
图形对比性聚类
三个要点
✔️ 开发了一个新颖的图对照框架,通过学习来确保同一聚类和增量结果中的样本具有相似的表示数量。
✔️ 将上述框架应用于聚类,并引入了一个学习具有高判别性能的特征的模块和一个更紧凑的集群分配模块。
✔️ 图像聚类实验。在各种数据集上。并记录了明显高于现有模型的准确性。
Graph Contrastive Clustering
written by Huasong Zhong, Jianlong Wu, Chong Chen, Jianqiang Huang, Minghua Deng, Liqiang Nie, Zhouchen Lin, Xian-Sheng Hua
(Submitted on 3 Apr 2021)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
最近,有人提出了对比性学习,它同时进行表示和聚类分配。然而,聚类可能受到传统方法不考虑分类信息的限制。因此,本文开发了一个新的图对比框架,并提出了应用于聚类的图对比聚类(GCC)。
技术
$N$未标记的$N$图像,属于$K$类型的类别给定一组图像${\bf I}=\{I_1,I_2,\cdots,I_N\}$,聚类的目的是将它们分为$K$类型的聚类。为了获得特征,一个CNN模型$\Phi(\theta)$被训练,$(z_i,p_i)$通过将$I_i$映射到$d$维特征表示($||z_i|||_2=1$)和$K$维聚类分配概率分布($\sum_{j=1}^Kp_{ij}=1$).第$i$个样本的预测标签按以下方式获得。
$$l_i = {rm arg max}_j(p_{ij}), 1\le j\le K$$
图形对比法(GC)
让$G=(V,E)$是一个无向图,顶点$V={v_1,cdots,v_N}$和边$E$。设$G=(V,E)$是一个无向图,顶点$V={v_1,cdots,v_N}$,边$E$,定义邻接矩阵$A$为
$$A_{ij}=\begin{cases}1, & {\rm if}(v_i, v_j)\in E \\0, & {\rm otherwise} \end{cases}$$
让$D_i$为$V_i$和矩阵$D$的顺序。
$$d_{ij}=\begin{cases}d_i, & (i=j) \\0, & (i\neq j) \end{cases}$$
是一个有$ij$成分的矩阵,归一化的对称图拉普拉斯定义为
$$L=I-D^{-\frac{1}{2}}AD^{-\frac{1}{2}},\ L_{ij}=-\frac{A_{ij}}{\sqrt{d_id_j}}(i\neq j)$$
给出$N$归一化的$N$特征表示${\bf x}=\{x_1,\cdots, x_N\}$,如果$A_{ij}>0$,GC确保$x_i$和$x_j$接近,如果$A_{ij}=0$,$x_i$和$x_j$远离。如果图被划分为几个社区,同一社区的特征表示的相似性将大于不同社区的特征表示。将内部和外部社区的相似性$S_{intra}$和相似性$S_{inter}$分别定义如下。
$$S_{intra}=\sum_{L_{ij}<0}-L_{ij}S(x_i,x_j)$$
$$S_{inter}=\sum_{L_{ij}=0}S(x_i,x_j)$$
然而,$S(x_i,x_j)$是相似度,本文使用的是高斯核。
$$S(x_i,x_j)=e^{-||x_i-x_j||_2^2/\tau}\sim e^{x_i\cdot x_j/\tau}$$
因此,GC的损失是
$${\cal L}_{GC}=-\frac{1}{N}\sum_{i=1}^N\log(\frac{S_{intra}}{S_{inter}})$$
这将是一种情况。
GCC
GCC框架如下图所示。
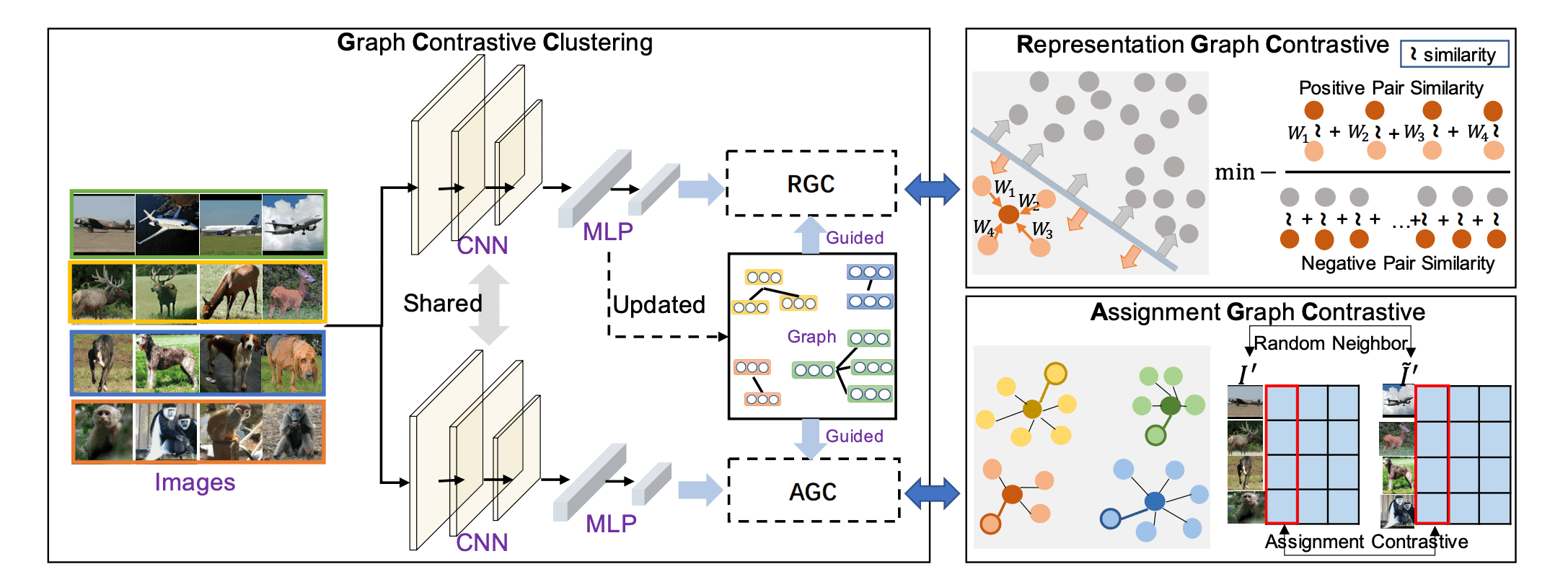
它由两个共享CNN的头组成,包括一个用于学习特征的Representation Graph Contrastive(RGC)模块和一个用于学习集群分配的Assignment Graph Contrastive(AGC)模块。
RGC
如果${\bf I}'=\{I_1',\cdots,I_N'\}$是原始图像的随机变换,$z'=(z_1',\cdots,z_N')$是它们的特征,根据以上讨论,RGC损失可以写成如下。
$$L_{RGC}^{(t)}=-\frac{1}{N}\sum_{i=1}^N\log\left(\frac{\sum_{L_{ij}^{(t)}<0}-L_{ij}^{(t)}e^{z_i'\cdot z_j'/\tau}}{\sum_{L_{ij}=0}e^{z_i'\cdot z_j'/\tau}}\right)$$
AGC
让${\bf {\tilde I}}'=\{{\tilde I}_1',\cdots, {\tilde I}_N'\}$为一个向量,这样${tilde I}_j'$就是基于$A^{(t)}$的$I_i$的随机邻域样本的随机变换图像。每个概率向量是
$${bf q}'=[q_1',\cdots, q_K']_{N\times K}$$
$${\tilde {\bf q}}'=[{\tilde q}_1',\cdots,{\tilde q}_K']_{N\times K}$$
这可以表示为:。其中$q_i'$和${tilde q}_i'$是概率向量,分别代表${\bf I}'$和${\tilde {\bf I}}'$的哪些样本属于$i$集群。AGC的损失可以写成如下。
$${\cal L}_{AGC}=-\frac{1}{K}\sum_{i=1}^K\log\left(\frac{e^{q_i'\cdot q_i'/\tau}}{\sum_{j=1}^Ke^{q_i'\cdot q_j'/\tau}}\right)$$
损失函数
为了避免出现局部最优解,还加入了以下正则化LOSS。
$${cal / L}_{CR}=\log(K)-H(\cal Z)$$
然而,$H$是熵,${\cal Z}_i=\frac{\sum_{j=1}^Nq_{ij}}{\sum_{i=1}^K\sum_{j=1}^Nq_{ij}}$。最终的损失函数是。
$${cal L}={cal L}_{RGC}+lambda{cal L}_{AGC}+eta{cal L}_{CR}$$
其结果是。其中$lambda,\eta$是一个超参数。
结果。
在六个不同的基准数据集上与传统方法进行了性能比较。结果显示在下面的表格中。
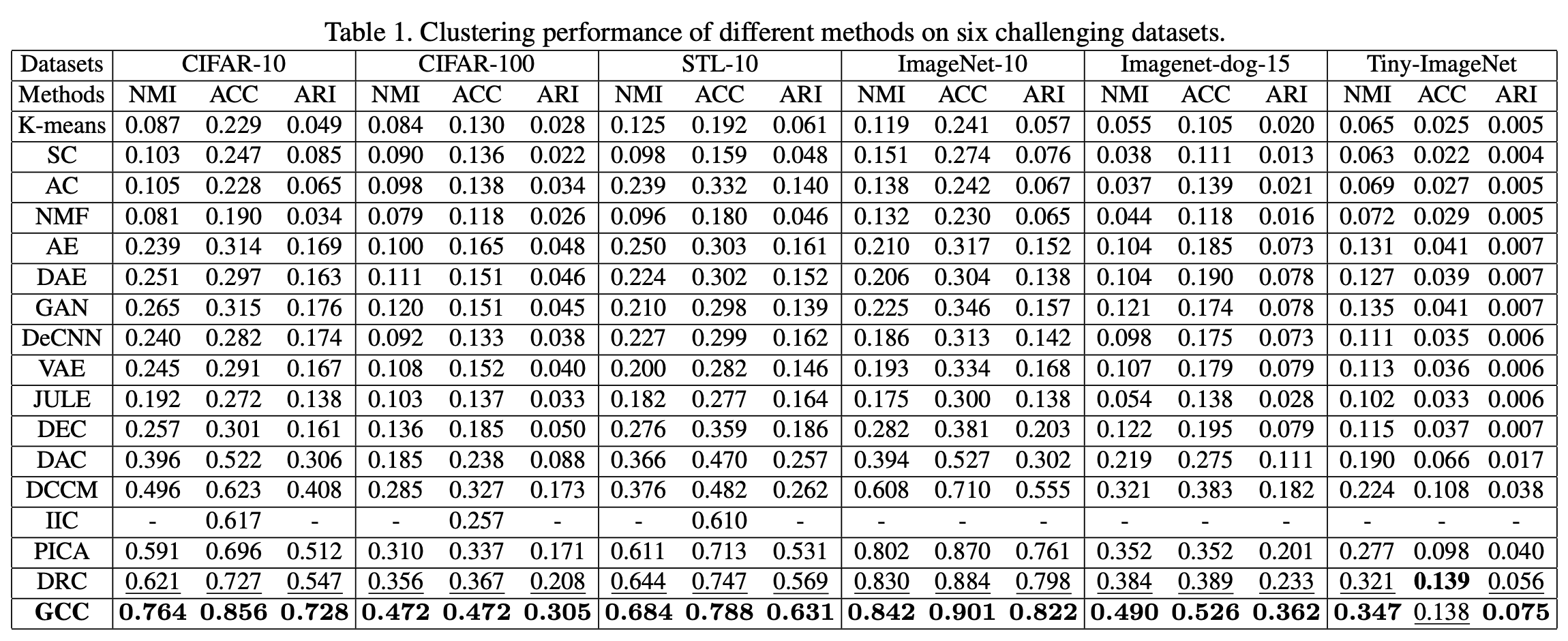
表中显示,本文的方法在所有三个评价指标中都是有效的,其结果在所有数据集上都比传统的SOTA模型有明显改善。成功和不成功的GCC样本的例子也显示在下图中。

图中显示,成功的样本(左边)包括那些具有不同背景和角度的样本,表明了鲁棒性。另一方面,不成功的样本(中间,右边)是具有类似形状的其他类,或图片中具有不同图案的类,因此在无监督学习中很难将它们分开,这是一个挑战。
摘要
本文提出了一种新的基于图形对比学习的聚类方法。与以前的方法不同,它通过使样本和属于同一聚类的其他样本的增量的相似性更加接近来有效地学习。因此,它在六个基准上的表现明显优于传统的SOTA。



与本文相关的类别


![[CLAP] 语音和文本对比学习模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/December2023/clap_2_-520x300.png)
![[LP-MusicCaps] 使用 LL](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2023/lp-musiccaps-520x300.png)
![[MuLan] 使用对比学习的多模态音乐](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/mulan-520x300.png)

