
AgentVerse 是一个用于模拟人类合作行为过程的多代理框架,现已推出!
三个要点
✔️ 提出促进多代理群体协同工作的框架 AgentVerse
✔️ 通过模拟问题解决过程的模块化结构,动态调整代理群体的组成
✔️ 比较实验AgentVerse 的性能优于单个代理,具体表现为
AgentVerse: Facilitating Multi-Agent Collaboration and Exploring Emergent Behaviors in Agents
written by Weize Chen, Yusheng Su, Jingwei Zuo, Cheng Yang, Chenfei Yuan, Chen Qian, Chi-Min Chan, Yujia Qin, Yaxi Lu, Ruobing Xie, Zhiyuan Liu, Maosong Sun, Jie Zhou
(Submitted on 21 Aug 2023)
Comments: Published on arxiv.
Subjects: Computation and Language (cs.CL)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
随着 GPT-4 的问世,基于大型语言模型(LLM)的自主代理(如AutoGPT、BabyAGI和AgentGPT)取得了重大进展,使它们能够做出有效决策并执行各种任务。
另一方面,在现实世界中,要高效地完成软件开发、咨询和游戏等复杂任务,个人之间的合作必不可少。
尽管如此,现有的研究并没有试图模拟人类群体在执行复杂任务时的协调行为(用技术术语来说,就是解决问题的过程)。
在本文中,我们提出了 AgentVerse,这是一个模拟人类合作行为和促进多个代理在任务解决中合作的框架,并解释了实验如何证明多代理群体的合作工作优于单个代理。论文证明了多代理群体的协同工作性能优于单个代理。
AgentVerse 框架
上述解决问题的过程变成了人类群体中发生的一系列过程,在这些过程中,"群体确定当前状态与预期目标之间的分歧程度,动态调整群体构成以促进决策合作,并随后实施知情行动"。以下是人类群体中发生的一些过程。
本文提出的 AgentVerse 可模拟问题解决过程,提高自主多机器人群组的任务执行率,它由四个模块组成,如下图所示:专家招募模块、协作决策模块、行动执行模块和评估模块。如下图所示,它由四个模块组成:专家招募模块、协作决策模块、行动执行模块和评估模块。
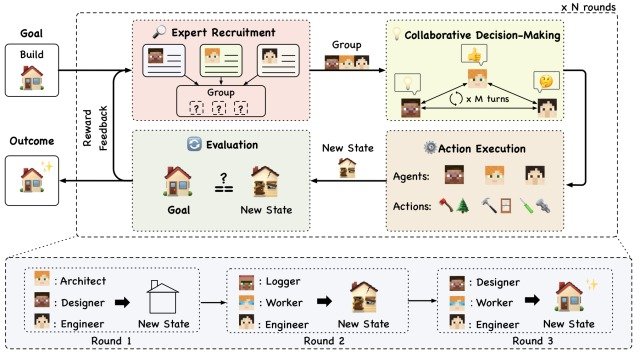
这四个模块的一系列执行以 "回合"(Round)为单位,通过从 "回合 1 "到 "回合 2 "再到 "回合 3 "的重复执行来动态调整代理的分组配置。
让我们逐一了解这些模块。
专家招聘
该模块在确定多机器人群组的配置和确定群组任务执行能力上限方面发挥着重要作用。
最近的研究表明,正如人类雇用专家(Experts)组建团队一样,为自主代理指定特定角色也能提高他们的绩效。
另一方面,将哪些角色分配给自主代理取决于人类的知识和直觉,而且必须根据对任务的理解进行人工分配。
在这种情况下,AgentVerse 使用以下自动方法为代理分配角色
- 根据开始时预定义的专家描述(角色详细提示),生成一套完成任务的专家描述。
- 由此产生的代理组成一个多代理小组,完成给定任务
- 根据 "评估"(见下文)的反馈,动态调整多代理小组的配置。
这些机制允许 AgentVerse根据当前状态配置最有效的多代理群组。
合作决策
该模块涉及生成代理的协作决策。
许多研究都探讨了代理人之间不同沟通结构在促进有效决策方面的有效性。本文重点讨论两种典型的沟通结构,即横向沟通和纵向沟通。
横向沟通是横向沟通,鼓励代理人之间相互理解与合作,每个代理人承担同等责任,积极分担决策。
这种结构使 "横向交流 "适用于需要原创想法或积极合作的任务,如头脑风暴、咨询和合作游戏。
垂直交流则是纵向交流,即分担责任,由一个代理机构做出决策,其余代理机构充当审查者并提供反馈。
这种结构使得垂直交流在软件开发等任务中大显身手,因为在这些任务中,决策需要为实现特定目标而反复推敲。
行动执行
该模块根据上述协同决策中确定的通信结构执行指定任务。
评估
该模块是 Agentverse 的最后一部分,在下一轮调整小组结构和改进小组结构中发挥着重要作用。
该模块通过评估当前状态与目标任务之间的差异,为下一轮任务的改进提供反馈和建设性建议。(该反馈可由人工定义,也可由模型自动定义,具体取决于实现方式)。
如果该任务被认为无法完成,建议反馈将被发送到专家招聘模块的初始阶段,在该模块中,代理小组的组成将根据反馈进行调整,并重复一系列步骤,直到任务完成。
实验
为了证明 AgentVerse 能比单个代理更高效地完成任务,我们进行了一项基准任务的定量实验。(该实验基于 GPT-3.5-Turbo 和 GPT-4)。
本实验采用以下基准来衡量会话、数学计算、逻辑推理和编码技能。
- 对话:使用 FED 和 Commongen-Challenge 数据集,它们是对话响应数据集
- 数学计算:使用包含小学数学问题的数据集 MGSM
- 逻辑推理:使用名为 BigBench 的现有研究中使用的名为逻辑网格谜题的数据集
- 编码:使用代码完成数据集 Humaneval 数据集
在实验中,单个代理根据给定的提示直接生成回复,而 AgentVerse 则通过构建的多代理群体的协同工作生成回复。
采用垂直交流的另一个原因是,这些基准任务得益于一种交流结构,在这种结构中,一个代理可以反复改进自己的答案。
实验结果如下图所示。
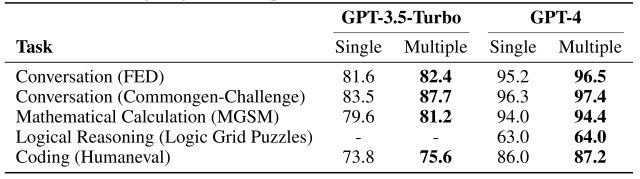
如图所示,在 GPT-3.5-Turbo 和 GPT-4 中,使用 AgentVerse 的多代理群组始终优于单个代理。
因此,本实验的结果表明,多代理群体的协同工作性能优于单个代理的性能。
摘要
结果如何?在这篇文章中,我们提出了 AgentVerse,这是一个用于模拟人类协作行为和促进多个代理在任务解决中协同工作的框架,并通过实验证明了多代理群体的协同工作可以超越单个代理的表现。论文进行了描述。
虽然这项实验的结果证明了多代理小组协同工作的有效性,但另一方面,当前的研究并没有使用 AutoGPT 或 BabyAGI 等高级代理,而是使用了具有基本对话记忆的 LLM。
作者表示,未来的研究将把更强大的性能代理集成到 AgentVerse 框架中,并对其进行扩展和改进,以涵盖更广泛的任务。
本文介绍的 AgentVerse 架构和实验结果的详情可参见本文,有兴趣者可参阅。



与本文相关的类别






