
融合基于流动和扩散的模型 - DiffFlow
三个要点
✔️ 扩散归一化流量(DiffFlow)扩展了基于流量的模型和扩散模型,并结合了两种方法的优势。
✔️ DiffFlow通过放宽基于流的模型中函数的总单射性,提高了模型的代表性,并比扩散模型提高了采样效率。
✔️ DiffFlow还可以生成复杂的精细分布特征,这些特征是基于流动或扩散模型所无法模拟的。
Diffusion Normalizing Flow
written by Qinsheng Zhang, Yongxin Chen
(Submitted on 14 Oct 2021)
Comments: Neurips 2021
Subjects: Machine Learning (cs.LG)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
学习数据分布以人工生成未知数据的深度学习模型被称为深度生成模型。深度生成模型训练神经网络,从潜在变量$mathbb{x}$产生数据$mathbb{z}$。
其中,潜变量和数据的维度是相等的,这些模型可以将潜变量产生数据的过程视为同一空间的轨迹。当这个轨迹被确定地固定为一个时,它被称为基于流量的模型;当它被随机地固定时,它被称为扩散模型。
基于流量的模型通过使用函数对潜在变量进行顺序转换来生成数据。这个函数必须是可逆的,这一约束限制了模型的表达能力。
另一方面,扩散模型由一个扩散过程和一个反过程组成,前者向数据连续添加噪声,使其成为一个简单的潜变量,后者通过逐渐去除噪声来恢复数据。在逆过程中产生高质量的样本需要扩散过程中的噪声添加足够慢,这有一个缺点,即训练模型很耗时。独立于数据分布而添加噪声的性质也使其难以捕捉分布中的详细特征。
本文提出的扩散归一化流量(DiffFlow)考虑到了上述基于流量的模型和扩散模型的缺点,并以结合两种方法的最佳方式生成数据。下面将简要介绍基于流动和扩散的模型,然后是DiffFlow的概述。
什么是基于流量的模型(规范化流量)?
在基于流动的模型(归一化流动)中,上述空间轨迹由以下微分方程来模拟
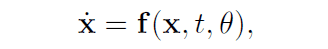
这里,$mathbb{x}(0)$代表起点,即数据,$mathbb{x}(T)$代表终点,即潜变量$z$。T$代表到$T$的时间步长,在这个时间段内,它被转化为一个潜变量。
在此,假设是连续时间,可以得出以下关系
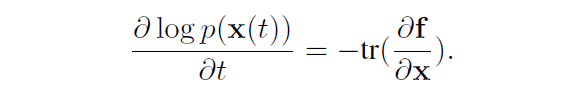
此外,如果假设是离散时间,则可得出以下关系。在这种情况下,从数据到潜变量的映射是所有单射函数$F=F_N\circ F_{N-1}的复合函数。 F_{2}\circ F_{1}$。
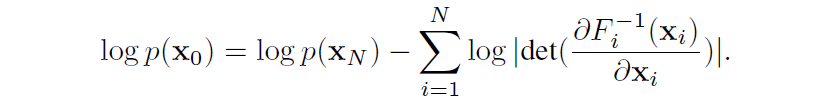
基于流量的模型的特点是能够直接计算数据的可能性,如上式所示。
什么是扩散模式?
扩散模型中的空间轨迹是由随机微分方程建模的。从数据到潜变量的扩散过程用以下关系式表示在方程中,$mathbb{f}$是一个输出矢量的函数,被称为漂移项。另外,$g$是一个标量函数,被称为扩散系数。
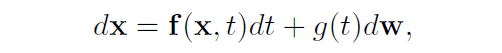
从潜变量到数据的逆向过程也可以用以下关系表示
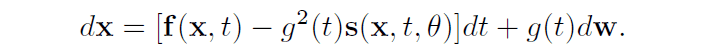
已知逆过程中的函数$mathbb{s}$与扩散过程中轨迹上的分布$p_F$的得分函数$nabla log(p_F)$重合,并且在两个过程中的潜变量具有相同分布的条件下,逆过程中轨迹上的分布$p_B$与$p_F$重合。有以下信息。
扩散模型训练由神经网络近似的$mathbb{s}$,以最小化$p_F$和$p_B$分布之间的差异,并在逆过程中使用采样来产生数据。KL发散是衡量这种分布差异的主要指标。
在离散时间条件下,$p_F$和$p_B$可以分别表示如下这可能会使人们更好地了解扩散和逆向过程。
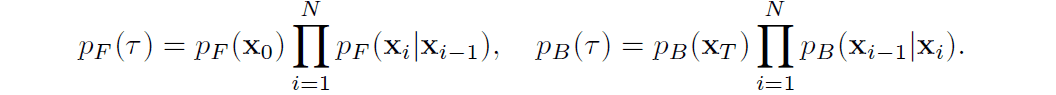
在扩散模型中,不能直接获得数据似然,所以要计算对数似然的下限。
扩散流
本文提出的扩散归一化流(DiffFlow)提出了一个介于归一化流和扩散模型之间的模型。数据和潜变量的双向过程在下面说明了归一化流量、扩散模型和DiffFlow的情况。
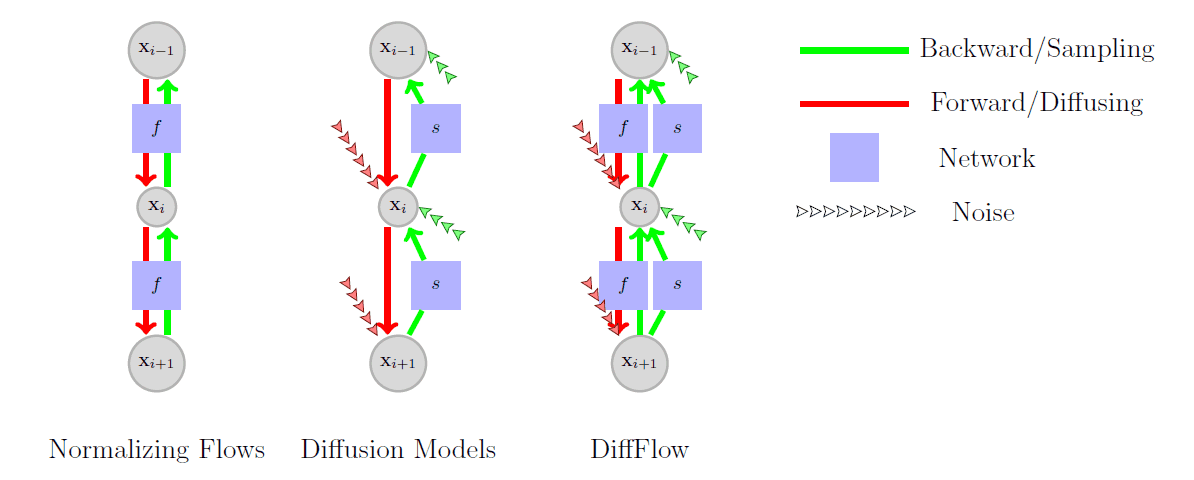
主要的区别是,在扩散过程中只表示为简单的线性函数的函数$f$可以被神经网络近似和学习,并且在函数$f$中不存在于归一化流中的部分引入了噪声。
在基于流量的模型中只使用可逆函数可以保证数据被恢复,但不能保证最终能达到高斯噪声的要求。另一方面,扩散模型增加了与数据无关的噪声,因此只要完全忽略数据,只需一步就可以达到高斯噪声。然而,这并不产生数据,因为无法学习到反过程。
通过在将数据转化为潜变量的过程中增加一个新的可学习函数$f$,DiffFlow被认为在数据采样的逆过程中提供了一个充分的监督信号来学习。
在实施过程中,用以下离散时间的关系式(上:扩散过程,下:逆过程)作为扩散和逆过程。
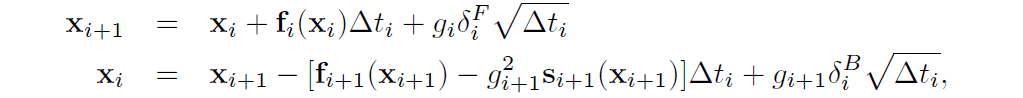
在公式中,$delta$代表从多变量标准正态分布中采样的噪声,$delta t$代表离散的时间步骤。
损失函数由扩散过程中的两个分布$p_F$和反过程中的$p_B$的KL分歧得出;DiffFlow训练函数$f,s$以使该损失函数最小。
DiffFlow在计算梯度时采取了解决内存消耗的措施,并在离散时间步长时改变间隔。欲了解更多信息,请参见原始论文。
现在我们对DiffFlow的工作原理有了大致的了解,让我们看看用这种方法生成数据的结果。
人工数据中的扩散过程。
首先,让我们看看人工数据中扩散过程的可视化结果。
下面的数字说明了DiffFlow(这种方法)、DDPM(扩散模型)和FFJORD(基于流量的模型)中从数据到潜变量的转化。在处理左右两边不同的数据环时,结果显示。
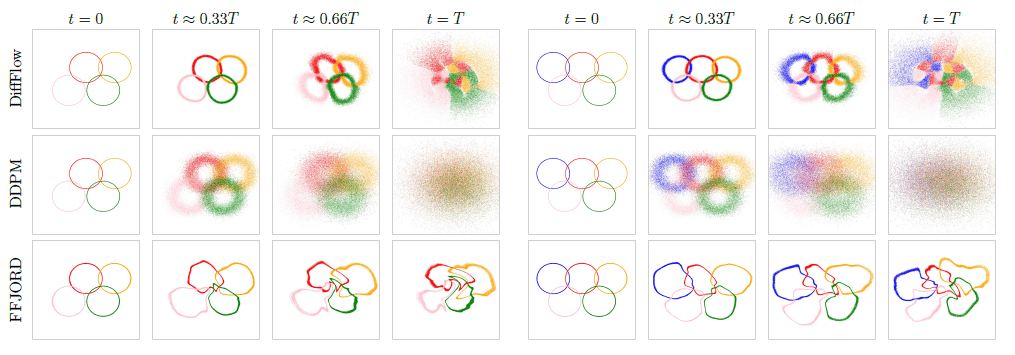
在基于流动的模型FFJORD中,在转换为潜变量后,环形的形状仍然存在,而且点不会散布在整个空间。另一方面,作为扩散模型的DDPM,最终产生的潜变量散布在整个空间,但其表现形式是一种混合模式(图中的彩色编码环)。
在DiffFlow中,在保持环状特征的同时,获取潜变量在整个空间的分布,这是基于流动的模型和扩散模型的良好结合。
在逆过程中产生人工数据。
接下来,介绍了使用反过程对人工数据的潜变量进行图像采样的结果。
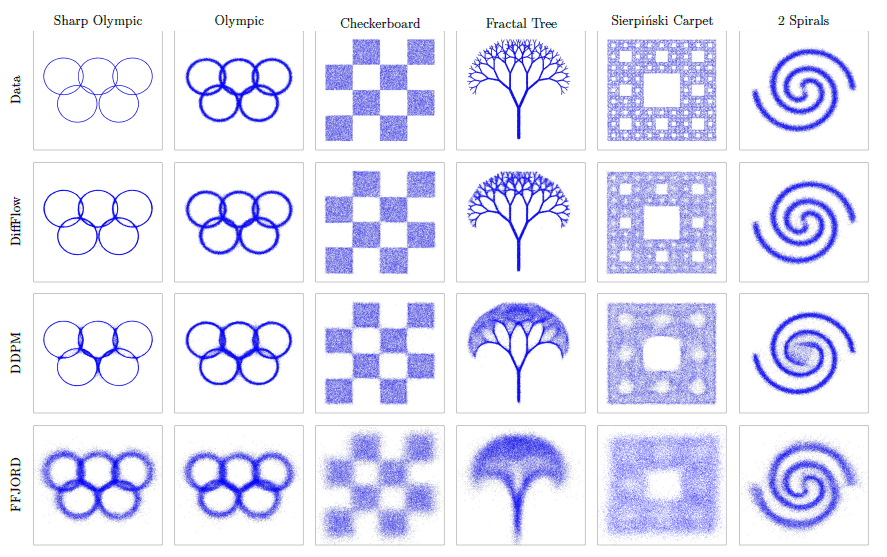
所有的模型都能生成原始数据分布,但只有DiffFlow能够捕捉到分布的精细形状。这一结果表明,DiffFlow可能能够成功地在边界更清晰的更复杂的数据集上生成数据。
结论。
它是怎样的--令人惊讶的是,DiffFlow能够重现并生成相当精细的细节?VAE和GAN作为深度生成模型现在已经被人们所熟悉,但基于流量的模型和扩散模型在未来可能会吸引更多的关注。
文中讨论到,DiffFlow的计算时间比传统的扩散模型慢,在实际应用于图像等高维数据的生成时,它似乎仍不如其他生成模型。



与本文相关的类别

![[PIDM] 物理正则化扩散模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/September2024/pidm-520x300.png)
![[LDDGAN]用于最快推理的扩散模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/September2024/lddgan-520x300.png)

![[MusicLDM] 低剽窃风险的文本到](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/January2024/musicldm-520x300.png)
![AudioLDM]使用潜在扩散的文本到音](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/January2024/audioldm-520x300.png)
![[CoDi]可处理几乎所有模式的任意扩散](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/December2023/composable_diffusion-520x300.png)