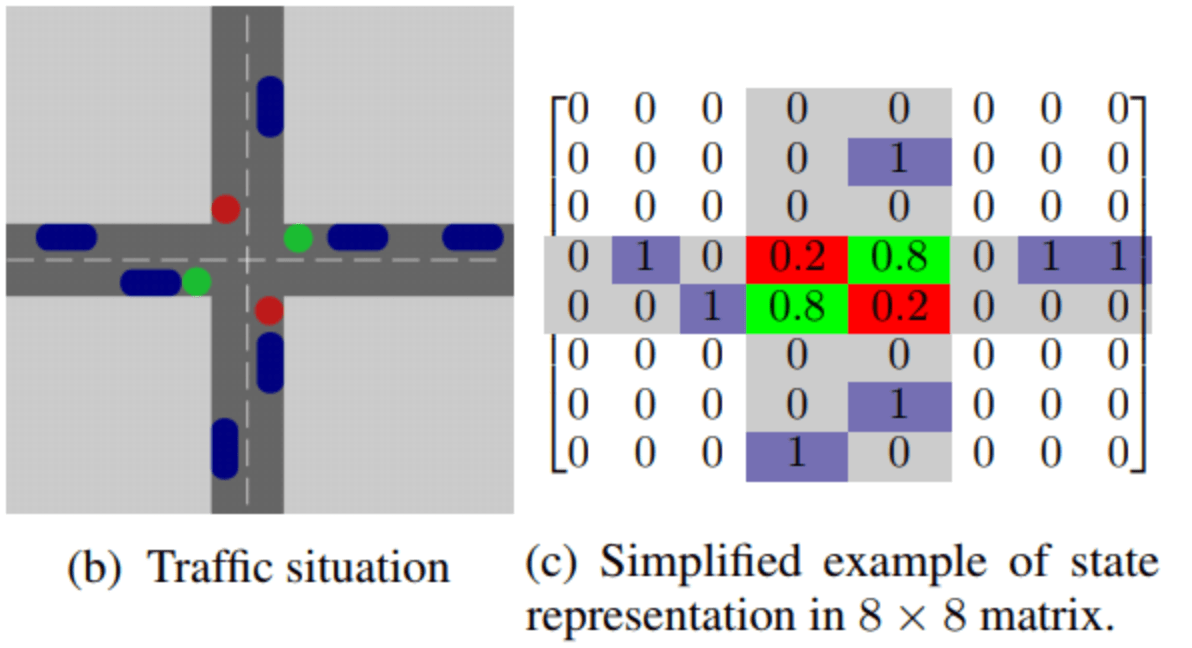
この提案手法では、交通状況を視覚的に捉えて画像として扱っています。
具体的には上から見ると図(b)のような交通状況があったとき、図(c)のように車がある場所を1, ない場所を0, 信号機の場所と色を0.2か0.8として表現しています。
少し信号機の表現に関しては無理矢理感がありますが、画像形式で扱うと車同士や車と信号機との位置関係などもわかりやすいので非常に合理的だと思われます。
報酬設計
強化学習では、エージェントはたまに貰える報酬を指標として学習していきます。例えば、ゲームAIであればゲームのスコアや勝敗を、ロボットであれば与えられたタスクができたか否か、あるいはどこまでできたかなどで報酬を決めて与えることができます。
では交通制御ではどのように報酬を設計すれば良いのでしょうか。
信号機の究極的な目標は『全自動車の移動時間の合計を最小化すること』と設定できそうですが、これを使ってそのまま報酬を定義してしまうと、どうしても信号機が『色を変える』という行動を起こしてから報酬が与えられるまでのタイムラグが大きくなりすぎてしまい、適切に学習が進まないことが容易に予想されます。
そこで論文では代わりにN台の車を追跡して得られた情報をもとに、各時刻における以下の値r_tを報酬(必ず負の数を取るので意味的にはペナルティ)として定義しています。
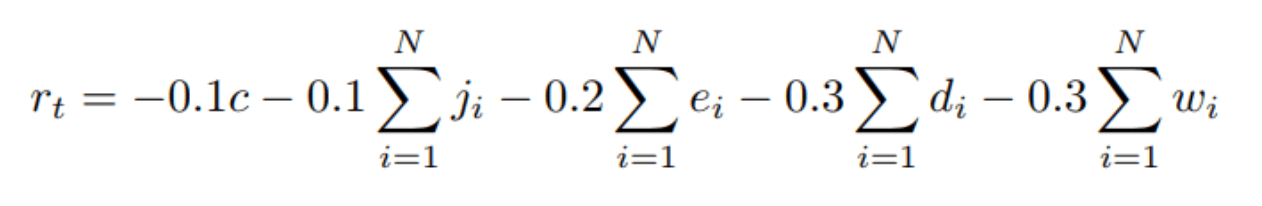
ここでd, w, e, j, cは車に関するペナルティで、dは『出せる速度と比較して何割減速しているか』、wは『信号待ち状態か否か』、eは『急ブレーキをかけているか否か』、jは『交通事故や渋滞に巻き込まれているか否か』、そしてcは信号機が急速に色を変えないためのペナルティー項で『色を変えたか否か』を意味します。
これでエージェント(信号機)は「さっき色を変えた結果こんなにペナルティが来てしまった、さっきの行動を改めよう」、という塩梅で学習をすすめることができます。
複数の信号機を一括で制御する
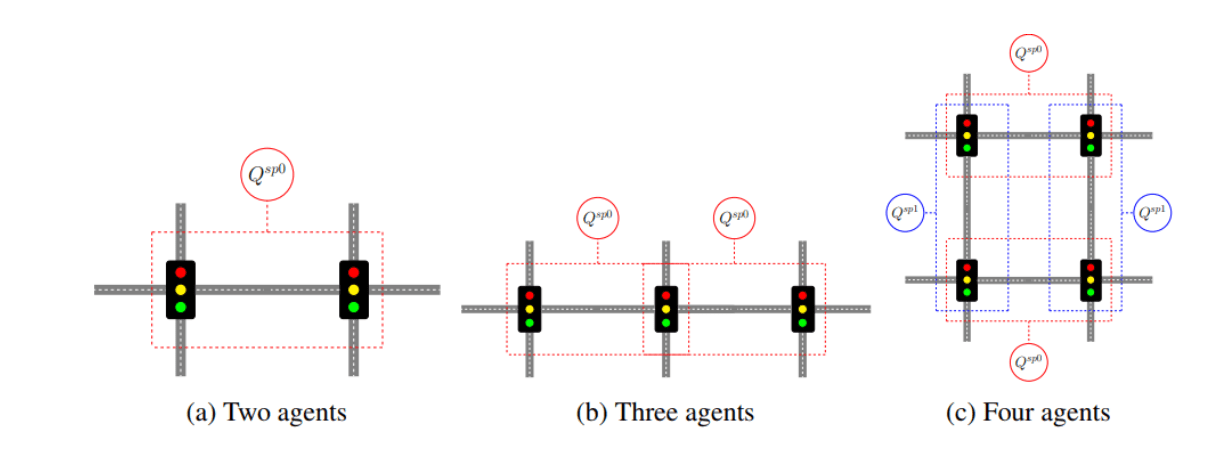
信号機一つが賢くなっても実際に車での移動時間が短くなったかどうかは実感できません。当然、複数台の信号機にDQNを用いたいですが、複数の信号機を最初から一気に学習させるのは一般的に困難です(ある信号機が学習している間に他の信号機が何かを学習して挙動を変えてしまうと、それでの学習が無駄になったり時に逆効果になるため)。また信号機が何台になろうと信号機が取るべき挙動は大きくは変わらないはずだろうとも考えられます。
そこで論文では転移学習と呼ばれる方法を用い、少ない交差点で学習させたエージェントを交差点数が多い信号機のエージェントにコピーし追学習させるようにして、安定して信号機AIを増やすことに成功しています。
実験
この分野にはディープラーニングを使わない先行研究があり、比較実験が行われています。ここでは平均移動時間を指標に比較しています。
右側のグラフのように、時刻0~500にかけてある程度の数の車が流入してきたあとDQNは安定して車を捌けていますが、時刻1500を過ぎたあたりから既存手法はDQNと比較して2~2.5倍もの移動時間がかかるようになってしまっています。
このようにディープラーニングを使った提案手法が優勢で、またDQNに発生しがちな不安定な挙動も特に観測されず問題なさそうでした。
実用化は期待されるが一方で課題も‥
信号機の制御にAIを活用する手法について紹介しました。最後の実験は『ディープラーニングによって渋滞が防げた』とも解釈でき、実用化がとても期待されます。一方、実際には、十字の交差点以外にも適応できるか、報酬計算用にどうやって自動車を追跡するか、そもそも各交差点にカメラを設置しなければならない‥などなどもう少し課題は残っていそうです。
ライター:東京大学 学生



この記事に関するカテゴリー






