
来自文本、语音和视觉的多模态情感识别:索尼提议M2FNet!
三个要点
✔️ 利用文本、语音和视频功能实现高准确率的情感识别!
✔️ 转化器学习语料之间的关系,多头关注学习模态之间的关系!
✔️ 视频特征显示,不仅需要使用 "面部表情",还需要使用 "整个场景 "的背景。
M2FNet: Multi-modal Fusion Network for Emotion Recognition in Conversation
written by Vishal Chudasama, Purbayan Kar, Ashish Gudmalwar, Nirmesh Shah, Pankaj Wasnik, Naoyuki Onoe
(Submitted on 5 Jun 2022)
Comments: Accepted for publication in the 5th Multimodal Learning and Applications (MULA) Workshop at CVPR 2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Sound (cs.SD); Audio and Speech Processing (eess.AS)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍

上图显示了现有方法和提议的M2FNet在MELD和IEMOCAP数据集上的情感识别的准确性(加权平均F1)。现有的方法在准确性上有偏差,这取决于数据,而拟议的方法在两个数据集上都保持了较高的准确性。
本文介绍了一个用于对话中的情绪识别(ERC)任务的模型,M2FNet(多模式融合网络)。多模式方法一直被认为是困难的。相比之下,M2FNet通过利用所有三种模式的有用特征,成功地实现了高度准确的估计,并且在两个主要的ERC数据集上都实现了SoTA。主要贡献包括。
- 通过考虑多个人的面部表情特征以及整个场景的特征,从视频中提取了更多有用的特征。
- 从音频和视频中提取有用特征的自适应边际的三联体损失。
- 基于多头注意力的特征融合,将有用的音频和视觉情感相关信息映射到文本特征上。
- 在MELD和IEMOCAP基准的加权平均F1得分中取得了最高的准确度,证明了所提方法的稳健性。
现在我们来看看M2FNet。
什么是ERC?
ERC是一项基于文本、场景和语音识别对话中人类情感的任务,在多媒体内容的分析和建模方面具有潜在的应用。应用包括用户对内容的反应,为个人用户优化的对话系统,基于AI的采访和情感分析。
谈话中的情绪识别数据如下图所示。ERC的任务是估计这些情感标签。

系统定位
传统的ERC方法主要侧重于使用对话中的文本信息,而倾向于忽略其他两种模式。这限制了对情绪的分析,因为语言和视觉信息没有被考虑在内。ERC数据包括三种模式:文本、视频和音频,因此没有理由不利用它们。本文提出了一个模型,其动机是多模态方法可以提高情绪识别的准确性。在现有的方法中可以找到多模态的方法,但本文提出了几种机制,以更好地提取和结合每种模式的特征。
大图片
第一步是介绍M2FNet的整体情况。

因为有三种模式,所以看起来很复杂,但如果你一个一个地看,就可以理解。
处理的数据由一组语料U和每个语料的情感标签Y组成 U中的每个数据xi由三种模式(文本、音频和视频)组成,每个语料xi都有一个情感标签yi 一个对话由k个语料组成。
![]()
该模型分为两个主要阶段。前半部分,即语料层面,对每个语料(说话人内部)和每个模式独立进行特征提取。下半部分,对话层面,在提取的语料之间(说话人之间)提取特征,并捕捉上下文信息。然后提取模式之间的关系,并估计出最终的情绪标签。
语料级特征提取
在进入对话层之前,首先在语料层单独提取每个语料和模式的特征。这是对每个文本、语音和视频分别进行的。讲话和视频很重要。

文本特征
文本特征是通过微调修改过的RoBERTa,一个大规模的自然语言模型来提取的。文本不是严格意义上的每个语词的输入,而是包括前后的语词,由分离标记<S>分开。获得的文本特征是DT维度的。
![]()
特征提取器模块
独特的模型被用于音频和视频特征提取,而不是现有的模型。学习机制是基于具有自适应边际的三重损失。
 该机制是基于FaceNet人脸识别模型的Triplet Loss。我们想得到的是能够区分每个人的各种面部表情、场景和声音的特征。首先,准备好一个图像特征(锚)、一组具有相同标签的样本(正)和一组具有不同标签的样本(负),并对Triplet Loss进行训练,使正样本在特征空间中更靠近,负样本更远离。在ERC中,通过将具有相同情感标签的样本拉近,并将其他样本移开,可以获得有用的特征。所提方法的三倍损失如公式所示。
该机制是基于FaceNet人脸识别模型的Triplet Loss。我们想得到的是能够区分每个人的各种面部表情、场景和声音的特征。首先,准备好一个图像特征(锚)、一组具有相同标签的样本(正)和一组具有不同标签的样本(负),并对Triplet Loss进行训练,使正样本在特征空间中更靠近,负样本更远离。在ERC中,通过将具有相同情感标签的样本拉近,并将其他样本移开,可以获得有用的特征。所提方法的三倍损失如公式所示。
![]()
一项是带有自适应边际的三重损失,两项是特征的方差项,三项是协方差项,λ是各自的权重。
Triplet Loss从一个大的样本集中选择对训练特别有用的样本。适合训练的样本是那些锚点和正点之间的距离Dap大于负点之间的距离Dan(硬)且Dap-Dan>0的样本。如果Dap从一开始就明显较小,那么优化的意义就不大。在这种情况下,Triplet Loss有一定的余量m,如果Dap-Dan-m>0,它也会被学会(半硬)。然而,在FaceNet中,保证金有一个固定的值,所以如果正片和负片与Anchor的距离相近,损失就接近于零,学习就不会有进展。因此,M2FNet提出了基于自适应边际的三倍损失,它使用基于特征距离的自适应边际。
![]()
自适应余量由基于特征间距离的相似性/不相似性确定,具体如下。这允许更灵活地从音频和视频中学习与情感标签有关的特征。
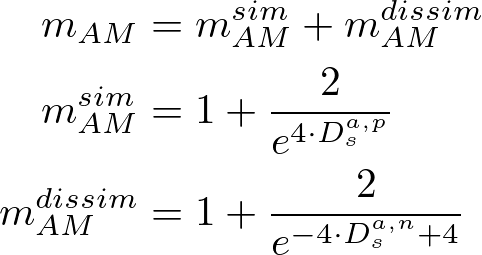
第二个项是分散项,以防止模式崩溃,第三个项是协方差项,以减少维度之间的相关性。
%3B%5C%3BZ_k%3DZ_a%2CZ_p%2CZ_n%5C%3B%5Cleft(L_%7BVar%7D(Z_k)%3D%5Cfrac%7B1%7D%7Bd%7D%5Csum_%7Bj%3D1%7D%5Ed%201-%5Csqrt%7BVar(Z_%7B%3A%2Cj%7D)%2B%5Cepsilon%7D%5Cright)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
%3B%5C%3BZ_k%3DZ_a%2CZ_p%2CZ_n%5C%3B%5Cleft(L_%7BCov%7D(Z_k)%3D%5Cfrac%7B1%7D%7Bd%7D%5Csum_%7Bi%5Cneq%20j%7D%20Cov(Z_%7Bk%7D)_%7Bi%2Cj%7D%5ET%5Cright)%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
音频和视频的处理方式有些不同,让我们来详细了解一下。
语音特征
在2021年ICCV的一篇论文中显示,当把绘制频率响应的熔体频谱图作为图像而不是信号本身来处理时,使用语音数据的情感识别更加准确。受此启发,M2FNet也将语音作为图像进行特征提取。首先,应用时间扭曲和加性白高斯噪声(AWGN),然后转换为熔融谱图。
Mel-spectrogram是通过设置局部时间窗口并对每个窗口应用短时傅里叶变换(STFT),在RGB的横轴上绘制时间,纵轴上绘制频率的特征。这将通过前面描述的特征提取器来获得每个语料i的语音特征。
![]()
视频功能
视频特征的获得是通过从视频中每一帧对应的语词中提取特征,并跨帧合并;M2FNet提出了一个双网络,不仅使用一个人的面部表情,还使用跨帧的特征来捕捉上下文,以便提取更多与情绪有关的特征。

第一步是面部表情特征(加权面部模型)。对于对应于话语i的15个连续帧,首先通过将每一帧输入多任务级联卷积网络(MTCNN)来检测人脸。由于检测到的人脸有多张,由上述特征提取器得到的每个面部特征的加权和被用作特征值。bbox的面积被用来作为权重。通过对面积进行归一化处理,并将其保持在[0,1]的范围内作为权重,更加强调每一帧中被强调的表达。15个框架的表情特征通过Max-pooling得出每个语料i的表情特征,然后将15个框架的表情特征作为每个语料i的表情特征的权重。
%3D%5Csum_%7Bj%5Cin%20%5Cmathrm%7BMTCNN%7D(x_v%5Ei)%7D%20%5Cmathrm%7BFaceModel%7D(x_%7Bvj%7D%5Ei)%5Ccdot%20%5Cmathrm%7BArea%7D(x_%7Bvj%7D%5Ei)_%7B%5Cmathrm%7Bnormalized%7D%7D%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f) 随后是场景特征(场景嵌入)。场景特征很简单:每一帧通过一个特征提取器,并使用Max-Pooling对15帧进行压缩。从这两个网络获得的特征被结合起来,形成最终的视频特征。因此,如果我们敢于制定方程,则如下所示。
随后是场景特征(场景嵌入)。场景特征很简单:每一帧通过一个特征提取器,并使用Max-Pooling对15帧进行压缩。从这两个网络获得的特征被结合起来,形成最终的视频特征。因此,如果我们敢于制定方程,则如下所示。
![\begin{align*}
F_{IV}^i=\mathrm{Concat}\left(
&\mathrm{Maxpool_{15frames}}(\phi_{Scene}(x_v^i)),\\
&\mathrm{Maxpool_{15frames}}(\phi_{WF}(x_v^i))
\right)\;|\;i\in[1,k],\; \forall F_{IV}\in\mathbb{R}^{k\cdot D_v}
\end{align*}](https://texclip.marutank.net/render.php/texclip20221227205222.png?s=%5Cbegin%7Balign*%7D%0A%20%20%20%20F_%7BIV%7D%5Ei%3D%5Cmathrm%7BConcat%7D%5Cleft(%0A%20%20%20%20%26%5Cmathrm%7BMaxpool_%7B15frames%7D%7D(%5Cphi_%7BScene%7D(x_v%5Ei))%2C%5C%5C%0A%20%20%20%20%26%5Cmathrm%7BMaxpool_%7B15frames%7D%7D(%5Cphi_%7BWF%7D(x_v%5Ei))%0A%20%20%20%20%5Cright)%5C%3B%7C%5C%3Bi%5Cin%5B1%2Ck%5D%2C%5C%3B%20%5Cforall%20F_%7BIV%7D%5Cin%5Cmathbb%7BR%7D%5E%7Bk%5Ccdot%20D_v%7D%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
以这种方式获得的每个语料i的文本、音频和视频特征现在被用于对话级特征提取器。
对话层面的特征提取
从这里,k个语料之间的关系是在逐个对话的基础上提取的,也就是k个语料。
学习话语之间的关系
首先,为每种模式学习语料之间的关系。每种模式的K维和D维特征FIT、FIA和FIV被输入到几个变换器编码器。
 为了避免忽略低级别的特征,变形金刚通过跳过连接的方式相互连接。该文件将此描述为以下公式。
为了避免忽略低级别的特征,变形金刚通过跳过连接的方式相互连接。该文件将此描述为以下公式。
![\begin{align*}
F_T^i=Tr_{N_T}(...(Tr_{N_2}(Tr_{N_1}(F_{IT}^i)))),\\
F_A^i=Tr_{N_A}(...(Tr_{N_2}(Tr_{N_1}(F_{IA}^i)))),\\
F_V^i=Tr_{N_V}(...(Tr_{N_2}(Tr_{N_1}(F_{IV}^i)))),\\
\mathrm{where},\;i\in[1,k]
\end{align*}](https://texclip.marutank.net/render.php/texclip20221227210826.png?s=%5Cbegin%7Balign*%7D%0A%20%20%20%20F_T%5Ei%3DTr_%7BN_T%7D(...(Tr_%7BN_2%7D(Tr_%7BN_1%7D(F_%7BIT%7D%5Ei))))%2C%5C%5C%0A%20%20%20%20F_A%5Ei%3DTr_%7BN_A%7D(...(Tr_%7BN_2%7D(Tr_%7BN_1%7D(F_%7BIA%7D%5Ei))))%2C%5C%5C%0A%20%20%20%20F_V%5Ei%3DTr_%7BN_V%7D(...(Tr_%7BN_2%7D(Tr_%7BN_1%7D(F_%7BIV%7D%5Ei))))%2C%5C%5C%0A%20%20%20%20%5Cmathrm%7Bwhere%7D%2C%5C%3Bi%5Cin%5B1%2Ck%5D%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
学习和结合各种模式之间的关系。
然后提取模式之间的关系,并将其合并为对话级特征。首先,这三个特征被输入到融合注意模块,该模块由多头注意组成。在这里,视频和音频特征被映射到文本特征空间,使用文本特征Ft作为查询/值,视频特征Fv和音频特征Fa作为关键 注意,Ft使用前一层的特征,但Fv和Fa保持不变。
最后,通过将映射的文本特征与Fv和Fa相结合,除了前面所述的关系提取外,还直接使用视频和语音特征。这就产生了整个语篇和整个语态的最终特征。

最后,情绪标签通过两个全耦合层最终输出。损失是交叉熵,假设每M个对话有k个语料,并且从C个情感标签中分配一个情感。
%0A%5Cend%7Balign*%7D&f=c&r=300&m=p&b=f&k=f)
实验
该实验以MELD和IEMOCAP作为ERC的基准,比较了消融和SoTA。两者都是由文本、视频和音频数据组成的多模态数据集。
数据集
MELD由电视连续剧《朋友》中的1,400多段对话和13,000句话组成。这些话语被赋予了愤怒、厌恶、悲伤、喜悦、惊讶、恐惧和中性这七个情绪标签中的一个。预先准备好的Train/Valid被原样使用。
IEMOCAP是一个包含约12小时对话的数据库;有快乐、悲伤、中立、愤怒、兴奋和沮丧六种情绪标签,在实验中,从训练数据中随机选择10%的数据用于调整超参数这些数据被用来调整超参数。
设置
AdamW是用来训练的。除非另有提及,对话层中的变压器编码器NT、NA和NV的数量根据经验设定为:MELD为1,IEMOCAP为5,MHAF两层m为5。
对于音频数据机制,特征提取器是在每个数据集的mel-spectrogram上训练的,而视频数据是在一个单独的人脸识别数据集--CASIA webface数据库上预训练的。对于音频和视频数据来说,三联体损失的系数λ1、λ2和λ3分别为20、5和1。
估值指数
估计情感标签的准确度和加权平均F1分数。
消融
消融研究了多模态的贡献,转化器编码器和融合。首先是方式。下表显示了在只使用一种模式、结合两种模式和结合三种模式时,文字、视觉和音频三种模式的准确性。特别是,最下面的那个不是简单的组合,而是融合注意模块,它是拟议方法的一部分。表中显示,当所有三种模式都被使用时,准确率更高,此外,通过使用所提出的方法的融合机制,准确率大大提高。

随后是视频专题。由于只有视频特征有一个相当复杂的机制,使用场景特征和面部表情特征,消融证实了这个双网络的有效性。对三种方法--仅有场景特征、仅有面部表情特征和结合两者的拟议方法--的比较表明,拟议方法具有最高的准确性,如表所示。看到每个嵌入本身并不能提高准确率,可以看出,来自场景的上下文信息和面部表情特征对情绪识别都很重要。

融合前的变压器编码器的数量也在NA=NV=NT中得到了验证。结果显示,当采用一层时,MELD具有较高的准确性,而当采用五层时,IEMOCAP具有较高的准确性。

最后一步是验证融合机制的几米。可以看出,当采用五层时,这里达到了最佳精度。除非另有提及,这些参数是在消融过程中以最高精度设置的。

与SoTA的比较
本文将M2FNet与基于文本和多模态的SoTA模型进行比较,以证明其优越性。首先是基于文本的模式。它在这两个数据集上的表现都优于传统方法,MELD比传统的EmotionFlow的准确率高0.21%,IEMOCAP比传统的DAG-ERC的准确率高1.83%.虽然许多方法在IMOCAP上取得了高准确率,但在MELD上的准确率较低,而提出的方法这两种方法都能达到很高的精度。

接下来是多模式方法:MELD和IEMOCAP都取得了比传统方法更高的准确性结果。准确度的提高对MELD来说尤其显著。

实验表明,M2FNet成功地利用了多模态的特征,提高了情感识别的准确性。
印象
这篇论文很好地体现了这种方法的优越性,它充分利用了三种模式。从实际情况来看,我觉得对基于文本的方法有更大的需求。例如,在社交网络和口碑的分析中,应该只要求文本特征的准确性。在我看来,只有有限的数据量,其中视频、音频和文本都可以使用。即便如此,只要有数据,该方法的稳健性就得到了证明,它在两个基准中取得了很高的准确性,所以我觉得这是一个很有前景的方法。
我们期待着情感识别的应用,这也是索尼宣称的创造力的独特之处。
摘要
在这篇文章中,我们介绍了M2FNet,它在对话中的情感识别ERC中取得了很高的准确率。M2FNet充分地利用了ERC数据集中提供的语音、文本和视频三种模式的特征,分两个阶段--话语水平和对话水平--来进行识别。每个语态的特征提取、语态间的特征提取和语态间的特征提取都是分阶段进行的。我们已经表明,在视频特征方面,不仅要使用面部表情,还要使用整个场景特征。实验比较了基于文本和多模态的方法,并在两个基准上成功实现了SoTA。CVPR还有补充材料,我们鼓励你阅读。我们期待着未来的发展。



与本文相关的类别

