U-Netをグラフで扱えるようにしたGraph U-Netが登場
Graph Neural Network(GCN)でU-Netを扱えるようにしたGraph U-Netsが提案されました。畳み込みに加えてU-NETに不可欠な、プーリング/アップサンプリングの操作をグラフ上でも行えるようにいくつかの工夫がされています。
論文:GRAPH U-NET
U-Netとは
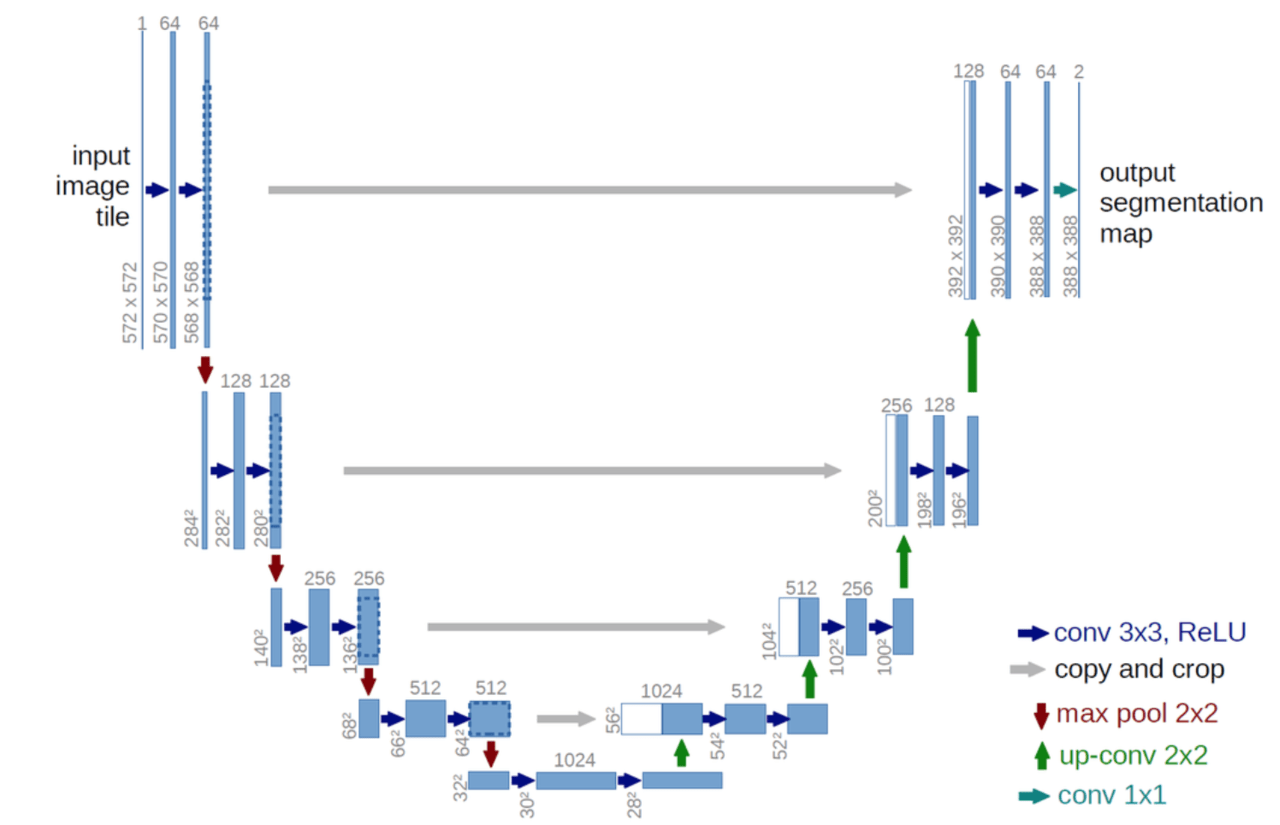
U-NETはセグメンテーションのタスクにおいて高成績を残しています。図に示すように、U字型のネットワークになっていることから名付けられました。
通常のCNNによって行われる画像のクラス分類(画像認識)では、畳み込み層が物体の局所的な特徴を抽出する役割を担い、プーリング層が物体の全体的な位置情報をぼかす(位置ズレの許容)役割を担っています。そのため、深くなればなるほど、抽出される特徴はより局所的になりますが、プーリング層のおかげで、物体の位置ズレや大きさの違いの影響をあまり受けない頑強なパターン認識が可能になっているわけです。
一方、セグメンテーションでは、「物体の局所的特徴と全体的位置情報」の両方が必要になってきます。つまり、プーリング層でぼかされた局所的特徴の位置情報をpixel単位で正確に復元する必要があります。
そこで、「物体の局所的特徴と全体的位置情報」の両方を統合して学習させるために開発されたのがU-Netです。
U-NETの主なアイデアは、プール操作がアップサンプリング演算子に置き換えられることです。アップサンプリング部分に多数の機能チャネルがあり、このアップサンプリングを行うことで、ネットワークはコンテキスト情報を高解消度レイヤに伝播することができ(次元をあげることができ)、位置情報を保持することができるのです。
U NETは特にPixel単位の予測に有用だと言われており、特に、医療系のセグメンテーションにおいて高い成果を出しています。(医療系の画像は、画像の境界線がはっきりとしていなければいけないという条件があるため)
GCN
一方、存在するデータの多くは、グラフとして自然に表現できます。物性予測などの化学系のデータや、顧客の購買データ、インターネットまでもグラフとして表現できます。さらに、画像やテキストなどの従来からDeep Learningで取り扱われてきた対象も、グラフ構造として扱うことができます。近年のCNNの成功もあり、畳み込みをグラフデータ(GNN)に拡張する多くの試みがありました。グラフ上の畳み込みの一般的な用途の1つは、ノード表現を計算することです 。学習したノード表現を使用してさまざまなタスクを実行できます。
このようなグラフ上でU-Netも扱えるようにするというのが今回の提案となっています。しかし、U-NETでは、畳み込み演算に加えて、プーリング/アップサンプリング(アンプーリング)の操作が不可欠な構成要素です。一方、グラフ内のノードには、通常のプール操作で必要とされる空間的局所性や順序情報がなく、これらの操作をグラフデータに拡張することは非常に難しいと考えられていました。
この論文では新しいグラフプーリング(Graph Pooling)とグラフアンプーリング(Graph Unpooling)操作を提案しています。これら二つの操作に基づいて、U-Netをグラフデータで扱えるようにしたというのが今回の論文の内容です。
Graph U-Nets
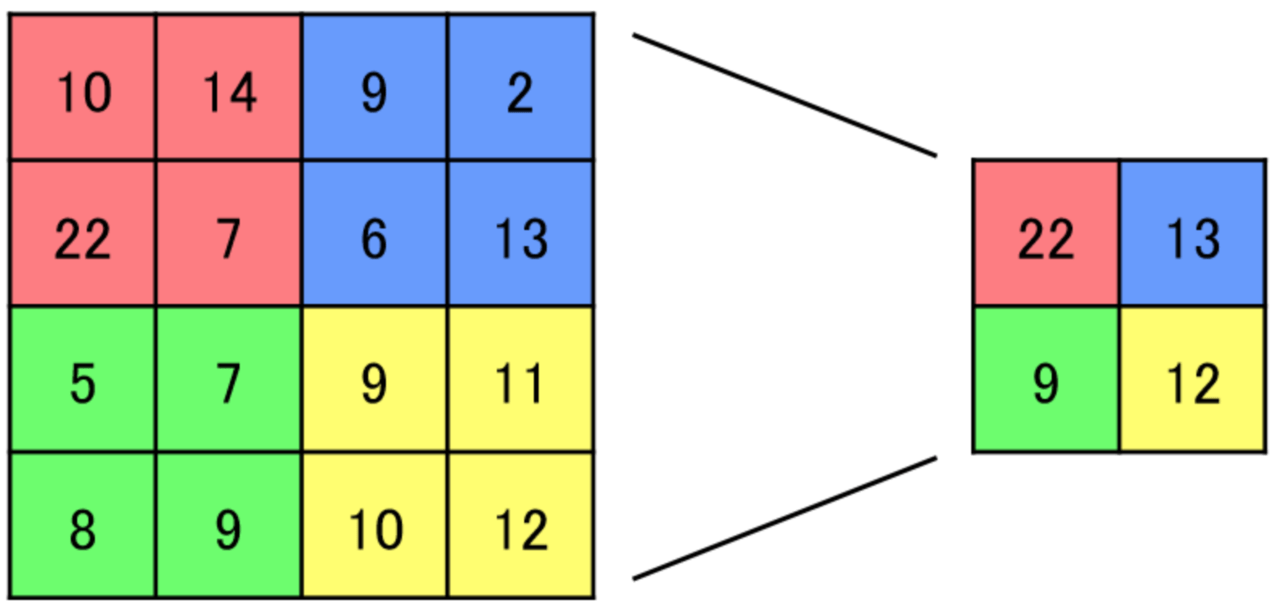
プーリングは、いくつかの特徴があるものを、(例えば上の例では)大きく4分割した時に最も特徴を表わしている特徴を抜き出してをサンプリングすることです。
ここでの目標はプーリングをグラフデータでも行えるようにすることでした。つまり、グラフから情報量の多いノードをサンプリングして新しい部分集合を得ることを目標とします(すなわちグラフプーリング)。
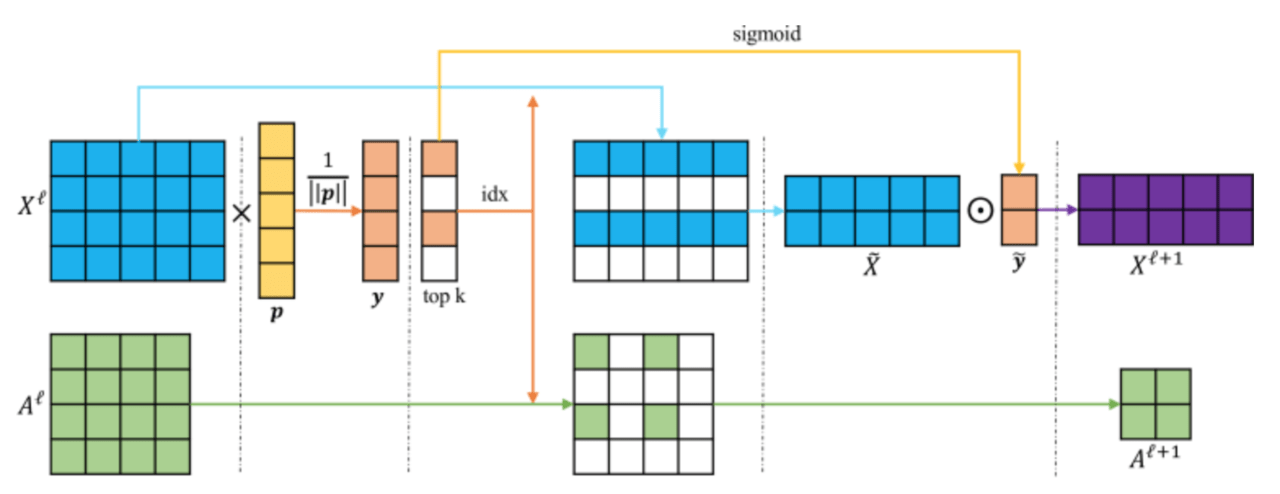
これらを実現するために、ノード特徴行列から値の大きいノードを選択し、学習パラメータpを用いて新たなグラフを部分集合として取り出す方法をグラフプーリング(gPooling以下gPool)として定義します。そして、gPoolの逆操作として、対応するgPoolレイヤで選択されたノードの位置を利用して、選択されてないノードに対して空の特徴ベクトルを使用することによって、対応するグラフのプール解除(gUnpooling)操作を行いグラフを元の構造に復元します。この新しいPooling、Unpoolingの定義を、GCNと組み合わせてGraph-U-Netを作っています。
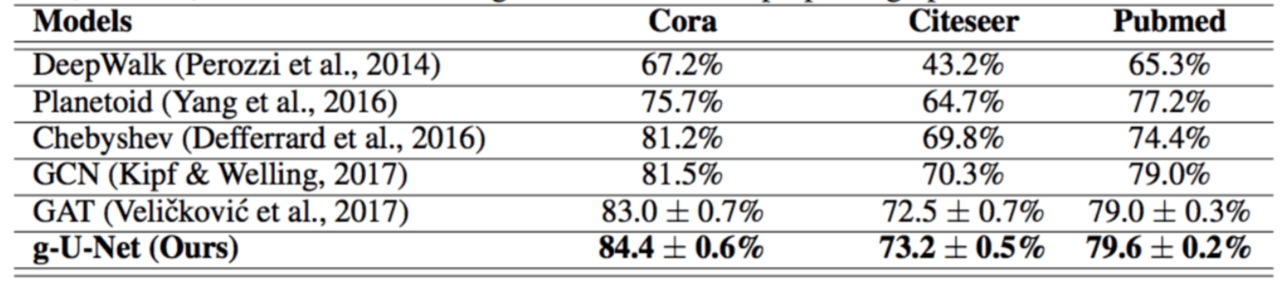
実験では、ノード分類とグラフ分類のタスクに関して、提案したモデルを以前の最先端モデルと比較しています。Graph U-Netsは他のネットワークよりも一貫して優れたパフォーマンスを達成しています。
以下は Cora、Citeseer、Pubmedの各データセットのノード分類精度に関する結果です。
こちらは、D&D、PROTEINS、COLLABデータセットのグラフ分類精度に関する結果です。




この記事に関するカテゴリー






