AIによる歌声合成はここまで来た!これこそ世界に誇るべき日本の先端技術
論文 Singing voice synthesis based on convolutional neural networks
はじめに、歌声合成の最先端と聞いて、「ああ、昔なんかで聞いたあの人間っぽい声ね」という感想を持たれ方に、著者からお願いがございます。ページをそっ閉じする前に、下記URLを開いて、合成音声サンプルをお聞きください。
AI技術により超高精度な歌声合成を実現
~バーチャルシンガーの歌声は人と区別できない時代へ~
今回取り上げるのは、音声インタラクションシステム構築ツールキット MMDAgent をはじめとした関連ソフトウェア(HMM 音声合成ツールキット HTS、日本語音声合成システム Open JTalk、歌声合成システム Sinsy、音声信号処理ツールキット SPTKなど)を世に送り出した名古屋工業大学(以下、名工大)と、その名工大発のベンチャー企業「株式会社テクノスピーチ」の面々による英語論文です。
名工大とテクノスピーチと言えば、下記の記事にも紹介されている通り、最近ではAI歌声合成をボーカルに起用した世界初のCDがリリースされるなど、話題に事欠かない印象を持ちます。
AI歌声合成をボーカルに起用した世界初のCDをリリース。歌声合成技術が人間を超える日は来るのか!?
さて、この論文は統計モデルに基づく歌声合成を扱いますが、歌声における時間変動のモデル化には長い歴史があります。論文に頻出する静的特徴量(static features)や動的特徴量(dynamic features)といったキーワードを正しく理解するために、日本語で書かれた過去の文献も参照されることを強くお勧めします。特に最終著者である徳田先生が書かれた、情報処理学会『情報処理 45』の特集記事である、『音声情報処理技術の最先端:1.隠れマルコフモデルによる音声認識と音声合成』は、図解も豊富で非常にわかりやすくお勧めです。
今回紹介する論文では、楽譜特徴量(musical score feature sequences)から音響特徴量(acoustic feature sequences)を、畳み込みニューラルネットワーク(Convolutional Neural Network; CNN)を用いてセグメント単位で変換する手法を提案しています。
提案手法
学習パートでは歌声から求めた音響特徴量として、メルケプストラム係数(mel-cepstral coefficients)などのスペクトル(spectrum)パラメータ、基本周波数(F0 frequency)などの励振(excitation)パラメータ、音高や音量を周期的に揺らす歌唱表現であるビブラート(vibrato)を用います。
また、楽譜や歌詞から求めた楽譜特徴量として音素(phonetic)や音符(note key)、ノート長(note length)が挙げられます。学習の際は、歌声の対数基本周波数と楽譜情報における音符の音高との差分を音高正規化(Pitch normalization)という手法でモデル化します。これにより、合成したい曲のテンポやリズムを忠実に再現した歌声合成が可能になります。
推論すなわち合成パートでは、合成したい曲の楽譜から抽出した特徴量を訓練済みのニューラルネットに与えることで、音響特徴量を推定します。このとき従来手法では、静的および動的特徴量の関係を考慮したパラメータ生成(maximum likelihood parameter generation; MLPG)アルゴリズムを用いることで、より滑らかな音響特徴量系列を求めていましたが、計算が重いという課題がありました。
一方提案手法では、MLPGを用いることなく、高速かつ滑らかなパラメータ生成に成功しています。最後に、生成された特徴量をボコーダ(Vocoder)へ入力することで、新たな歌声を合成することができるという仕組みです。図1が歌声合成システムの全体像となります。
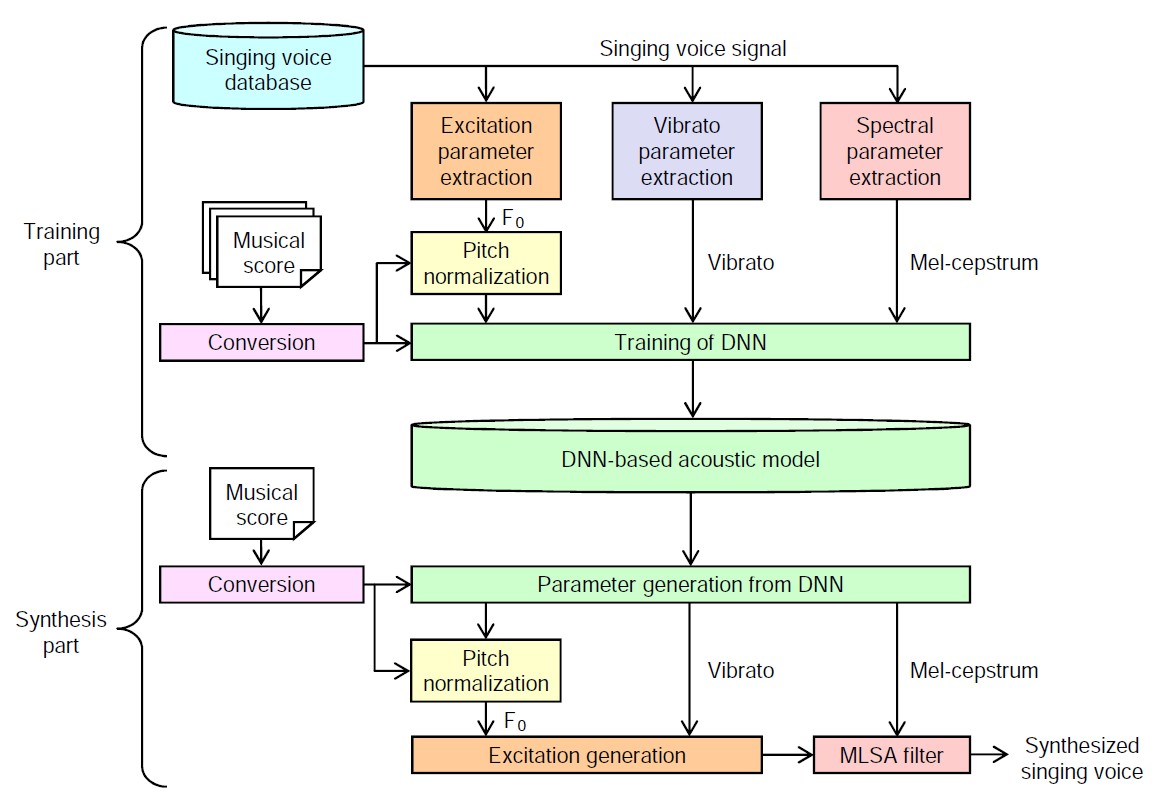
図1 歌声合成システムの全体像
次にニューラルネットの構成です。最初に楽譜特徴量を、ドロップアウトを適用したFFNN(Feed-Forward NN)によりフレーム単位で変換します。これは1×1の畳み込みと等価です。次にFFNN の出力を1×Tのセグメント(segment)としてCNNに入力し、音響特徴量系列に変換します。ここで、CNNの出力チャンネル数は音響特徴量の次元数に対応しており、Tは1度に変換するフレーム数を表します。CNNは全層畳み込みネットワーク(Fully Convolutional Network; FCN)を用いるため、Tは調整可能です。図2がニューラルネットの全体像となります。
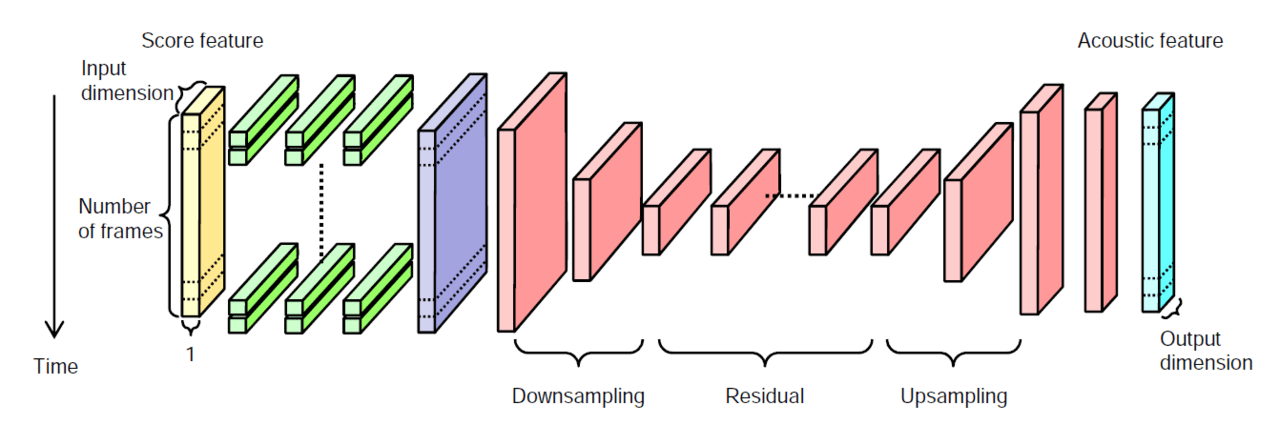
図2 ニューラルネットの全体像
評価
続いて評価です。学習用の歌声データベースとして女性1名による童謡 55曲とJ-POP 55 曲を使用し、テストデータは学習データに含まれていないJ-POP 5曲を用いてます。サンプリング周波数は48kHz、16bit量子化、フレーム周期は5msです。
また前段のFFNNは隠れ層として2048ユニットの3層を用い、ドロップアウトを比率0.2で適用しました。後段のCNNは2層のdown-sampling層,9層のresidual層,2層のup-sampling層で構成し、2000フレームを1つのセグメントとして学習および推論し、推論時は両端100フレームをクロスフェードしています。
隠れ層の活性化関数はReLUを用いてます。主観評価実験における被験者は15人。各被験者はテストデータ5曲からランダムに選択された各手法10フレーズずつを5段階評価したところ、MLPG を用いた従来手法よりも提案手法の方が高評価でした。
また対数メル周波数ケプストラム近似(mel log spectrum approximation; MLSA)フィルタによるボコーダとWaveNetボコーダによる音声波形生成の比較では、WaveNetの方が高評価でした。
以上、歌声合成の最先端技術について触れさせていただきました。技術の進展には驚くばかりですが、一方で同じ人が同じ歌詞を何回歌ったとしても決して同じ音声にはならないように、リテイクなしで意図通りに歌わせることの難しさが、リンク先のDTMステーションさんの取材記事から伺えます。ではその意図をどうやって表現するか?それを実現できる「楽譜や歌詞の枠を超えた何か」こそが、本格的な歌声合成実用化への鍵になるだろうなと著者は予想します。




この記事に関するカテゴリー






