OpenCQA,回答文本中关于图表的开放性问题的任务!
三个要点
✔️ 提出了OpenCQA,一个回答带有描述性文本的关于图形的开放式问题的新任务
✔️ 为OpenCQA创建了一个基准数据集,包括开放式问题和关于它们的描述性答案
✔️ 使用最先进的模型作为基线进行验证并发现,虽然所使用的模型能够产生流畅和一致的解释文本,但它在进行复杂的逻辑推理时有困难。
OpenCQA: Open-ended Question Answering with Charts
written by Shankar Kantharaj, Xuan Long Do, Rixie Tiffany Ko Leong, Jia Qing Tan, Enamul Hoque, Shafiq Joty
(Submitted on 12 Oct 2022)
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Computation and Language (cs.CL)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
使用数据可视化技术,如柱状图和线状图来发现并向他人解释数据中的关键见解,是许多任务的必要过程,但它可能是劳动密集型和耗时的。
图表问题回答(CQA)是为了解决这些问题而设计的,它是一个以图表和自然语言问题为输入的任务,旨在生成一个问题的答案作为输出。
CQA是一项近年来受到广泛关注的任务,但现有的数据集只关注答案是一个词或短语的封闭式问题(即答案是一个选择,如 "是/否 "或 "A/B")。.
本文 提出了一个 新的任务--OpenCQA,旨在用描述性文本回答关于图形的开放式问题来 解决这个问题,并通过创建和验证这个任务的基准数据集基线来证明其有效性。 该论文描述了通过创建和验证这一任务的基准数据集基线来证明这一任务的有效性。
数据收集和注释
到目前为止,还没有建立由开放式问题和注释者撰写的回答文本组成的数据集,原因是带有图表和相关文本描述的数据源没有得到很好的宣传。
因此,在本文中,我们决定使用皮尤研究公司(pewresearch.org)的图表,专业作家使用各种图表及其摘要来撰写关于市场研究、公众意见和社会问题的文章。
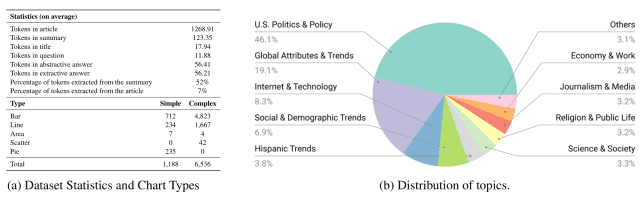
对于从本网站约4000篇文章中搜出的9285个图表-摘要对,通过添加新的(图中绿色、紫色、蓝色和棕色文本)或删除(图中红色文本)摘要文本,共创建了7724个样本数据集,如以下过程所示这些数据是:。

创建的数据集包括各种类型的图表,如条形图、折线图和饼图,从下图(a)可以看出,涵盖了不同的主题,包括政治、经济和技术,从下图(b)可以看出。
OpenCQA任务
本文提出的OpenCQA是一个输出文本的任务,该文本是关于一个图形的输入问题的答案,具体有四种问题类型,如下图所示。
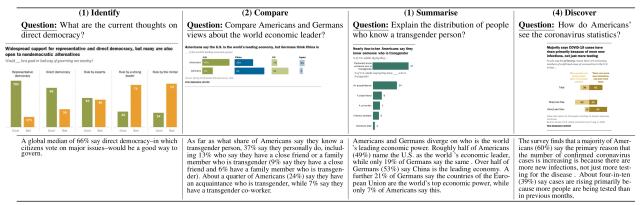
- 识别:关于一组酒吧的特定目标的问题
- 比较:在图表上比较两个具体目标的问题。
- 总结:要求你在图表上总结出统计分布的问题。
- 发现:不指定具体任务的问题,但要求在整个图表中进行推断。
基线模型
在本文中,以下七个现有模型被用作创建数据集的基线。
- BERTQA:通过对原始BERT模型使用定向外套层来提高性能的模型。
- ELECTRA:一个采用自我监督的表征性学习的模型,强调计算效率。
- GPT-2:一个基于Transformer的文本生成模型,根据给定文本中的单词,依次预测下一个单词。
- BART:一个已被证明在文本生成任务中取得最先进性能的模型,如总结,使用一个标准的编码器-解码器转换结构。
- T5:一个统一的编码器-解码器转换模型,用于将语言处理任务转换为文本-文本格式。
- VLT5:基于T5的框架,将视觉-语言任务统一为多模态输入的文本生成。
- CODR:一个提出文档落地生成任务的模型,该模型用文档提供的信息增强了文本生成。
在这些模型上测试了以下三个条件
- 设置1:提供文章(=图表的全文和附带的文章被作为输入)。
- 设置2:提供摘要(=只提供图表及其相关文章的摘要作为输入)。
- 设置3:不提供摘要(=只提供图表作为输入)。
鉴于每个条件下的输入和关于图形的问题,基线模型会生成问题的答案。
评价
本文进行了两次验证:通过评价指标的自动评价和对答案质量的人工评价。
自动评估
自动评估是针对使用六个评估指标创建的数据集进行验证的:BLEU、ROGE、CIDEr、BLEURT、内容选择(CS)和BERT得分。
设置1-3条件下的验证结果如下图所示。
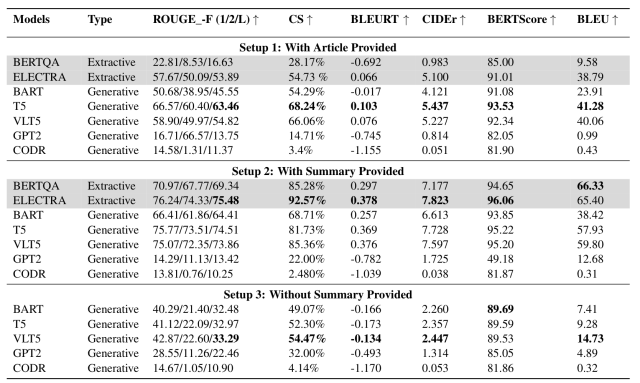
从 这个表格中 ,我们发现
- 当只提供相关摘要时(设置2),与提供全文时(设置1)相比,性能明显提高。
- 此外,与只提供图表的情况(设置3)相比,提供摘要时(设置2)的表现主要是更好。
- 这被认为是由于如果没有给出摘要,模型就没有文本参考来生成问题的答案。
- 当没有摘要时,VLT5在大多数指标上取得了最佳结果
- 这被认为是由于VLT5同时使用图形图像和文本特征来产生反应。
这些结果表明,对于大多数模型来说,当给定一个 "图+相关摘要 "时,就能实现最佳性能。
人的评价
为了进一步评估该模型产生的反应的质量,由三位英语为母语的注释者对从OpenCQA数据集中随机选择的150个图进行了比较验证。
VLT5是自动评估中表现最好的模型,被用作比较模型,并分别标为VLT5-S和有摘要文本和无摘要文本的VLT5。
注释者根据现有研究中采用的三个标准来评估模型生成的反应。
- 事实正确性:生成的文本中包含的信息可以被图表所读取的程度。
- 相关性:产生多少与问题相关的文本
- 流利性:生成的文本中有多少包含格式和大小写错误
根据这三个标准,注释者对产品进行了从1(最差)到5(最佳)的五级评分。
结果如下图所示。(正确答案标记为金色)。
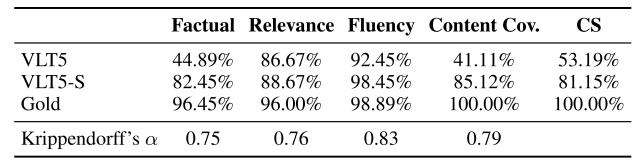
该表显示,VLT5-S(有摘要说明)在每个指标上的评分都高于VLT5(无摘要说明)。
另一方面,VLT5模型在相关性和流畅性方面得到了高分,但在事实性和CS方面还有待改进。(下图中的红色文字显示的是回答错误的地方)。
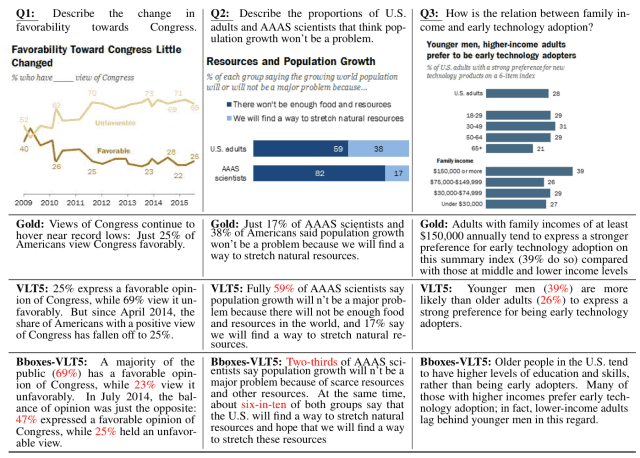
这个问题,即只用图形作为输入时,生成的文本的准确性会大大降低,被认为是未来要改进的问题。
摘要
情况如何?在这篇文章中,我们描述了一篇提出OpenCQA的论文,这是一个回答带有描述性文本的图形的开放式问题的新任务,并为这个任务创建了一个大型数据集和基线。
作者表示,虽然这个基线在现有的评价指标下取得了很好的效果,但生成更像人类反应的任务的性质需要进一步研究,以建立与人类判断相关的更好的评价指标,所以未来的进展非常值得期待。
本文介绍的数据集和基线模型架构的细节可以在本文中找到,如果你有兴趣的话,应该查阅。



与本文相关的类别