"LayerDrop "提议;Dropout层,而不是权重或节点!
3个要点
✔️ Transformer有大量的参数,需要大量的计算
✔️ LayerDrop,是一种新的层级落差,是作为模型压缩提出的。
✔️在不改变原有性能的前提下,提取不同层数的模型。
Reducing Transformer Depth on Demand with Structured Dropout
written by Angela Fan, Edouard Grave, Armand Joulin
(Submitted on 25 Sep 2019)
Comments: Accepted to ICLR2020.
Subjects: Machine Learning (cs.LG); Computation and Language (cs.CL); Machine Learning (stat.ML)
code:
首先
Transformer是机器翻译等自然语言处理中的一个关键架构,每一层的transformer都包含数百万个参数,无论是学习还是推理都需要大量的计算。
模型压缩是提取一个较小的(计算成本较低的)模型的过程,同时保持一个较大模型的性能,如变压器。模型压缩的方法主要有两种:第一种是Distillation,将原模型的输出作为有监督的数据来训练一个较小的模型;第二种是Pruning,通过去除模型中的节点和权重来减少参数的数量。修剪是一种通过删除模型中的节点和权重来减少参数数量的方法。在本文中,我们主要介绍了修剪。
本文的方法是将LayerDrop应用到变压器上,LayerDrop是Dropout的派生,Dropout忽略一定概率的节点,Dropconnect忽略一定概率的节点之间的权重,LayerDrop的优点有以下三点。
- 规范化很深的变压器和稳定学习,比其他基准表现得更好
- 测试时可以提取较小的模型,不需要调整。
- LayerDrop和Dropout一样容易实现。
技巧
选择图层
有多种方法可以选择一个层进行修剪。
每隔一段时间
最简单的方法是以恒定的概率$p$进行Pruning。在$p$处修剪意味着删除$dequiv 0(mod/frac{1}{p})$处的层。这种方法是最直观的,可以实现模型的平衡。
搜索有效
该方法通过计算Layers的各种组合来确定使用验证集提取的模型,并确定性能最好的模型。这种方法的想法很简单,但这种方法计算成本很高,而且在推理过程中可能会造成过度学习。
数据驱动的修剪
最后一种方法是学习每个Layer的Drop率:应用一个softmax函数,将Drop率$p_d$作为该Layer的参数,在推理过程中根据softmax函数的输出,只采用固定的top-k层。
在实践中,他们发现Every Other在各种任务中都很好用。其他两种方法的表现也不尽如人意。需要注意的是,在他们的实验中,并没有调整Pruning后的模型。
跌幅设置
假设原始模型有$N$组和固定的Drop率$p$,训练中使用的平均组数为$N(1-p)$。因此,如果修剪后的组数为$r$,则最优落差率$p^*$为$p^*=1-/frac{r}{N}$。他们发现,在较小的模型中,Drop率越高,性能越好。在本文的实验中,设置了$p=0.2$,但对于推理时间较小的模型,他们推荐$p=0.5$。
实验①
实验设置
我们说明了所提出的方法在各种自然语言处理任务上的有效性。
- 机器翻译
- WMT英德翻译任务
- 数据集:WMT16
- Dropout:{0.1,0.2,0.5}
- LayerDrop rate:$p=0.2$。
- 评价措施:BLEU
- 语言建模
- 数据集:Wikitext-103
- Dropout和LayerDrop率与机器翻译相同。
- 评价指标:PPL
- 概要
- 数据集:280K+新闻文章
- Dropout和LayerDrop率与机器翻译相同。
- 评价指标:ROUGE
- 问题和答案
- 数据集:ELI5
- 272K个问题和答案对
- 评级指标:红褐色
- 数据集:ELI5
- 通过先前的学习来表示文本
- 数据集:Bookscorpus+Wiki,Bookscorpus+CC-新闻+故事。
- 指标:MRPC、QNLI、MNLI。
结果①
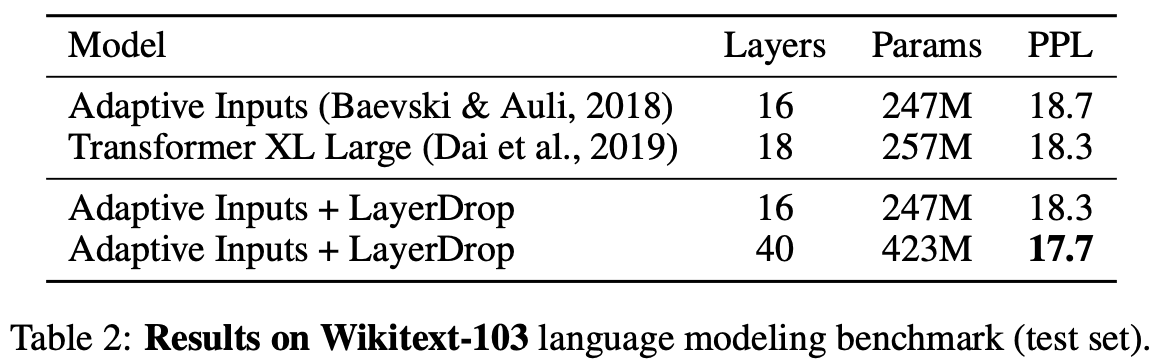
表2显示了语言建模的实验结果,显示了LayerDrop对Adaptive Inputs训练的Transformer的影响。 在16层的Transformer中添加LayerDrop可以提高0.4的PPL,与Transformer XL的最先进结果一致。在40层的变压器中加入LayerDrop,进一步提高了0.6的PPL。
Very Deep transformers的训练不稳定,使用大量内存,训练难度大,在Wikitext-103这样的小数据集上容易过度训练。 LayerDrop对网络进行了规范化处理,减少了内存的使用,提高了训练的稳定性。
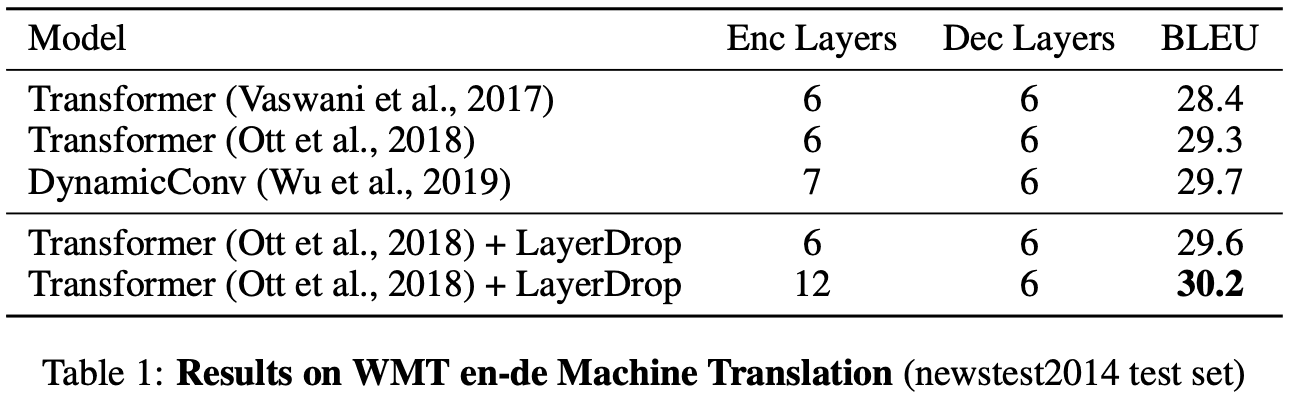
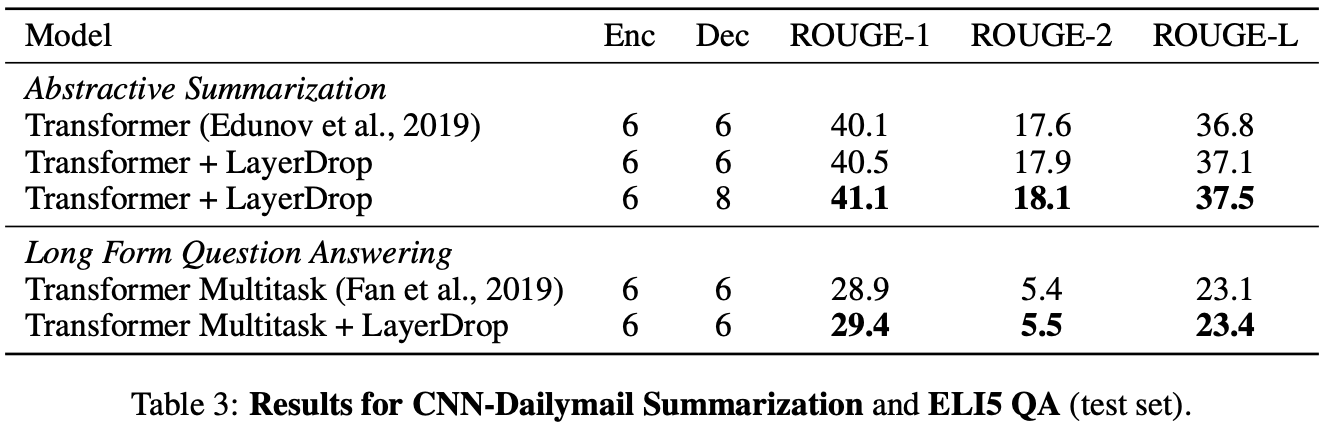
表1和表3显示了Sequence to sequence任务的结果。我们可以看到,将LayerDrop应用到机器翻译、总结和问答任务的模型中,可以提高所有任务的性能。

表4显示了前期培训的结果。同样,我们可以看到LayerDrop提高了性能。
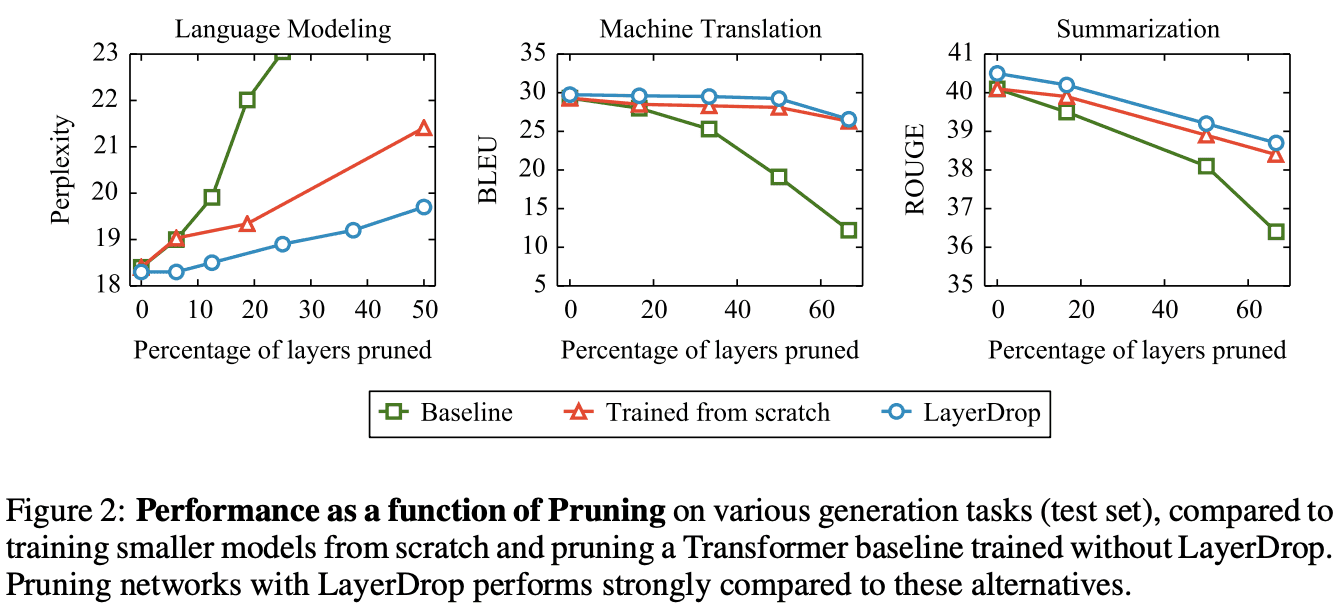
图2显示了Transformer在语言建模、机器翻译和总结方面的性能,其中横轴是需要修剪的层数,纵轴是性能。另一方面,可以看到,当从不使用LayerDrop的基线上丢弃图层时,性能会明显恶化。
实验②
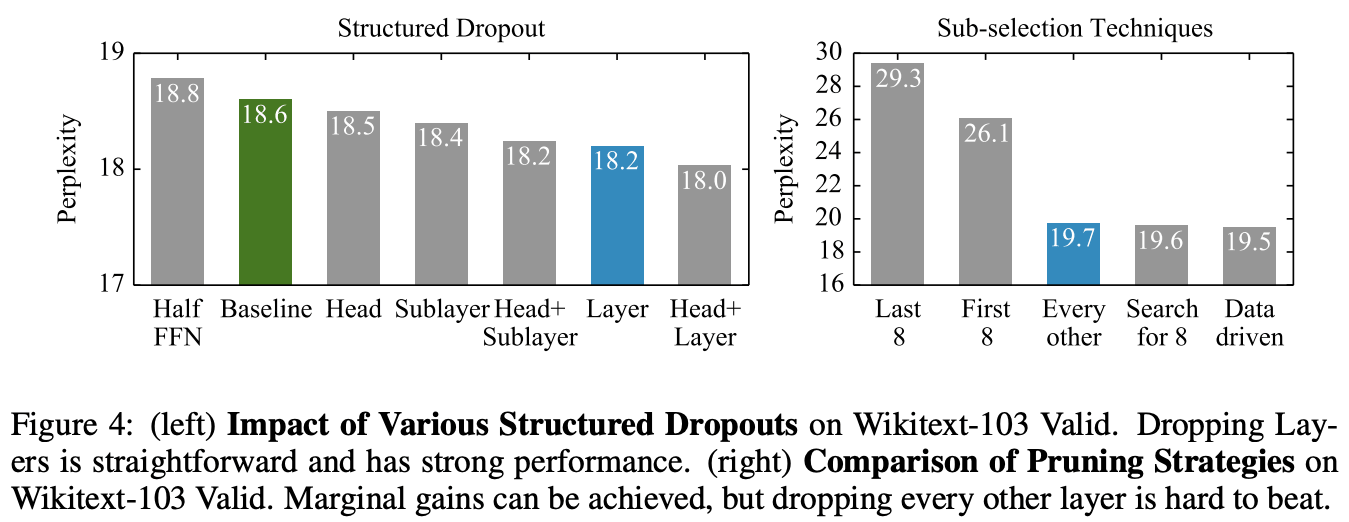
图4的左图比较了辍学目标:注意头、FFN矩阵、整个变压器,以及每种组合的结果。
图4的右侧显示了推理过程中选择模型层的方法比较。在本文中,他们使用的是一种简单的方法,叫做"Every other",但它的性能非常好。即使是通过学习搜索最优8层的方法,也只比提出的方法有很小的改进。相比之下,可以很容易地看到,从输入层丢掉8层,或者从输出层丢掉8层,都会导致性能的大幅下降。这是直观的,但可以理解的是,把系统中处理输入或预测的部分丢在一起会降低性能。
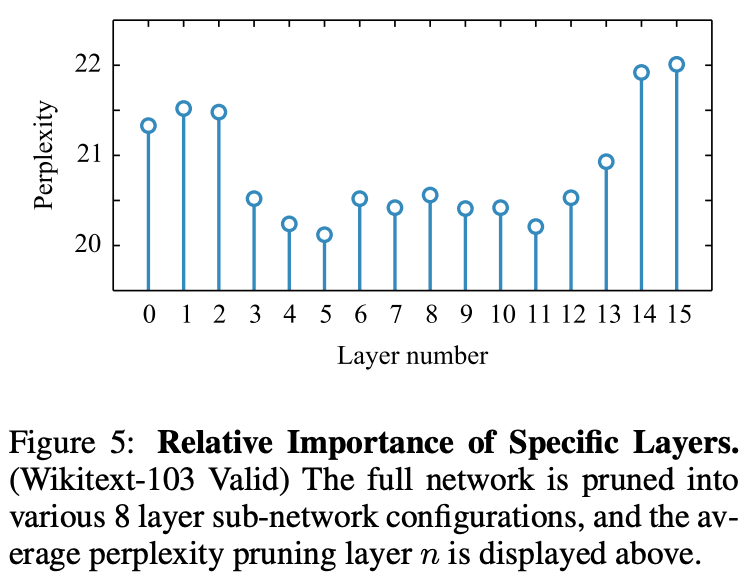 图5为实验结果,应该丢掉哪些层。从图中可以看出,靠近输入层和输出层的层是重要的层(不应该放弃)。
图5为实验结果,应该丢掉哪些层。从图中可以看出,靠近输入层和输出层的层是重要的层(不应该放弃)。
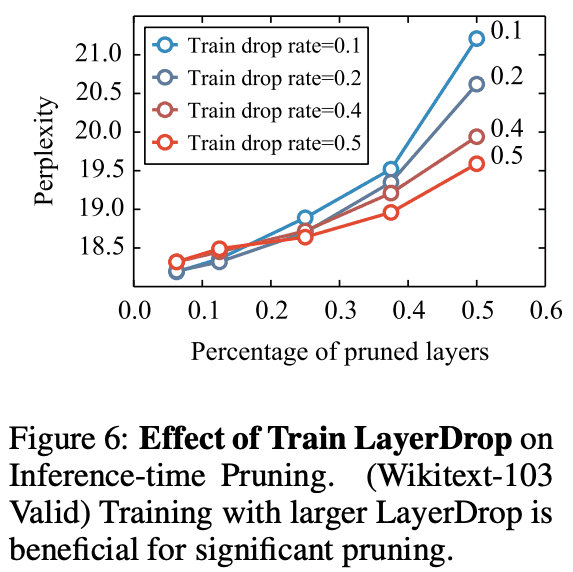 图6是掉线率和性能的对比。可见,对于深度模型来说,较高的降幅是可取的。
图6是掉线率和性能的对比。可见,对于深度模型来说,较高的降幅是可取的。
摘要
Dropout对神经网络进行规范化处理,使其变得稳健。在本文中,我们提出了LayerDrop,它特别关注Layers。我们已经证明,它可以为各种文本生成和机器翻译任务训练非常深的模型,稳定它们,并提取各种深度的模型,而且性能良好。



与本文相关的类别
