
无监督的双曲线距离学习
三个要点
✔️ 提出了无监督的双曲距离学习,它可以比以前更好地提取数据的层次结构。
✔️ 引入了一个新的损失函数,更精细地考虑层次相似性,而不是将其二分法。
✔️ 本文提出的模型在三个聚类的基准上记录了SOTA。
Unsupervised Hyperbolic Metric Learning
written by Jiexi Yan, Lei Luo, Cheng Deng, Heng Huang
Comments: CVPR
Subjects: Computer Vision and Pattern Recognition (cs.CV)
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
距离学习,包括学习相似性距离,是很重要的,在计算机视觉的各个领域都有研究。特别是,使用深度学习的距离学习功能,将正向样本放在离锚点更近的地方,而将负向样本放在离锚点更远的地方。然而,由于在现实世界中很难获得大量的标记数据,学习数据内在结构的无监督方法引起了人们的关注。传统的方法将数据二分为正和负,但在现实世界中,同样的负样本有的离锚更近,有的离锚更远,所以可以用更多的分层分类来学习特征。还有人提出,在欧氏空间中获得特征并不总是能捕捉到数据的结构。因此,在本文中,我们提出了一种无监督的双曲距离学习方法,从无标签的数据中提取内在信息。首先,数据从通常的欧几里得空间并入双曲空间。然后,进行分层聚类以获得假标签。此外,我们引入了一个新的损失函数,将分层相似性考虑在内。
技术
该模式在下图中有所概述。给定一个数据集${\cal D}=\{{\bf x}_1,{\bf x}_2,\cdots{\bf x}_n\}$,特征${\cal Z}=\{{\bf z}_i=f({\bf x}_i|\theta)\}_{i=1}^n$得到。然后在分层聚类模块中进行聚类。从聚类结果${cal H}$,计算出相似度${\cal S}=\{s_{ij}\}_{i,j=1}^n$。${\cal S}$作为教师数据来微调双曲线远程学习模块。
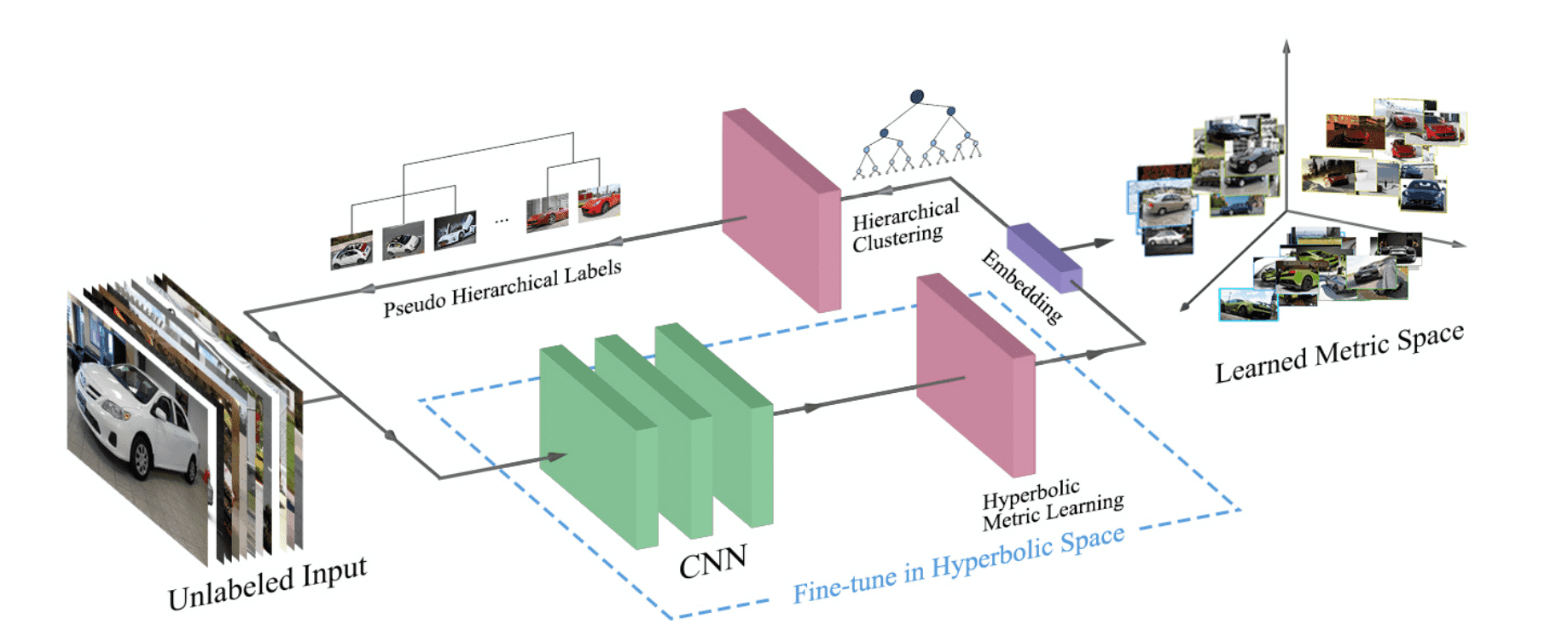
双曲线远程学习
在本文中,引入了双曲几何来捕捉层次结构。 特别是,我们考虑双曲空间的Poincaré球体模型,对应于具有特定轻量级张量的黎曼流形。 庞加莱球体模型由流形${\mathbb D}_\tau^d=\{{\bf x}\in {\mathbb R}^d: \tau||{|\bf x}||<1,\tau\geq0\}$定义。 其中$\tau$是Poincaré球的曲率。 在这个模型中,${\bf z}_i,{\bf z}_j\in {\mathbb D}_\tau^d$的两点之间的距离是
$$d_{\mathbb D}({\bf z}_i, {\bf z}_j)={\rm cosh}^{-1}\left(1+2\frac{||{\bf z}_i-{\bf z}_j||^2}{(1-||{\bf z}_i||^2)(1-||{\bf z}_j||^2)}\right)$$
这与相同。 然后,双曲网络层被添加到最后一层,"exp "映射从${\mathbb R}^n$的输入特征投射到${\mathbb D}_\tau^n$的双曲流形。
$${\bf z}={\rm exp}^\tau({\bf x}):={\rm tanh}({\sqrt \tau}||{\bf x}||)\frac{{\bf x}}{{\sqrt \tau}||{\bf x}||}$$
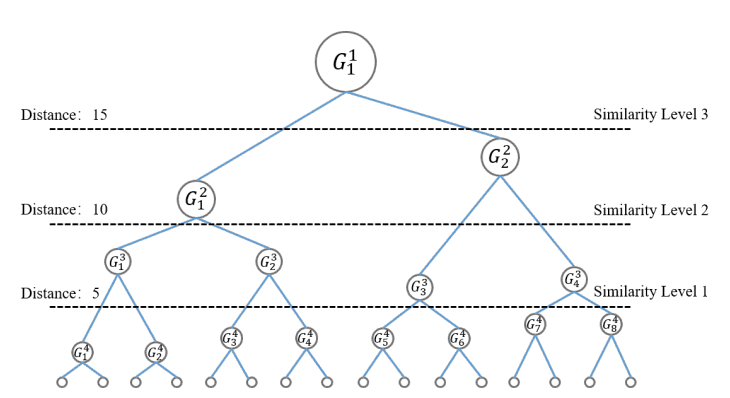
层次相似性
为了获得更好的信息内容,考虑一个由几个子群组成的树状结构,如下图所示。不同子群中的样本之间的距离为
$$d_{ab}=\frac{1}{n_an_b}\sum_{{\bf z}_i^a\in C_a, {\bf z}_j^b\in C_b}||{\bf z}_i^a-{\bf z}_j^b||$$
定义。请注意,${\bf z}_i^a, {\bf z}_j^b$是子群$C_a, C_b$的样本,$n_a, n_b$是$C_a, C_b$的样本数。 相似度是根据$d_{ab}$的大小和阈值$\delta$来计算的。 在下面的例子中,这是$\delta=\{5,10,15\}$时得到的三个相似度级别。 最后,作为样本之间的相似度${\bf z}_i^a, {\bf z}_j^b$。
$$s_{ij}=L_k, \ L_k \in \{1,2,\cdots,K\}$$
定义。
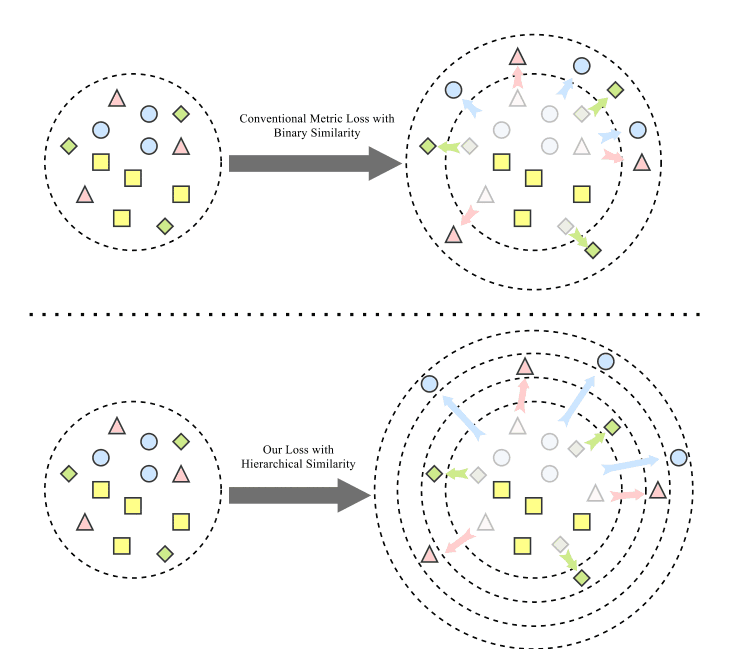
损失函数
为了有效利用层次相似性信息,给定一个双曲空间中$\{{\bf z}_i, {\bf z}_j, {\bf z}_l\}\in {\cal S}$的样本,定义损失函数如下。
$${\cal L}(i,j,l)=\left({\log}\frac{||{\bf z}_i-{\bf z}_j||}{||{\bf z}_i-{\bf z}_l||}-{\log}\Omega^{s_{ij}-s_{il}}\right)^2$$
然而,$Omega$是一个超参数,可以调整层次相似性的贡献。第一项是样本之间的对数比,第二项是相应的层次相似度的对数比。通过引入这一点,阴性样本可以根据其相似性进行分离,如下图所示。
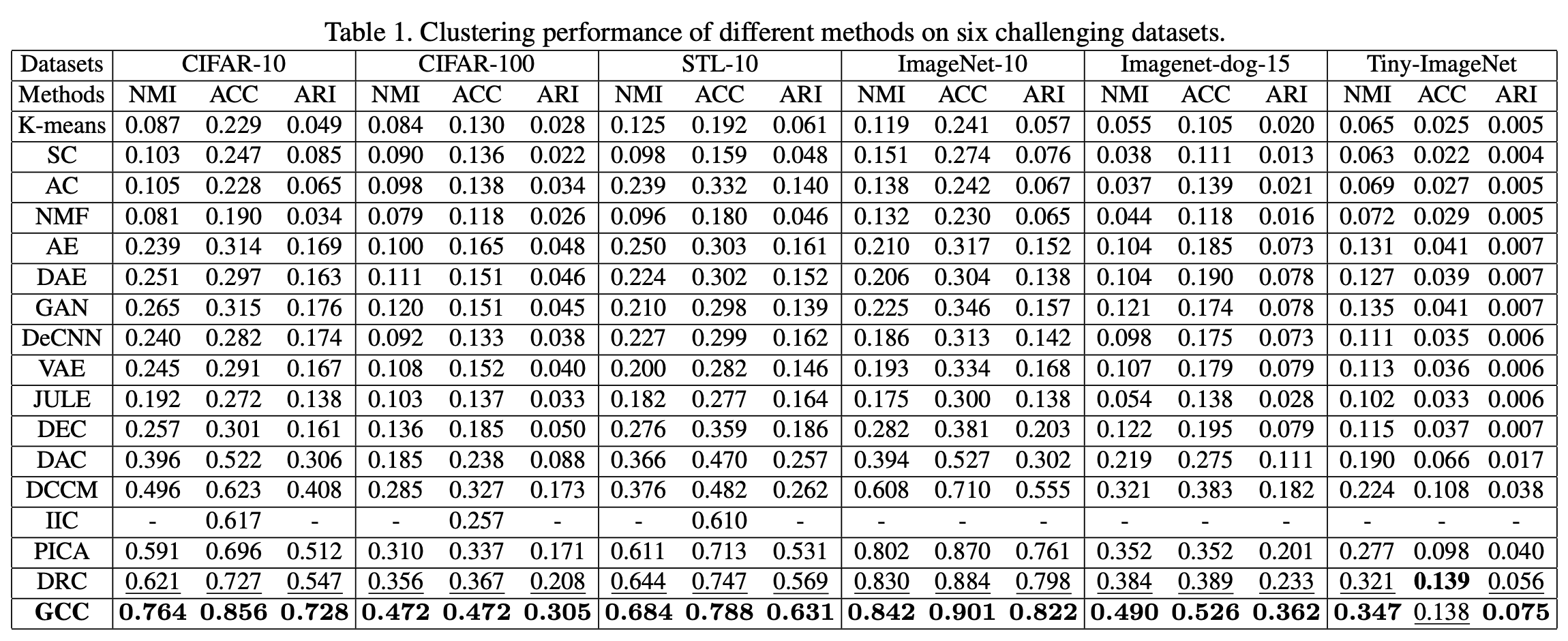
结果
为了与以前的模型进行比较,在一个公共数据集上使用无监督的方法进行了图像检索任务。结果显示在下面的表格中。其中SOP(斯坦福在线产品)、CARS196和CUB-200-2011是公共数据集,R@K是每个层次K的召回率。从表中可以看出,该方法在所有数据集上都显示出最佳的性能。这表明,通过使用层次相似性可以提取更多的信息。

摘要
本文提出了无监督的双曲线距离学习。首先,考虑到了层次相似性,并在双曲空间中进行聚类。此外,还引入了一个新的损失函数,以考虑到它们。与以前的模型相比,提议的方法在几个基准上记录了SOTA。



与本文相关的类别


![[CLAP] 语音和文本对比学习模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/December2023/clap_2_-520x300.png)
![[LP-MusicCaps] 使用 LL](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2023/lp-musiccaps-520x300.png)
![[MuLan] 使用对比学习的多模态音乐](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2023/mulan-520x300.png)

