畳み込みニューラルネットワークは形状のグローバル情報に対して鈍感であることが判明
UCLA認知心理学のチームは、CNNが物体を識別する方法は人間の視覚プロセスとは大きく異なるという興味深い研究を発表しています。論文では、CNNは局所的な特徴にはアクセスしている一方で、全体的形状に敏感ではない(グローバルオブジェクトの形状に基づいて分類されない)ことが示されています。
【参照】:Deep convolutional networks do not classify based on global object shape
画像認識タスクにおける形状情報の役割
畳み込みニューラルネットワーク(Convolutional Neural Network, 通称CNN)は、視覚野の特徴抽出の仕組みをモデル化したもので、画像解析において高い性能を発揮してきました。CNNは、何層にもわたって積み上げられたネットワークから構成されており、人間の手を介さずネットワークの学習を通して画像特徴量を自動抽出できます。
CNNは近年、オブジェクト認識タスクにおいてほぼ人間レベルのパフォーマンスを達成しています。それらのエラー率は、強力なハードウェアと、洗練されたエンジニアリングによって低下し続けており、現在、画像分類タスクではエラー率3%未満を記録しています。これは、同じタスクに対する人間のパフォーマンスよりもさらに低い数字です。しかしこれらのニューラルネットワークがどのようにして物事を「認識」し「分類」するのかについてよく理解されていませんでした。
本稿では、物体を認識するように訓練されたCNNにおける形状情報の役割をテストしています。これらの知見は、人工の視覚システムと生物学的な視覚プロセスとの間の重大な相違を示しています。

例えば、図(a)の場合、人間は画像がクマであるとすぐに区別できますが、CNNにとってこれをクマだと認識するのは難しい事です(速度と精度において)。一方、CNNは(b)の図であれば、熊だと簡単に見分ける事ができますが、人間がこれを見分けるのは難しいでしょう。
いくつかの関連研究では、対象の検出および認識タスクにおいて、CNNが全体的な形状に対して敏感ではない事が示されています。
Adversarial Examplesと呼ばれるタスクでは、物体の全体的な形状は変化していないにもかかわらず、1ピクセル変化させるだけで、CNNに誤認識させる事ができました。
別の研究では、進化的アルゴリズムを使用して、画像内にオブジェクト形状がまったく存在しないにもかかわらず、ネットワークに特定のオブジェクトとして高い信頼度で分類させるイメージを生成することに成功しています。これらは全体的な形状がCNNの認識においてあまり重要ではないことを示唆しています。
生物学的な視覚プロセスでは、形状は間違いなく認識のための最も重要な手がかりです。本稿では、オブジェクトの形状に焦点を当てこの問題を取り上げ、オブジェクトを認識するように訓練されたCNNにおける形状情報の役割をテストしました。
CNNはどのように分類するのか
これらの研究を実行するために、著者らは、2つの一般的に使用されているCNN(AlexNet とVGG-19 )をテストしました。
AlexNetは8つの層を持ち、オブジェクト認識のために革命を起こしたCNNです。VGG-19はさらに深く19層あり、オブジェクト分類における最先端のCNNです。ここでは、ネットワーク応答に対する形状情報の寄与を明らかにするために、体系的に修正されたさまざまな刺激を与え、それが分類にどう影響するかを調べています。
AIは輪郭に弱く、テクスチャ認識に優れている
最初の実験では、全体の形状(輪郭)は保存されているが、局所情報は失われているもの、あるいは、本来とは異なるテクスチャがオブジェクトのシルエットに重なっている画像を使用して、全体の形状とテクスチャ情報の相対的な重要性を調べました。

通常、訓練を受けたニューラルネットワークは、90%以上の分類精度でこれらの物体を識別することができます。
しかし、局所情報を失くしただけで、分類精度は10%まで減少しました。人間の場合はほとんど正しい形状ラベルを当てることができますが、ニューラルネットワークは画像の全体的な形状に対してほとんど鈍感です。

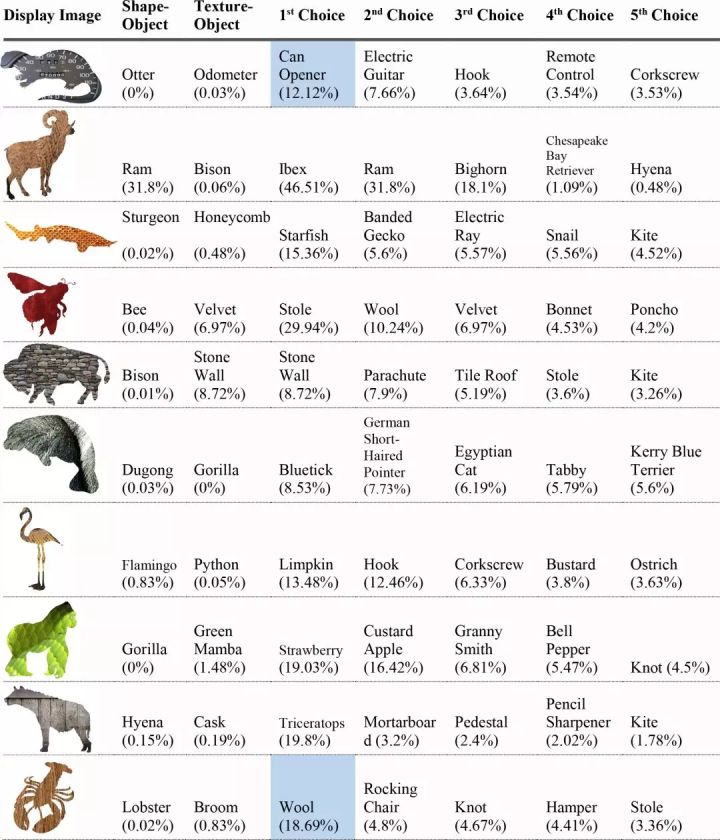
特に興味深い例は、ガラスの置物をCNNに分類させたときです。
CNNはImageNetと呼ばれる画像データベースを使用してオブジェクトを認識するように訓練されました。
しかし、どちらのネットワークもうまく機能せず、ガラスの置物を識別できませんでした。象の置物が、象として認識される可能性はほぼ0%。他にもVGG-19が「カワウソ」を「缶切り」に、「ホッキョクグマ」を「缶切り」を選択するなど、回答の大部分は困惑させるものばかりでした。
ニューラルネットワークはオブジェクトのテクスチャ情報に依存し、形状のみではオブジェクトをほとんど識別できないことがわかりました。
全体的な形状が消え、局所的な特徴は保持されている場合
最初の実験では、グローバルなオブジェクト形状ではなく、ローカルな輪郭の特徴に基づいている可能性が高いことを示しています。次の実験では、この仮説を検証し、全体的な特徴の変化がネットワーク分類のパフォーマンスに与える影響を比較しました。ここでは、ほとんどの局所的な曲率を維持しながら、全体的な形状が根本的に変化するように形状をスクランブルしています。
全体的な形が崩れると、人間の識別精度は著しく低下しましたが、CNNは通常の形と同じ分類ラベルを付けました。
人間はオブジェクトの37%しか分類できず、CNNが成功する確率は83%でした。人間が「本質的に認識できない」場合でも、CNNは高い精度で識別できることが分かりました。
CNNの多くの層は、脳神経細胞間の接続間で確立されたモデルに基づいていますが、しかし、この種の研究においては、全く異なる方法で機能することが示されています。
まとめ
人間の視覚において、形状の抽象的な認識は、オブジェクトのさまざまな部分が空間的にどのように相互に関連しているかを捉えることによって可能にしています。いくつかの研究では、人間の視覚が、局所的なノイズや局所的な要素の変動にもかかわらず、オブジェクトの要点を捉え、類似性の関係をサポートする抽象的な形状表現を生成することがわかっています。それらは、局所的な輪郭特徴の摂動に対してロバストです。
一方、CNNはオブジェクト認識のための優れた機能を持っていますが、人間とは異なり、表面の質感が形として認識するための強い手がかりのようです。これらの結果は、CNNは、地域の方向性とそれらの関係をつなぐ形の特徴にはアクセスしていますが、全体的形状に敏感ではないことを示しています。
【関連】ディープニューラルネットワークを欺くための1ピクセル攻撃



この記事に関するカテゴリー






