1枚の写真からリアルな会話アニメーションが作成できる!メタラーニングを用いたfew-shot学習
【論文】Few-Shot Adversarial Learning of Realistic Neural Talking Head Models
モスクワにあるサムスンのAIセンターとSkolkovo科学技術大学が、3Dモデリングのような方法なしで画像から人が話している様子などのリアルなアニメーションを生成するモデルを発表しました。
人の顔のたった一枚のフレームから本物そっくりの動きを再現できるシステムを作り出し、写真だけでなく絵画もアニメーション化することも可能です。
こちらはこの技術に有名なモナリザの静止画を適用したものです

他にも、以下の動画では、普段静止画像でよく見られるような、マリリン・モンロー、アインシュタイン、ダリなどの有名な顔も含まれています。
これは、ソースフェース上の顔のランドマークをターゲットフェースのデータに適用し、ターゲットフェースにソースフェースの動作を行わせる技術です。人が話している表情や視点(トーキングヘッド)を別の顔に反映させることができます。
例えば以下の場合、8枚の画像をモデルに学習させ、会話映像の元となるムービーを入力すると、元ムービーから眉・目・鼻・口・顎のラインだけで構成されたフレームを抽出し、学習した画像にフレームの動きを合わせることで「全く新しい会話映像」を生成されます。
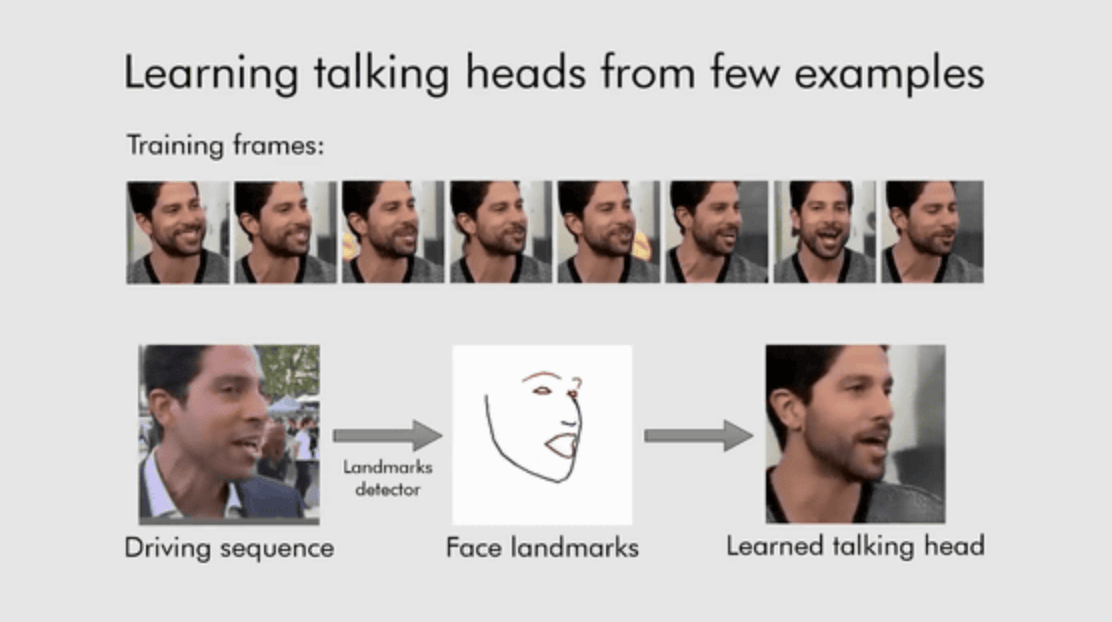
しかし、これ自体は新しいものではなく、さらに、これらのモデルのほとんどは訓練するのにかなりの量のデータと時間を必要とします。
新しい点としては、限られたトレーニング時間で、一握りの写真からトーキングヘッドモデルを作成するシステム(いわゆるfew shot学習)を採用していることです。たった1枚の写真(あるいは複数)に基づいて合理的な結果を生み出すことができるといものです。
メタラーニングを用いたfew shot学習
Few shotの学習能力は、多様な外観を持つ人がさまざまに話しているトーキングヘッドビデオ(VoxCeleb2データセット)を用いた事前トレーニング(メタラーニング)を通じて得られます。このメタラーニングの過程において、システムはfew−shot学習タスクを模擬し、顔のlandmark位置をリアルなパーソナライゼーション写真に変換することを学習します。
その後、Few shot学習を、メタラーニングを介して事前に訓練された大容量の生成器/弁別器を用いた敵対的学習として組み立てます。
メタ学習プロセス
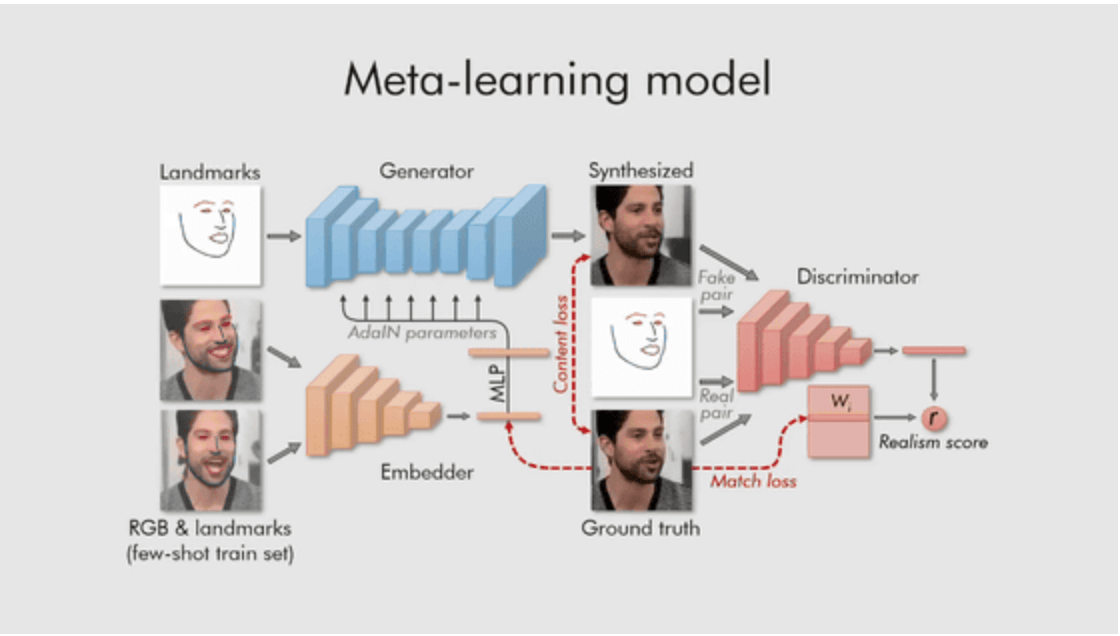
上記のように、メタラーニングの最初のステップでは、ビデオフレームと対応するランドマーク画像を埋め込みネットワーク(Embedder)を通して埋め込みベクトルに変換します 。この埋め込みベクトルを平均して対応するジェネレータの適応パラメータを予測します。更新されたパラメータを有する生成器が、畳み込みレイヤを介して顔のランドマークを出力フレームにマッピングします。
その後、異なるフレームのランドマークをジェネレータに入力し、注釈付き画像と生成された画像の違いを識別器で比較します。
Few shot学習プロセス
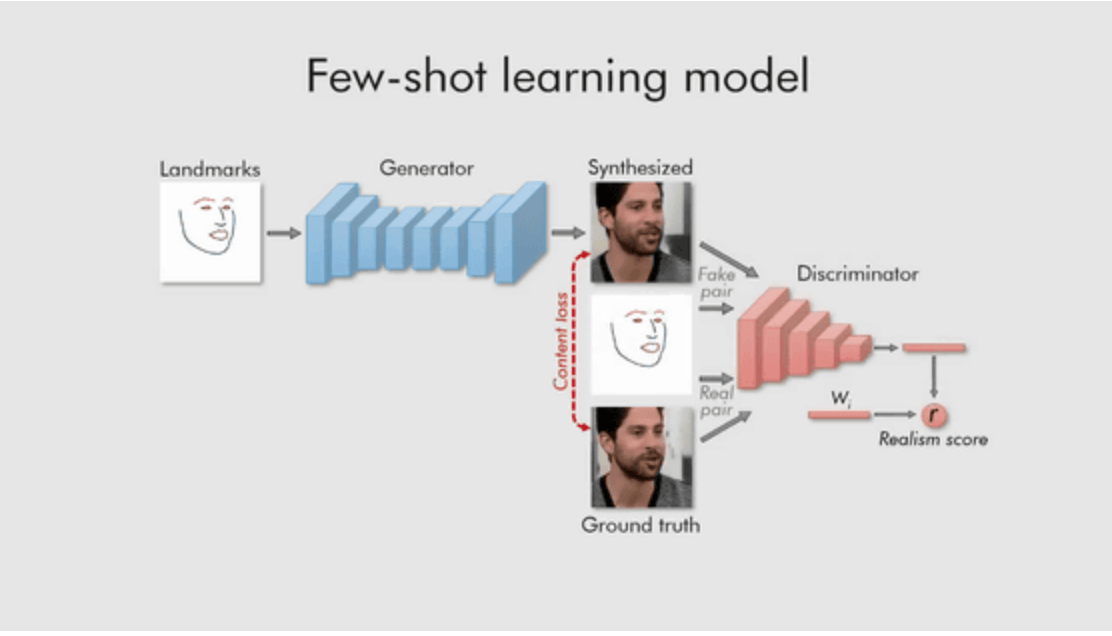
メタラーニングを終えると、数枚あるいはたった1枚の画像に基づいて数千万のパラメータを調整し、スピーディーにGANを訓練することができます(ターゲット面を埋め込みに投影し、ターゲット固有のパラメータを更新するだけ)。新しいターゲットの画像サンプルを与えると、新たな画像の特徴系列をどのように合成するかをシステムは簡単に学習します。
つまり、トーキングヘッドビデオ生成の構造は、「ランドマーク」、つまり鼻、目、唇、頭が特定のショットのどこを向いているかの明示的なパラメータ化の概念に基づいています。モデルは、メタラーニングで特定の人物のフレームを特定のポーズで生成できるように訓練されているため、新しい画像のシーケンスの埋め込みベクトルを見積もることができるのです。
数枚の画像さえあれば、顔パーツのフレームに合わせたスムーズな会話アニメーションが生成できるので、自撮りから取得したフレームを元に新しい会話アニメーションを生成するということも可能になります。
もちろん、1枚より10枚、20枚‥と訓練データを増やせば増やすほど、アニメーションの動きは正確になるといえますが、ムービーを見ていると、その動きにあまり大きな違いはなく、1枚からでもかなり自然な会話アニメーションを生成できています。
写実的な顔のイメージと顔のランドマークの合成に焦点を当てた技術は、ビデオゲーム、ビデオ会議、またはデジタルアバターに適用することができそうです。



この記事に関するカテゴリー






