现在有一个新的SoTA模型,用于CQA的任务,回答有关图表的问题!
三个要点
✔️ 提议的分类-回归图转化器(CRCT),一个使用转化器的新CQA模型
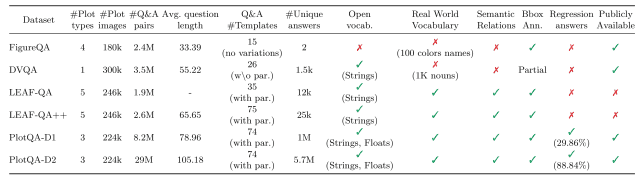
✔️ 为了证明提议模型的有效性,一个由大量不同的图表集组成的数据集采用了PlotQA-D
✔️ 在使用PlotQA-D的实验中,CRCT取得了明显高于现有方法的精确度
Classification-Regression for Chart Comprehension
written by Matan Levy, Rami Ben-Ari, Dani Lischinski
(Submitted on 11 Jul 2022)
Comments: ECCV 2022
Subjects: Computation Vision and Pattern Recognition(cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
由折线图和柱状图组成的图表在现代交流中发挥着重要作用,通过以易于理解的视觉形式总结数据并揭示趋势和异常值,可以提供一系列的见解。
然而,尽管有这种巨大的实际重要性,但由于创建数据集和模型的困难,人们对计算机视觉领域的关注很少。
本文提出了分类-回归图表转化器(CRCT),这是一个明显优于现有方法的模型,并使用PlotQA-D--一个包含大量不同图表和文本的数据集来证明其有效性。本文利用PlotQA-D这个包含图表和文本的大型多样化数据集证明了其有效性。
Char问题回答(CQA)和PlotQAD的背景
图表问题回答(CQA)是一项以图表和自然语言问题为输入的任务,旨在生成问题的答案作为输出,其性质与自然图像上的分类有根本的不同,因为它需要分析图表和文本之间的关系,以回答问题和推断数值。它与自然图像上的分类在本质上是不同的,因为它需要分析图表和文本之间的关系,以便回答问题或推断出一个数值。
之前关于CQA的一些研究提出了新的数据集,但在2020年发表的一篇论文中,Methani等人指出,这些数据集在图表类型和多样性方面已经饱和,为了解决这些问题,他们创建了PlotQA-D,一个大型和多样化的图表和文本为了解决这些问题,他们创建了PlotQA-D,一个包含大量多样的图表和文本的数据集。
如下图所示,与现有的数据集相比,PlotQA-D在图表和文本的数量上是最大的。(PlotQA-D1是初始版本,PlotQA-D2是包括子集的扩展版本)。
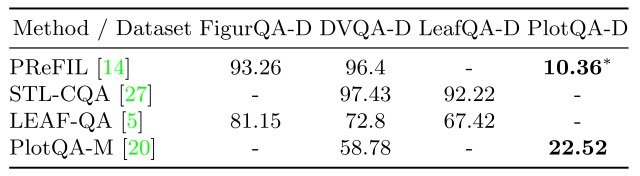
此外,在下图中,将CQA任务与使用多个数据集的现有模型(包括PlotQA-D)的准确性进行比较,可以看出只有PlotQA-D的准确性明显降低,如黑体字所示,有人指出现有模型无法应对如此大的数据集。在现有模型中,使用多个数据集的CQA任务的准确率,包括CQA任务的准确率,用黑体字显示。
分类-回归图转化器(CRCT)。
本文创建了一个新的基于变换器的模型,称为分类-回归图变换器(CRCT),以解决上述问题并在PlotQA-D中达到最先进的水平。CRCT是一个新的基于变换器的模型,称为分类-回归图变换器(CRCT)。
CRCT结构的概述见下图。
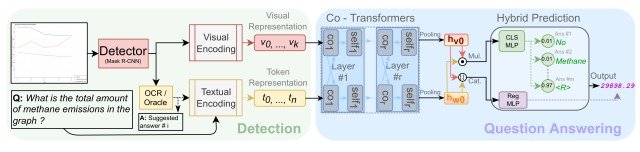
CRCT包括两个阶段,检测和回答问题,其中检测(图的左边)对输入图像的图表和文本部分进行视觉编码和文本编码,以产生视觉特征产生视觉表征和标记表征,并传递给问题回答(图的右边)。
然后,"问题回答 "通过协同转化器将视觉和文本信息转化为两个单一的特征向量hv0、 hw0,并通过一个包含两个不同MLP的预测头输出分类分数和回归结果。
这一模式与现有模式的不同之处主要有四个方面
- 与现有的只对问题进行编码的模型相比,这个模型联合处理图表中的所有文本元素
- 通过放弃常见的 "字符串匹配 "并采用由预先训练的BERTs组成的Co-Transformers,使高通用性成为可能。
- 采用了一种新颖的图表表示学习,融合了来自不同领域的多种输入。
- 混合预测是现有模型所不具备的,它允许将分类和回归结合在一个模型中(二进制交叉熵损失用于分类,L1损失用于回归)。
这些创新使CRCT能够为所有类型的问题提供端到端的学习。
评价
本文使用PlotQA-D作为评价基准,对所提出的模型CRCT进行了几次实验。
与现有模型的比较
最初,使用PlotQA-M(提出PlatQA-D的论文中一起提出的模型)、PReFIL(传统方法中的代表模型)和CRCT-10%(用CRCT中10%的训练数据预训练的模型)进行比较实验。
结果显示在下图中。(左图:使用正常PlotQA-D的验证结果,右图:使用正常PlotQA-D的三分之一大小的验证结果)。
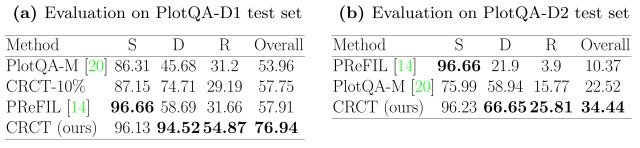
在表中,S指的是结构性问题(关于图表结构的问题),D指的是数据检索(从图表中检索答案数据的问题),R指的是推理(从整个图表中推断出问题文本的答案的问题),Overall指的是所有随机提问的平均准确性从这个实验中可以看出,与现有模型相比,所提出的模型取得了非常高的准确率。
视觉化的ATTENTION。
接下来,使用CAPTUM对CRCT ATTENTION进行了可视化,如下 图所示。
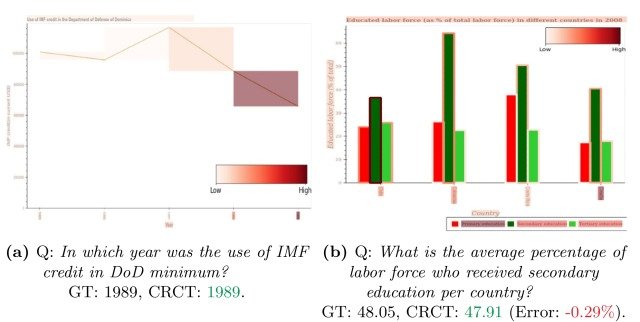
网络确定有理由回答某一问题的区域被用颜色编码,从上图可以看出,当被问及(a)中线型图的最小值时,CRCT的注意力被引向图中最小值对应的区域,当被问及某一类别(中等教育)的平均值时,CRCT被引向(b)中的条形图。教育)时,CRCT将其注意力引向相应类别的条形图,当问及(b)中某一类别(中等教育)的平均值时。
摘要
它是如何做到的?在这篇文章中,我们提出了分类-回归图表转化器(CRCT),这是一个能使性能明显优于现有方法的模型,并使用PlotQA-D证明了它的有效性,这是一个包含大量不同图表和文本的数据集。该论文证明了该模型的有效性。
本文提出的模型在PlotQA-D数据集上显示出非常好的准确性,这是现有模型所不能处理的,而且注意力的可视化恰当地识别了图表的相关部分,表明它是一个非常实用的CQA任务的模型。该模型在CQA任务中被证明是非常实用的。
另一方面,仍然存在一些问题,如训练和测试数据之间的图形颜色不同,以及在使用非线性图形作为输入时准确性下降,因此有可能通过扩大数据集以包括更多颜色和类型的图形来进一步提高性能。我们非常期待未来的发展。这里介绍的模型的结构和生成的文本的细节可以在本文中找到,感兴趣的朋友可以参考一下。



与本文相关的类别

