
BERT可以预测一条推特的嗡嗡声!
三个要点
✔️ 提出了ViralBERT,利用推文文本特征和基于用户的特征预测推文的病毒性
✔️ 该方法在F1得分和准确率方面都比基线取得了13%的表现
✔️ 消减研究发现,文本情感信息和粉丝数量是预测中最有效的特征,加入标签数量会降低预测的准确性
ViralBERT: A User Focused BERT-Based Approach to Virality Prediction
written by Rikaz Rameez, Hossein A. Rahmani, Emine Yilmaz
(Submitted on 17 May 2022)
Comments: UMAP 2022
Subjects: Computation and Language (cs.CL); Social and Information Networks (cs.SI)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
近年来,推特作为一种向用户分享和传播信息的社交网络服务,在全世界范围内得到了应用,不仅对个人,而且对所有公司的营销也变得非常重要。
在Twitter上,用户可以通过"转发"来轻松分享他们喜欢的帖子,通过将帖子传播给更多用户来加强他们的影响力。
了解一个帖子通过这种方式获得多少转发,即它能增加多少影响力,对广告商和影响者来说是非常有价值的。
本文介绍了BERT模块和RoBERTa模块,前者采用一种方法将数字特征(如标签和粉丝数量)串联到推文文本中,并通过结合文本和数字特征进行学习,后者则利用文本中的信息和引起情感反应的能力,因为这些与转发倾向有关,从而预测文本的情绪ViralBERT,通过RoBERTa模块预测一条推文的病毒性(=嗡嗡声),它只分析文本。
历史背景和问题定义
Twitter是世界上最大的社交媒体平台之一,每月活跃用户超过3亿,Twitter用户可以分享最多280个字符的文字,称为 "推文",并发送照片、GIF和视频。
如果一条推文比其他推文得到更多的互动,并吸引了推特上更多用户的关注,它就已经病毒化了。
因此,病毒性可以用来确定趋势和话题的流行和参与度,不仅在推特上,而且在整个社会上,预测推文的病毒性是非常重要的。
然而,最近关于病毒性预测的研究很有限,这些研究集中在特定的推文子集或特定的用户,而不是来自整个用户群的推文,并且没有概括到用户或推文的整体。
此外,病毒性预测受许多不容易量化的因素影响 ,如用户亲和力、内容的创造性(推文内容)和与当前社会状况的相关性 ,再加上大多数推文从未被转发, 因此很难创建大型数据集 。这使得它成为一个非常具有挑战性的问题。
本文件的概要。
为了解决这些问题,本文建立了一个由33万条推文组成的样本数据集,并测试了使用BERT架构是否可以预测推文的病毒性这一问题。
数据集
本研究的数据集由Twitter API v2使用Python收集,仅限于八个主题: 加密货币、电视和电影、宠物、视频游戏、手机、COVID-19、足球和K流行,并限于八个主题。
该研究还从原始(非转发的帖子)英语推文中收集关于文本、创建时间、标签数量、提及次数和推文来源客户,以及从用户中收集关于追随者、关注者和状态的信息。
此外,转发、喜欢、回复和引用的数量在推特创建24小时后被检索出来。(这是因为现有的研究表明,一条推特的病毒性在这个时候已经达到了极限)。
病毒伯特
本文提出的ViralBERT架构如下图所示。
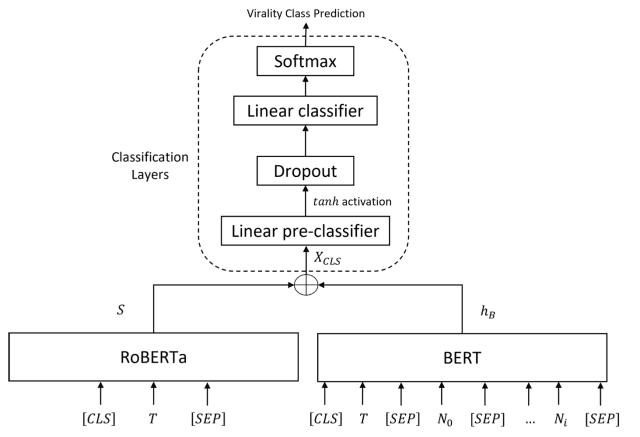
该模型使用BERT从结合推文文本和相关数字特征(标签、提及、关注者、状态和文本长度)的特征中输出,并使用RoBERTa输出推文文本的情感特征的概率分布,即通过将其送入分类层来预测病毒性。
BERT模块
BERTweet是BERT中使用的预训练模型,在8.5亿条推文语料库中进行了微调,并针对用户推文中使用的各种主题和语言进行了优化。
推文文本T及其相关的数字特征(N0,N1,...)。,Ni)串联起来,输出hB输入到分类层。
这可以用下面的公式表示。
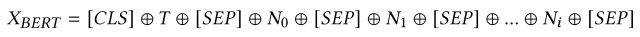
RoBERTa模块
现有研究表明,推文的情感特征对推文的传播有直接影响,该模型采用了基于RoBERTa的预训练模型对推文文本进行情感分析。
该模型的输出是来自推文文本的负面、中性和正面情绪的softmax概率分布S,它以与上述BERT输出相同的方式输入到分类层。
分类层
BERT的输出hB和RoBERTa的输出S被串联起来作为分类层的输入,输出为以下公式
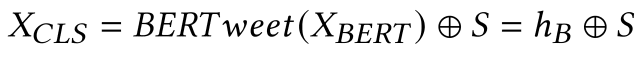
通过对这一输出应用softmax函数,可以得到病毒性的概率。
实验
本文将ViralBERT的性能与现有研究中为类似任务开发的下列基线方法进行比较
- 逻辑回归(Logistic Regrassion):采用牛顿法进行梯度优化,这种技术已被用于预测流行信息。
- 支持向量机(SVM):采用铰链损失和SGD优化,这种方法被用来预测Twitter上新引入的标签的受欢迎程度,并评估转发能力。
- 决策树分类器:使用吉尼杂质得分进行无最大深度分类。这种方法被用来评估转发率。
- 随机森林(Random Forest Classifier):使用100棵没有最大深度的树。这一基线是基于现有的研究,重点是对转发数量和转发可能性的时间性预测。
此外,还有两条基线,即只使用模型的数字特征的MLPNum和只使用文本特征的ViralBERTText,被用来测试这些特征的表现。
实验结果如下表所示。 (最好的结果以黑体字显示) 。 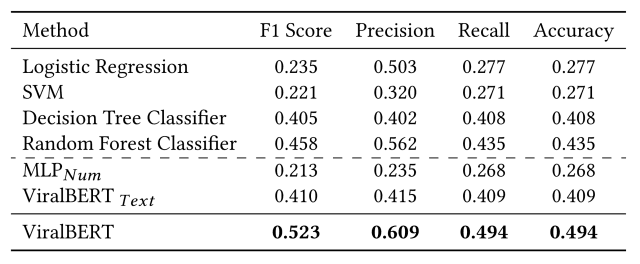
这个实验表明,
- 当ViralBERT只用文本特征进行训练时,与普通的ViralBERT相比,它没有达到最佳性能。
- 当只用数字特征进行训练时,性能明显好于只使用文本时,表明数字特征也是预测病毒性的一个重要因素。
- 通过在文本和数字特征的串联输入上对ViralBERT进行微调,并训练分类层,我们已经能够实现比基线更高的评价指标。
此外,还进行了实验,通过从输入中删除特征并比较模型的性能来衡量每个特征对ViralBERT的重要性。
下表显示了当每个特征从输入中被消除时与ViralBERT的比较结果。
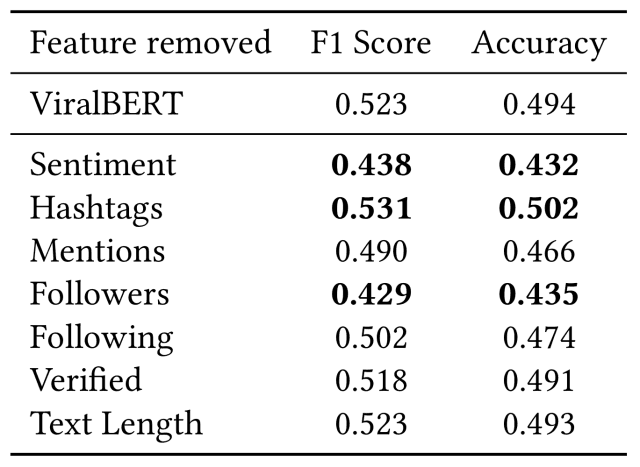
从这个实验中得到了以下观察
- 与其他特征相比,从网络中消除情感(推文的情感特征)或追随者(追随者的数量)会显著降低模型的性能。
- 这很直观,因为拥有更多追随者的用户有可能通过一条推特获得更多关注
- 引起用户更大情绪反应的推文也可能获得更多的转发
- 提及 "和 "关注 "也会影响表现,尽管其程度比上述两个特征要小。
- 这被认为是由于更受欢迎的用户倾向于不关注其他人(更高的追随者/关注比例)。
- 人们还认为,提及次数多的推文不太可能被转发,因为它们的可读性较差,而且使用的空间可用于为用户提供有用信息。
- 最令人惊讶的结果是,消除Hashtags后,模型的性能略有提高
- 这意味着BERT通过增加这个特征可能从输入中学习到更差的表示,因为它与病毒性无关。
这些结果应该在更全面的研究中进一步调查,这些研究涉及更大的数据集和测试各个特征之间的相互作用,未来的一个挑战是了解为什么这些对性能有负面影响。
摘要
情况如何?在这篇文章中,我们介绍了ViralBERT,这是一种基于BERT的方法,利用推文的文本和数字特征来预测推文的病毒性。
虽然该模型在预测病毒性方面取得了比现有方法更好的准确性,但仍存在一些问题,如本文所使用的数据集的不平衡性,通过消除数据集中存在的类异质性,也许可以进一步提高预测准确性。此外,由于发现追随者的数量会影响病毒性,通过收集不太受欢迎的用户的高病毒性的推文,可能会创造一个更好的数据集。此外,还有可能将这一模型用于不同的社会媒体,以预测各种媒体的病毒性,因此未来的发展是非常令人振奋的。
本文所介绍的模型的结构和数据集的细节可以在本文中找到,如果你有兴趣,应该查阅。



与本文相关的类别






