
V3D:画像一枚から3次元物体生成
3つの要点
✔️ 自動3D生成は最近広く注目を集めており、最新の手法は生成速度を大幅に向上させていますが、モデルの容量や3Dデータの制限により、詳細に欠ける物体が生成されるという課題があります
✔️ V3Dは、幾何学的一貫性と多視点の一貫性を学習に組み込み、映像拡散モデルを活用することで、この課題の解決を目指しています
✔️ 広範な実験によって、提案されたアプローチの優れた性能が実証されました。特に、生成品質と多視点の一貫性において優れた成果を示しています
V3D: Video Diffusion Models are Effective 3D Generators
written by Zilong Chen, Yikai Wang, Feng Wang, Zhengyi Wang, Huaping Liu
(Submitted on 11 Mar 2024)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本記事で使用している画像は論文中のもの、紹介スライドのもの、またはそれを参考に作成したものを使用しております。
はじめに
AIの最近の進歩により、3Dコンテンツを自動的に生成する技術が可能になりました。この分野では大きな改善が見られていますが、現行の手法にはまだいくつかの課題があります。一部のアプローチは遅く、一貫性のない結果を生成することがあり、また他の手法では大規模な3Dデータセットでのトレーニングが必要となり、高品質な画像データの使用が制限されています。
今回の解説論文では、ビデオ拡散モデルを用いた3Dコンテンツの生成に焦点を当てています。ビデオ拡散モデルは、詳細で一貫性のあるビデオシーンを生成する代表的なモデルです。多くのビデオは自然に物体を様々な角度から捉えているため、これらのモデルが3D世界の理解に役立ちます。
この論文では、V3Dと呼ばれる新しい手法を提案しています。V3Dは、ビデオ拡散モデルを用いて物体やシーンの複数の視点を生成し、それらの視点を基に3Dデータを再構築するものです。このアプローチは、個々の物体と大規模なシーンの両方に適用可能です。
3D物体の生成においては、360度回転する3Dオブジェクトのビデオを使ってモデルを訓練し、精度を向上させています。また、生成された視点の一貫性と品質を高めるための新しい損失やモデル構造も導入しています。
さらに、この手法を実世界で実用的にするため、生成されたデータから3Dメッシュを作成する方法も提案しています。また、シーンレベルの3D生成にも対応できるように拡張し、正確なカメラパスの制御や複数の入力視点の処理を可能にしました。
定性評価や定量評価を含む広範な実験により、提案されたアプローチの優れた性能が実証されました。特に生成品質と多視点の一貫性において、先行研究を大きく上回っています。提案手法により、現在の3D生成技術の限界を克服し、AIによる3Dコンテンツ生成の新たな可能性が切り開かれることが期待されています。
提案手法
概要
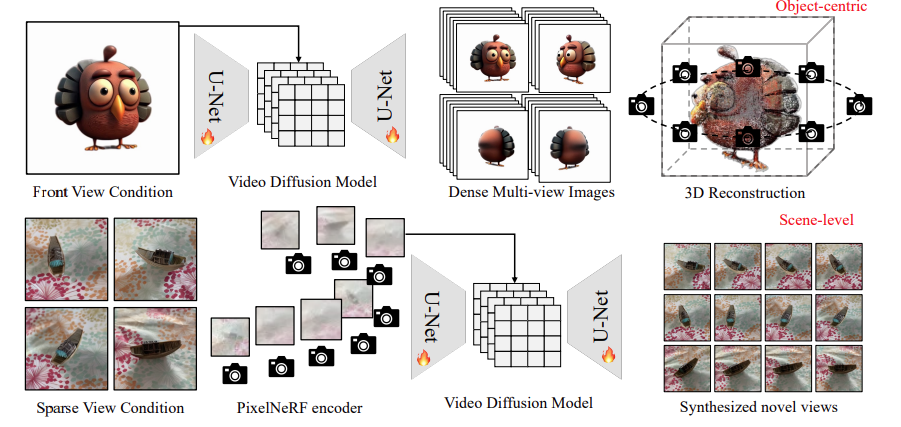
図1に示すように、V3Dでは動画生成モデルを活用することで、大規模な事前学習済みの動画拡散モデルの構造と強力な事前知識を活用し、一貫性のある多視点生成が促進されます。
物体の画像から3D生成を行う場合、ベースの動画拡散モデルを固定円形カメラ位置で描画された合成3D物体の360度軌道動画でファインチューニングし、生成された多視点に適した再構成とメッシュ抽出パイプラインを提案します。
シーンレベルの3D生成では、ベースの動画拡散モデルにPixelNeRFエンコーダーを組み込み、生成されるフレームのカメラ位置を正確に制御することで、任意の数の入力画像にシームレスに適応できるようにします。詳細は以下の通りです。
ターゲット物体の画像から360度ビュー生成
V3Dは、単一視点から多視点画像を生成するために、物体周囲を回転する連続的な多視点画像を動画として解釈し、正面視を条件にした多視点生成を画像から動画への生成の一形態として扱います。このアプローチにより、大規模な事前学習済みの動画拡散モデルが提供する3D世界の包括的な理解を活用し、3Dデータの不足に対処します。また、動画拡散モデルの固有のネットワークアーキテクチャを利用して、十分な数の多視点画像を効果的に生成します。
具体的には、Objaverseデータセットで、動画生成の代表的なモデルであるStable Video Diffusion (SVD, Blattmann et.al, 2023)をファインチューニングしました。画像から3Dへの適応を高めるために、モーションバケットIDやFPS IDといった無関係な条件を削除し、高度角に依存しないようにしました。代わりに、オブジェクトをランダムに回転させることで、高度がゼロでない入力に対しても生成モデルが対応できるようにしました。
頑健な3D再構成とメッシュ抽出
・3D再構成
ファインチューニングされたビデオ拡散モデルを使って物体周囲の画像を取得した後、次のステップはそれを3Dモデルに再構築します。このタスクには、3D Gaussian Splatting(Kerbl et.al, 2023)が利用されます。
ビュー間のピクセルごとの一貫性を確保するのは難しく、3D再構築にアーティファクトが発生しやすいです。この問題を解決するために、MSEのピクセル単位の損失を利用します。さらに、MSEによるフローティングやぼやけたテクスチャを防ぐために、画像レベルの知覚損失と類似度の損失も導入されます。最終損失は以下のように定義されます。

・メッシュ抽出
実世界のアプリケーションの要求に応えるために、生成されたビューのメッシュ抽出パイプラインも提案します。高速な表面再構築のために、マルチ解像度ハッシュグリッドを使用したNeuS(Wang etl.al, 2021)が採用されます。V3Dは通常のNeuSの使用ケースよりも少ないビューを生成するため、ノーマルスムース損失とスパース正則化損失を適用してジオメトリを改善します。
一貫性のない生成画像から生じるぼやけたテクスチャを改善するために、LPIPS損失を使用して生成されたマルチビューでテクスチャを精緻化し、ジオメトリは変更せずに維持します。このプロセスは効率的な微分可能なメッシュレンダリングにより15秒以内に完了し、最終出力の品質を向上させます。
シーンレベルの3D生成への拡張
オブジェクトのビュー生成とは異なり、シーンレベルの3D生成では、カメラの経路に沿って画像を生成する必要があり、カメラの姿勢を正確に制御し、複数の入力画像に対応する必要があります。
V3Dはこの課題を解決して、一貫性を維持するために、図1の下部のように、PixelNeRF特徴エンコーダーを動画拡散モデルに統合します。PixelNeRFで抽出した特徴マップをU-Netの入力に連結して、相対的なカメラポーズ情報を明示的にエンコードします。
このアプローチにより、任意の数の画像をシームレスにサポートできます。モデルの他の設定やアーキテクチャは、オブジェクト中心の生成と同様です。
実験
オブジェクト中心の3D生成

本節では、提案されたV3Dの性能を画像から3Dへの変換で評価し、他の手法との比較結果を説明します。図2の上部では、V3Dが3DGSベースのTriplaneGaussianやLGMよりも優れた品質を示しています。これらの手法は生成するガウスの数が限られているため、ぼやけた外観になります。
図2の下部では、V3Dが最新のSDSベースのMagic123やImageDreamよりも前面ビューの一貫性と忠実度で優れており、Magic123はジオメトリが不正確で背面がぼやけ、ImageDreamは過剰に飽和したテクスチャを生成します。提案手法は3分以内で結果を達成し、最適化ベースの手法よりも大幅に高速です。
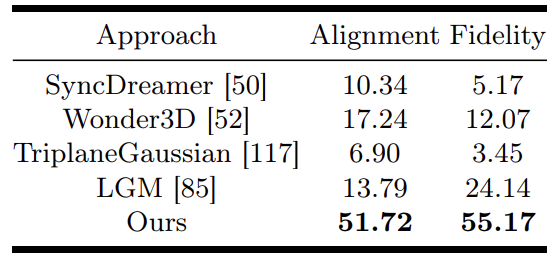
一方で、生成された3D物体について人間による評価調査を実施しました。具体的には、58人のボランティアに対して、V3Dや他の手法で生成されたオブジェクトを、30枚の条件画像に基づいてレンダリングされた360°スパイラル動画を見ながら評価してもらいました。評価基準は次の2つです:
- (a)一貫性:3Dアセットが条件画像とどれだけ一致しているか
- (b)忠実度:生成されたオブジェクトがどれだけ現実的か。
表1には、各手法のこれら2つの基準における勝率が示されています。
V3Dは全体的に最も説得力のあるモデルと評価され、画像の一貫性と忠実度の両方で他の競合手法を大幅に上回っています。
シーンレベルの3D生成
シーンレベルの3D生成において、提案されたV3Dの性能をCO3Dデータセットの10カテゴリサブセットでテストしました。先行研究と同じ設定に合わせるため、各カテゴリのビデオでV3Dを1エポックのみファインチューニングしました。
結果は表2に示されています。
提案手法は、先行研究と比較して画像メトリックの点で一貫して優れた性能を発揮し、事前にトレーニングされたビデオ拡散モデルをシーンレベルの3D生成に利用する効果を示しています。また、V3Dのゼロショットバージョン(MVImgNetでのみトレーニングされた)も、ほとんどの先行研究を上回り、高い性能を示しています。
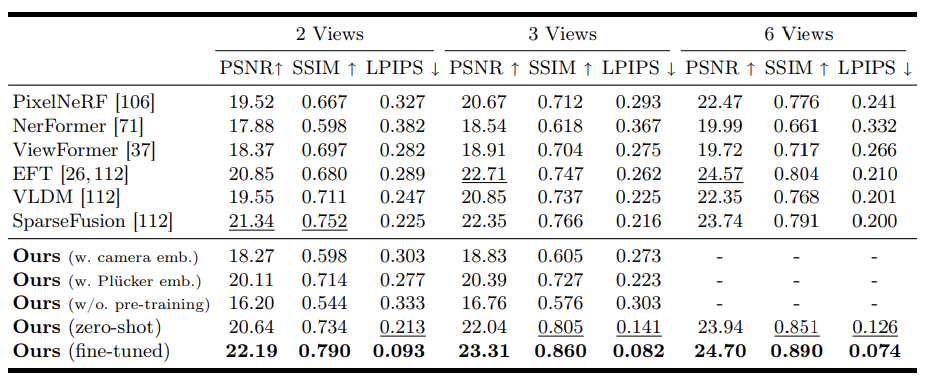
図3では、CO3Dデータセットの消火栓サブセットにおけるSparseFusionとV3Dによる生成マルチビューの定性的比較を示しています。比較をより詳細に行うために、カメラポーズを用いてCOLMAPでマルチビュー立体再構築を行い、図3には得られた点群の点の数と、実画像から再構築された点群とのChamfer距離を示しています。
V3Dで生成された画像から再構築された点群は、より多くの点を含み、実画像から再構築された点群に近いことが示されています。つまり、再構築品質とマルチビューの一貫性の両方において、提案手法の大きな利点が示されています。

結論
本記事では、画像1枚から3次元物体を生成するV3Dを紹介しました。
V3Dは、動画生成モデルを活用し、大規模な事前学習済みの動画拡散モデルの構造と豊富な事前知識を活用し、一貫性のある多視点生成を実現します。また、一貫性を保ちつつ高精度な3次元物体の再構築を達成するために、新たに再構築パイプラインと学習損失も提案しました。
広範な定性評価、定量評価、および人間による評価を通じて、提案したアプローチの優れた性能が実証されました。特に生成品質と多視点の一貫性においては、先行研究を大きく上回っています。提案手法により、現行の3D生成技術の限界を突破し、AIによる3Dコンテンツ生成の新たな可能性が広がることが期待されています。



この記事に関するカテゴリー





