
从文本中生成3D对象 - DreamFusion
三个要点
✔️ DreamFusion,仅使用预先训练好的文本-图像模型(Imagen)从文本中生成3D物体
✔️ Score Distillation Sampling(SDS),通过优化损失函数实现从扩散模型中取样。DistillationSampling)
✔️ 将提议的SDS与专门用于3D生成任务的NeRF相结合,可以为各种文本生成高保真的3D对象和场景。
DreamFusion: Text-to-3D using 2D Diffusion
written by Ben Poole, Ajay Jain, Jonathan T. Barron, Ben Mildenhall
(Submitted on 29 Sep 2022)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG); Machine Learning (stat.ML).
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
近年来,许多数字媒体,如游戏、电影和模拟器需要成千上万的3D数据。 然而,3D资产是使用建模软件手动设计的,这需要大量的时间和专业知识。
解决这些问题的主要方法包括GAN和NeRF,它们专门生成特定的对象,如人脸,但不支持文本。 NeRF也支持文本,但缺乏真实性和准确性。
本文介绍的DreamFusion旨在降低数字媒体初学者的入门门槛,通过从文本生成3D对象,同时改善老手的工作流程。

摘要
DreamFusion将专门从事3D生成任务的NeRF与一种新提出的方法--得分蒸馏采样(SDS)相结合,生成3D物体。
NeRF经过优化,可以恢复特定场景的形状,并能从未观察到的角度合成该场景的新视图。因此,它已被纳入许多三维生成任务中。然而,从预先训练好的二维文本到图像模型生成的三维物体往往缺乏真实性和准确性。
为了解决这个问题,作者提出了得分蒸馏抽样法(SDS),它通过优化损失函数来实现从扩散模型中抽样。DreamFusion是通过将这种新提出的SDS与专门从事3D生成任务的NeRF相结合而实现的。
SDS(得分蒸馏取样)
SDS是本研究中DreamFusion的核心,它利用扩散模型的结构,通过优化提供可操作的取样,从而使损失函数最小化,得到一个样本。
所用的扩散模型对雅各布项的计算是很昂贵的,因为它们需要反向传播。它也被训练成近似于边际密度的缩放Hessian,这对于小的噪声水平是不够的。
因此,我们发现,省略扩散模型中的雅各布项,可以为使用扩散模型优化DIP提供一个有效的梯度,我们通过以下公式实现了这一点。
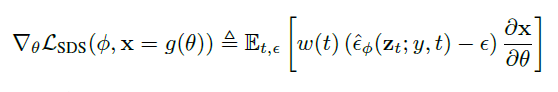
对参数θ进行优化,其中θ是三维体积参数,g是体积渲染器,这样x = g(θ)看起来就像冻结扩散模型的样本。这里的梯度是概率密度蒸馏损失的梯度,由从扩散模型学到的评分函数加权。
这种取样方法被命名为SDS(评分蒸馏取样)。这就创造了一个3D模型,从随机角度渲染时看起来就像一个好的图像。
梦想融合
用于DreamFusion的扩散模型只使用一个64 x 64的基础模型,并使用这个训练有素的模型,不做任何修改。
在这一节中,我们以DreamFusion中的图像生成流程为例,解释了从自然语言标题 "冲浪板上的孔雀照片 "到 "冲浪板上的孔雀,看起来像是用单反相机拍的 "的图像。(见下图)
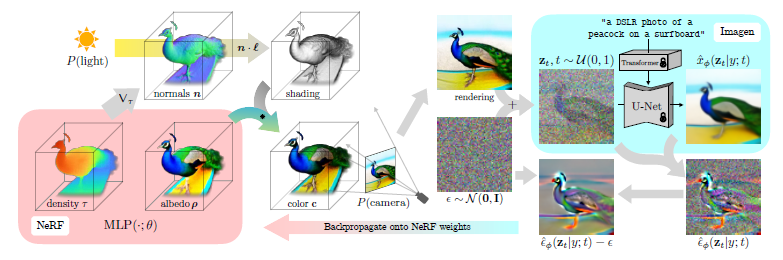
每个DreamFusion的优化迭代都是按以下方式进行的。
- 摄像机和灯光的随机抽样。
- 从它的摄像机和灯光中渲染NeRF图像,用它的灯光进行着色。
- 计算NeRF参数的SDS损失梯度
- 使用优化器来更新NeRF参数
下一节将解释这些步骤。
1、由NeRFs代表的场景是随机初始化的,对每个标题从0开始训练。这里使用的NeRF是通过使用MLP对体积密度和反照率(颜色)进行参数化。
2、这个NeRF是由一个随机的摄像机渲染的,并使用从密度梯度计算出来的法线在随机的照明方向上进行着色。阴影揭示了在单一视角下会被遮蔽的细节
3、为了更新参数,DreamFusion对渲染进行扩散,并通过有条件的Imagen模型进行重建,以预测增加的噪音。这有很高的差异性,但包括一个结构,以提高保真度。
4、同时,通过减去添加的噪声,产生了一个低分散的更新方向stopgrad。这在渲染过程中被反向传播,以更新NeRF MLP的参数。
因此,DreamFusion是通过将SDS与专门从事3D生成任务的NeRF相结合而实现的。
实验和结果
本文比较了现有的零拍文字到3D生成的模型和性能评估,以确定DreamFusion的关键组成部分,从而实现准确的3D几何形状。
与几个基线的比较
对CLIP R-Precision进行了评估,它是渲染图像与输入标题的一致性的自动衡量标准。
下表显示了CLIP R-Presion在DreamFusion和几个基线(包括DreamFields)上的结果,其中原始字幕图像对被CLIP-Mesh和MS-COCO评估的口令。右边还显示了本实验中生成的每个三维物体的视觉对比。
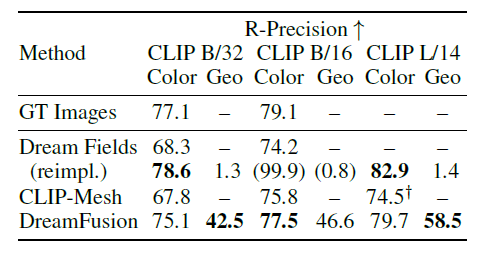

这一评估是基于CLIP,DreamFields和CLIP-Mesh有优势,因为它们在训练中使用CLIP。其中,DreamFusion在彩色图像中的表现优于基线性能,并接近真实图像的性能。
当几何图形(Geo)在无纹理渲染中被评估时,DreamFusion有58.5%的时间与标题相符。
确定关键组成部分。
为了确定DreamFusion的关键组成部分,使准确的3D几何,CLIP R-Precision在基线反照率渲染(左)、全阴影渲染(中)和无纹理渲染(右)中测量,以检查几何质量。通过测量CLIP R-Precision来检查几何质量。(见下图)
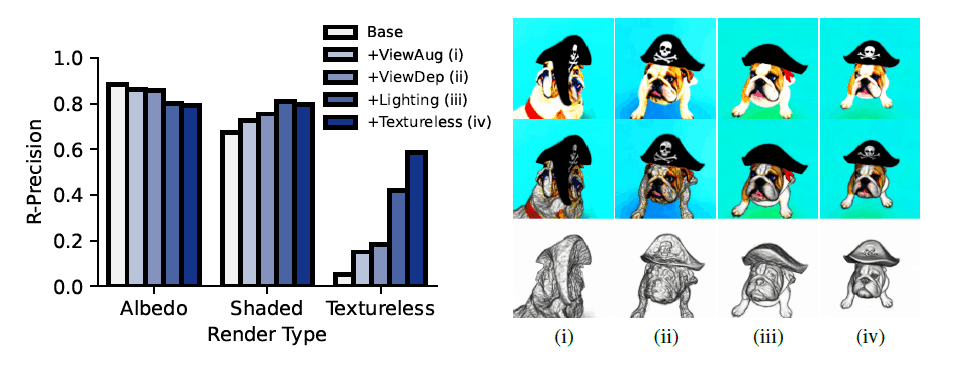
研究发现,依赖视图的提示、照明和无纹理的渲染对于恢复准确的几何图形是必要的。
摘要
在这项研究中,表明新设计的得分蒸馏采样(SDS)和专门从事三维生成任务的NeRF的结合,可以为各种文本生成高保真的三维物体和场景。虽然这种方法取自NeRF,但未来的方法也有望来自GANs。由于采用64 x 64的Imagen模型,DreamFusion在生成物体时也往往缺乏细节。希望这个问题在未来能得到解决,以实现高分辨率、易操作的三维合成。
这样一来,通过文本到图像等多方面的方法,图像到图像中可能出现新的方法。我们预计这项技术在未来将变得更加现实,并在数字双胞胎和机器人领域发挥积极作用。



与本文相关的类别





