Group-CAM: Grad-CAM已经过时了吗?最先进的CNN中的循证方法
三个要点
✔️ 包括一个消除特征图中噪音的机制
✔️ 能够快速推断出显著性地图
✔️ 尽管在一些实验中计算成本较低,但仍实现了SOTA的目标。
Group-CAM: Group Score-Weighted Visual Explanations for Deep Convolutional Networks
written by Qinglong Zhang, Lu Rao, Yubin Yang
(Submitted on 25 Mar 2021 (v1), last revised 19 Jun 2021 (this version, v4))
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
近年来,基于深度学习的图像识别模型已被迅速用于自动驾驶和医疗诊断。然而,许多人对实施这些方法犹豫不决,因为它们是黑箱方法,决策的依据不为人知。然而,许多人对采用这些方法犹豫不决,因为它们是黑箱方法,可能导致严重的问题。
为了解决这些问题,我们开发了技术来解释深度学习模型的决策基础,称为可解释的人工智能(XAI近年来,这一点已经变得越来越重要。
计算机视觉中广泛使用的一个XAI是显著性地图。这是一个热力图,根据其重要性,突出显示决策所依据的像素。例如,假设下面的狗和猫的图片被输入到一个经过训练的图像分类模型中,它将它们识别为狗。在这种情况下显著性地图显示图像中更多的证据和重要部分用红色突出显示。在这张图片中,我们可以看到,狗嘴周围的区域是图片的基础。

在这个领域有两种主要的方法,而Group-CAM是一种克服了两者缺点的方法。
- 基于区域的咸度方法
- 基于激活的显著性方法
基于区域的咸度方法
这个系列的方法将目标图像作为输入到一个带有掩码的训练模型中,并确定像素和超级像素的重要性。RISE使用蒙特卡洛方法来确定每个像素的重要性,使用成千上万的随机生成的掩码。其他方法包括分数-CAM和XRAI是可用的。
然而,它的计算成本很高,因为它需要生成和推断成千上万的掩码。用于推理RISE和XRAI据本文报道,推断一个面具需要大约40秒。
基于激活的显著性方法
这个系列的方法使用模型骨干中的特征图来推断出突出性图。基本上,经常使用最后一层的特征图。推理过程是确定特征图的每个通道的权重,对它们进行加权,在通道的方向上进行加法,将它们放大并与输入图像相结合。在这一研究思路中,如何进行加权往往是讨论的重点。
其中一个最著名的方法是Grad-CAM。权重是通过对与最后一层的特征图相关的梯度应用全局平均集合(GAP)来确定的。
然而,问题是,权重不能正确评估特征图的重要性,而特征图本身含有噪声,因此包括不重要的部分。

论文摘要
Group-CAM是一种可以解决上面提到的以下问题的方法。
- 基于领域的方法计算成本高
- 基于激活的方法中包含噪声的问题
整体架构如下
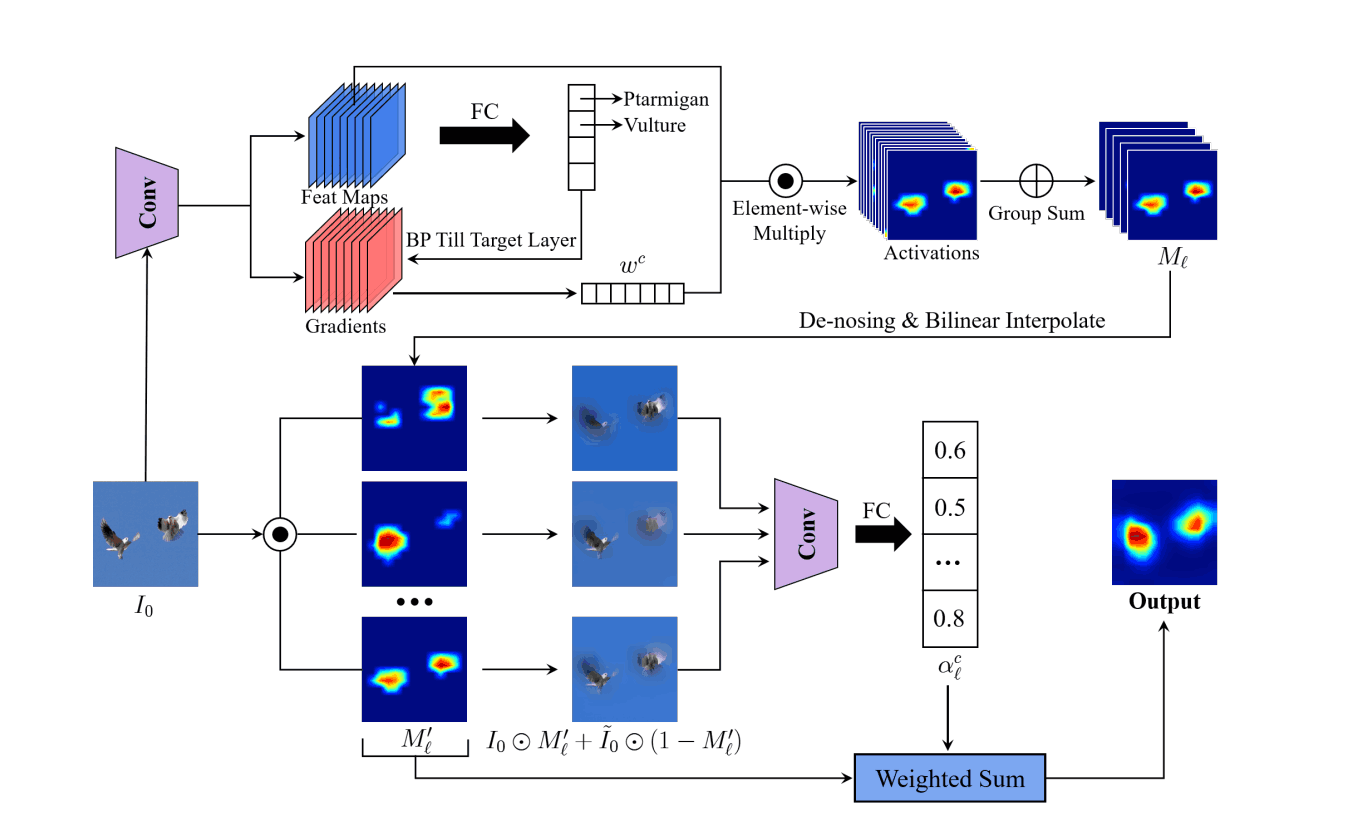
推理有三个阶段。
- 确定特征图的权重
- 特征图去芜存菁
- 确定分组特征图的权重,并创建一个显著性地图
步骤1.确定特征图的权重
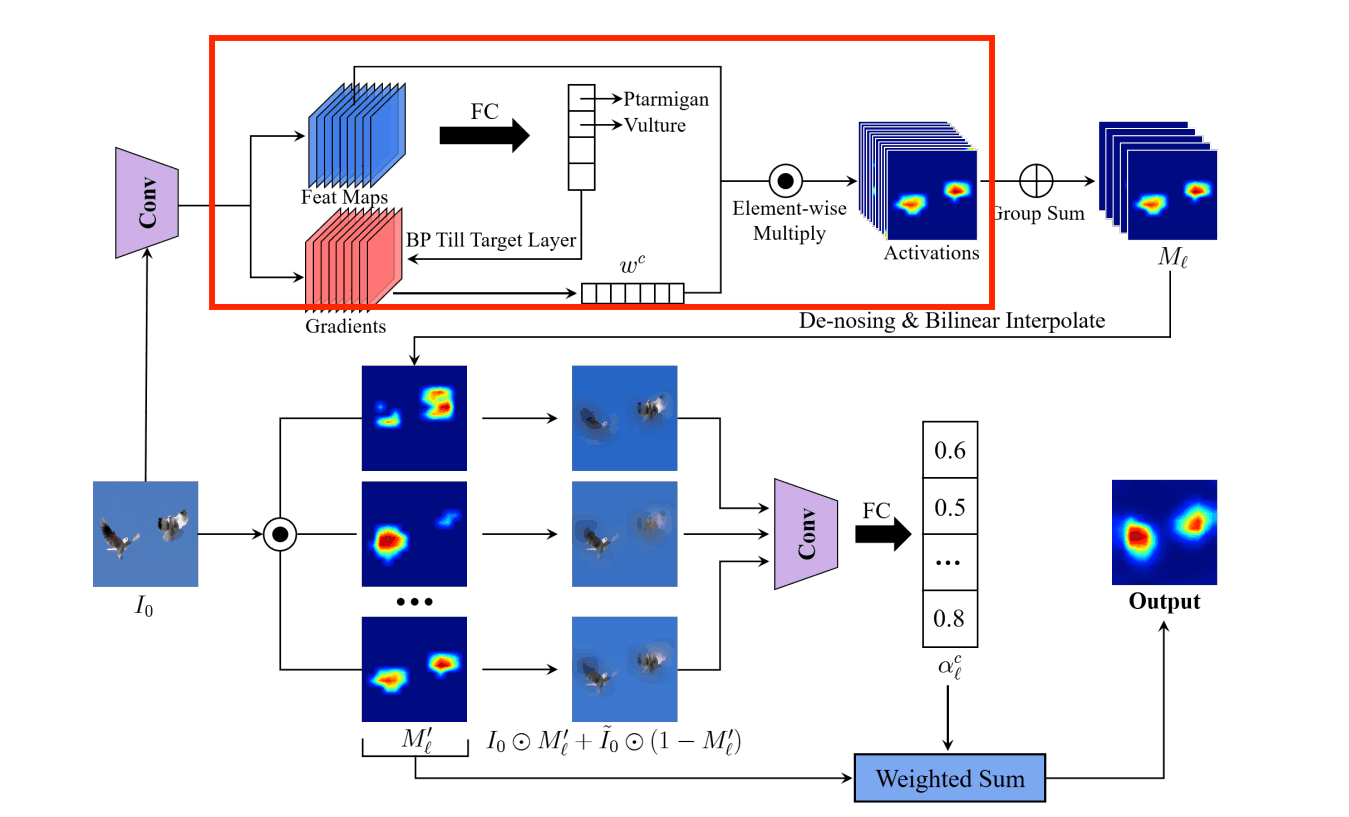
我们正在做的是毕业生-CAM与首先,你想依据的图像被输入到训练好的模型中,卷积层中的特征图被保留。然后,我们用误差反向传播法计算卷积层的梯度,以获得分类结果。
全局平均池化(GAP)被应用于该梯度,以计算通道数维度的权重。wkc,第k卷积层中通道c的权重,可以用以下公式表示
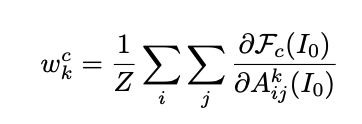
输入图像。 I0
第k个卷积层特征图. Aijk
Fc(I0):预测的c类概率
i,j: 高度和宽度
Z:Ak中的像素数的像素数。
第二步,对特征图进行去噪处理
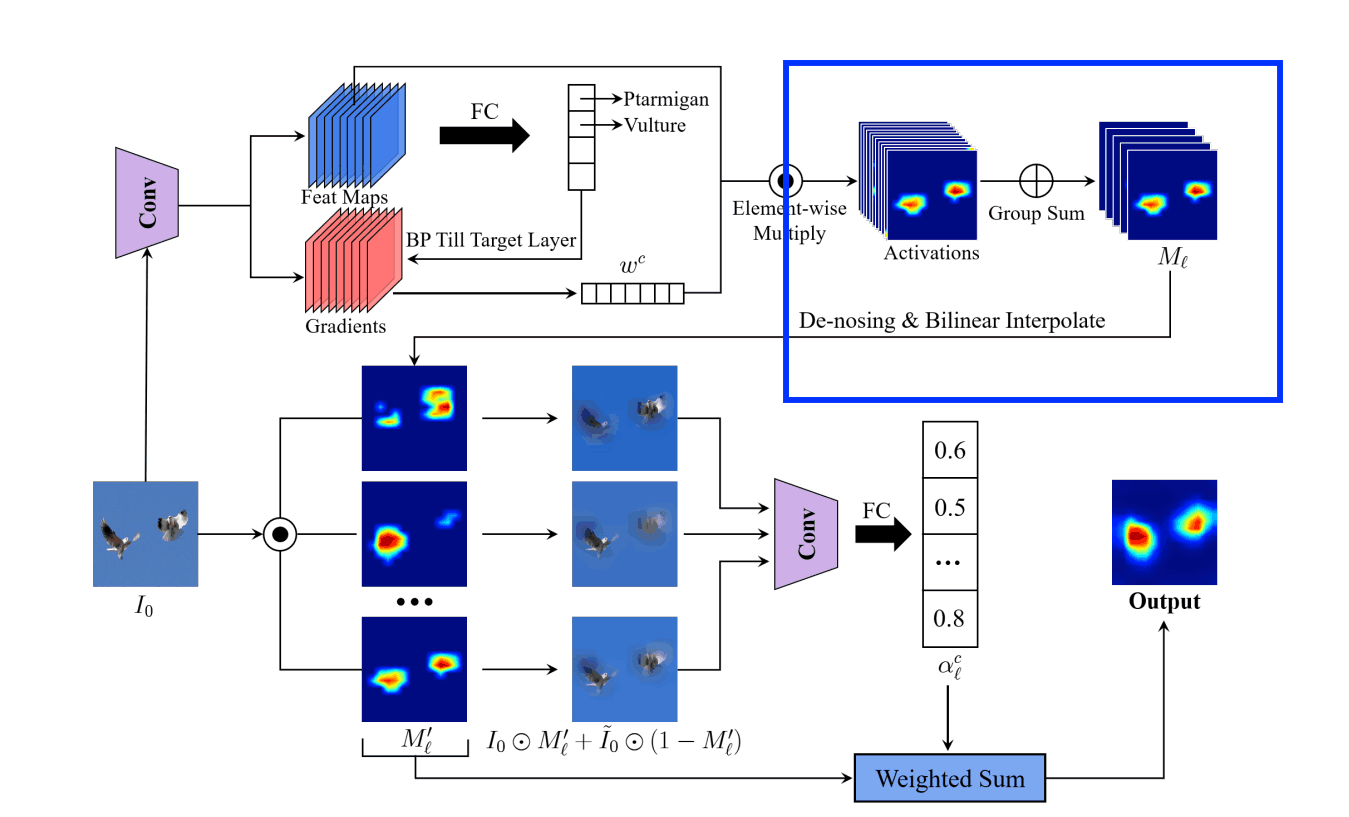
在这里,我们做两件事。
- 将步骤1中得到的特征图分为G组,并将其合并为G个特征图。
- 对汇总的特征图进行去噪和规范化处理
将步骤1中得到的特征图分为G组,并将其合并为G个特征图。
分组的方式是ǞǞǞ相邻的特征图被分组,其方式与
归纳的特征Ml表示如下
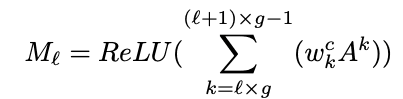
K: 通道数量
g=K/G:组内特征图的通道数量
从汇总的特征图中去除噪音
将较低的θ%的像素去噪为零。
应用于Ml的mij像素的去噪Φ表示如下
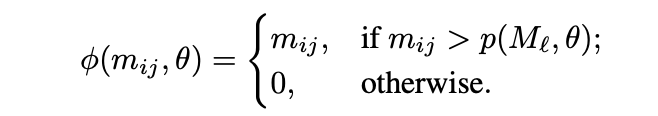
p(Ml,θ):下限为θ%的像素的上限。
,然后将图像归一化为[0,1]范围,并通过双线性插值将其放大到输入图像的大小。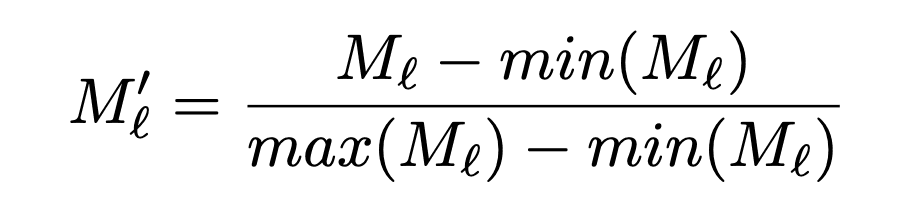
第3步:确定分组特征图的权重,并创建一个突出性地图
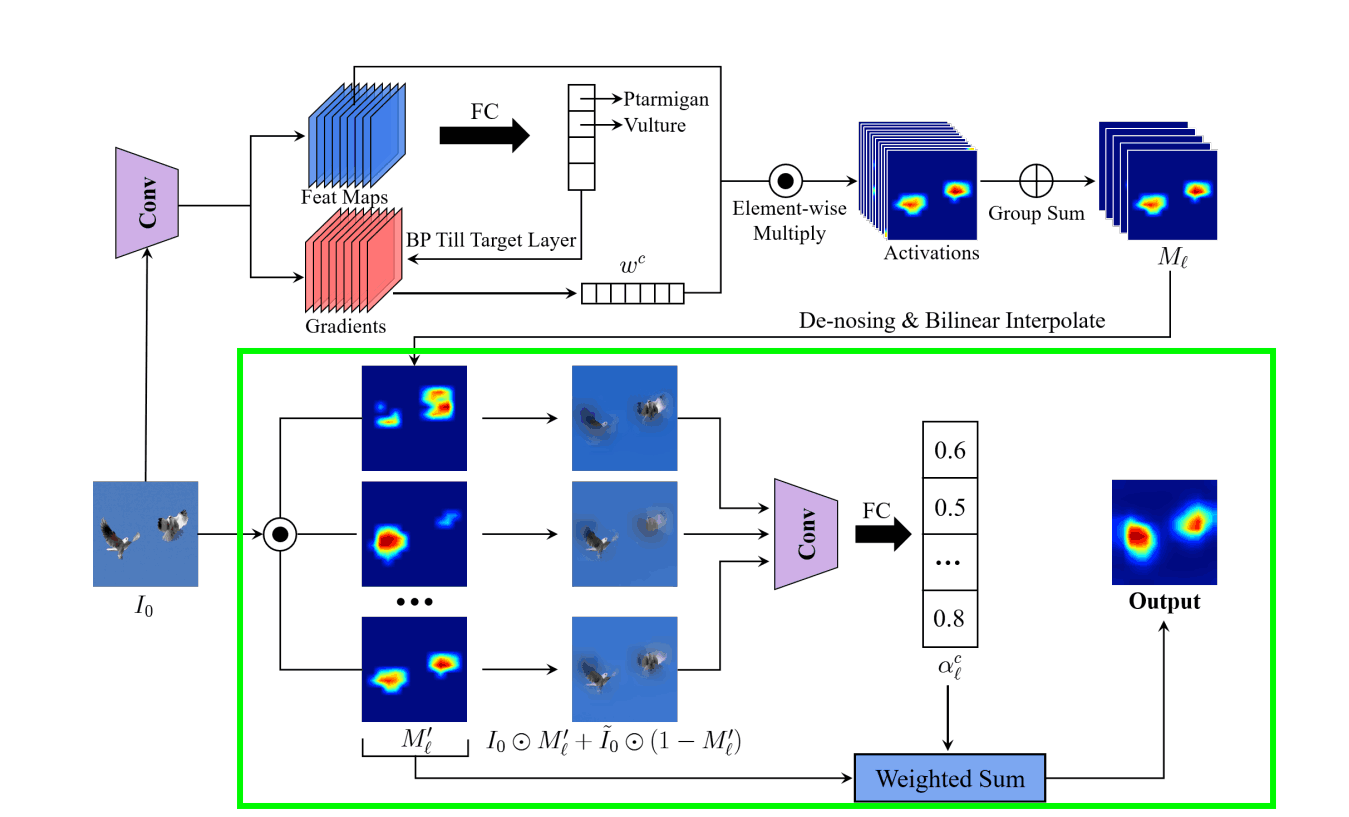
将归一化的特征图Ml'作为一个掩码应用于原始输入图像Io,并加入高斯模糊的ĩo。添加这一点的原因是,单单是被屏蔽的输入图像可能会产生敌对的效果。
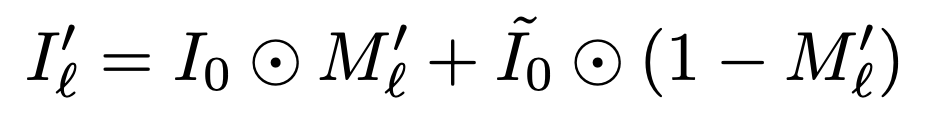
我们现在所做的和RISE中一样。我们推断出被遮蔽的输入图像在c类中的预测概率G,并取其与ĩo输入图像的c类预测概率之差。
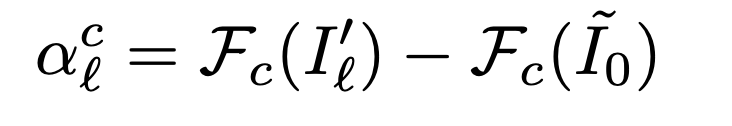
然后用alc对第l个汇总的特征图进行加权,产生一个热图。
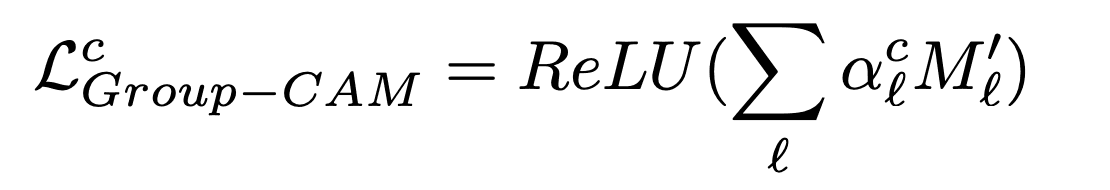
实验
阶级鉴定的可视化
中间和右边的图片显示了torchvision的训练模型VGG19以46.06%的置信度识别斗牛獒(狗)和以0.39%的置信度识别虎猫时的原理。正如你所看到的,尽管虎皮猫的置信度很低,但其原理是可以解释的。

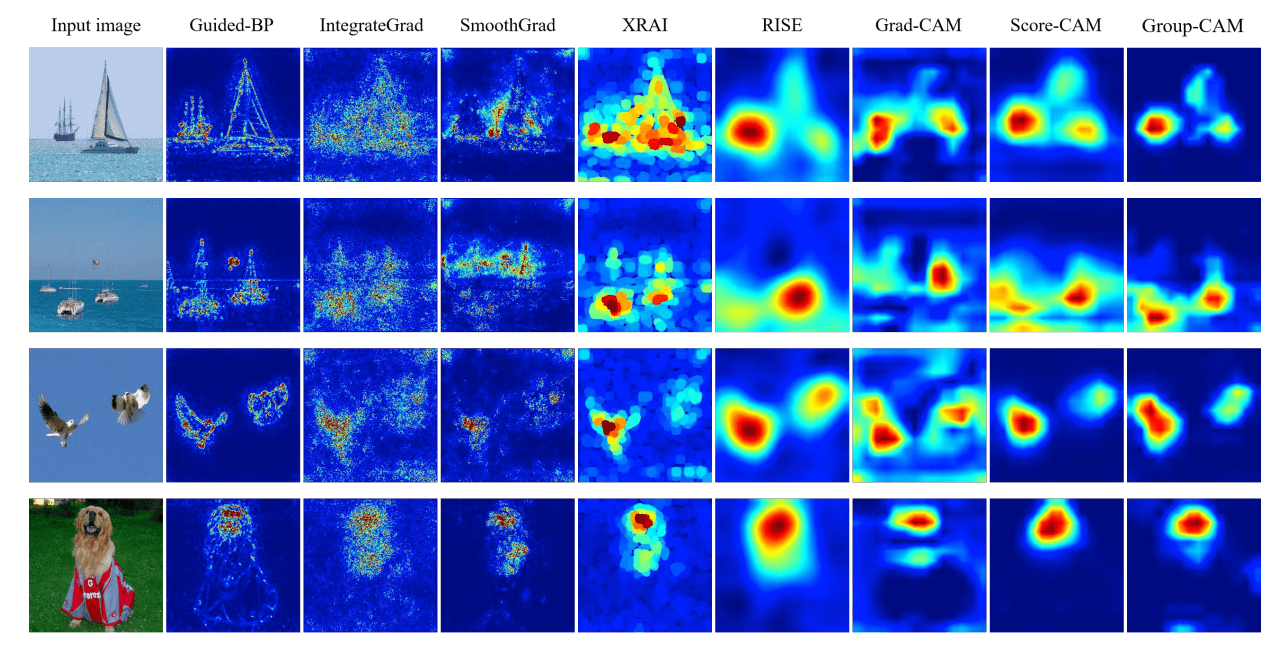
下图将Group-CAM与其他达到SOTA的方法进行了比较,显示Group-CAM的噪音比其他方法小。
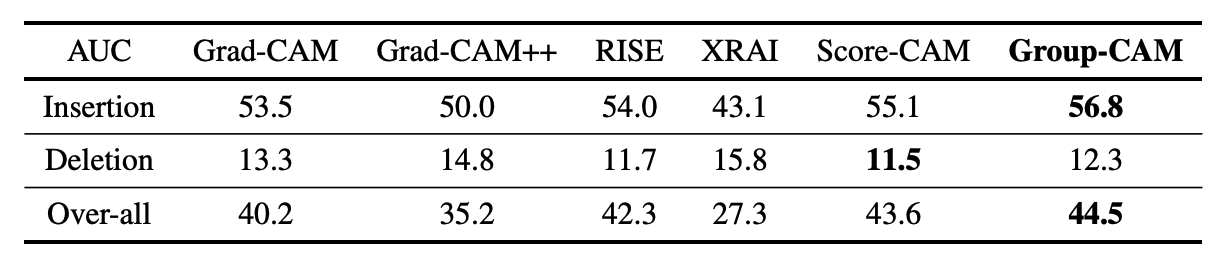
删减和插入试验
RISE以下是作者提出的删除和插入测试的结果
开发这种方法的原因是,如果突出度地图的最重要部分位于人类注释的边界框上,那么CNN中的XAI被认为表现良好,但这并不总是如此,因为CNN可能考虑到背景然而,这并不总是如此,因为CNN可能会考虑到背景。
对于删除测试,我们用模糊的像素替换热图中最重要的部分,增量为3.6%,直到显著性地图消失,用曲线下面积(AUC)作为衡量标准,纵轴是预测的类的概率。
在插入测试中,根据突出性地图的重要性,将模糊的图像添加到原始图像中3.6%,并以纵轴上的类的预测概率的图形面积(AUC:曲线下面积)作为衡量标准。
对于删除试验,AUC越低越好,因为预测概率的突然下降被认为是更重要的决策依据;对于插入试验,AUC越高越好,因为预测概率的突然上升被认为是更重要的决策依据。
可以看出,Group-CAM的整体效果最好。总的评分值计算为AUC(插入)-AUC(删除)。
检测和评估
评估是在数据集MS COCO2017 val2017上使用训练好的模型Resnet-50进行的。评估是通过将物体边界框上的任何突出像素作为一个Hit来进行的,性能值是所有类别的平均值。
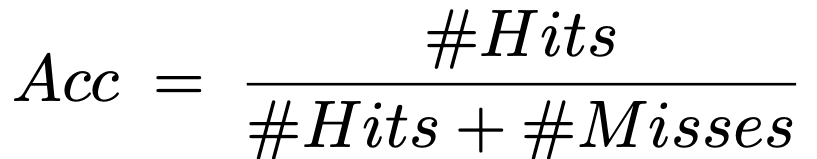
在我们的实验中,我们得到的结果比Grad-CAM高0.8%。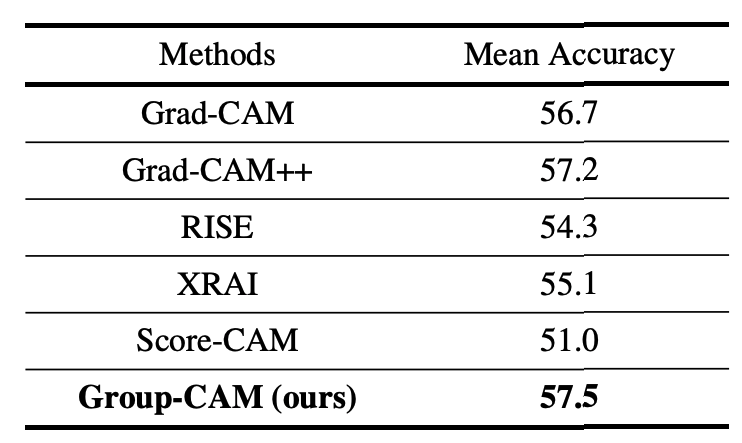
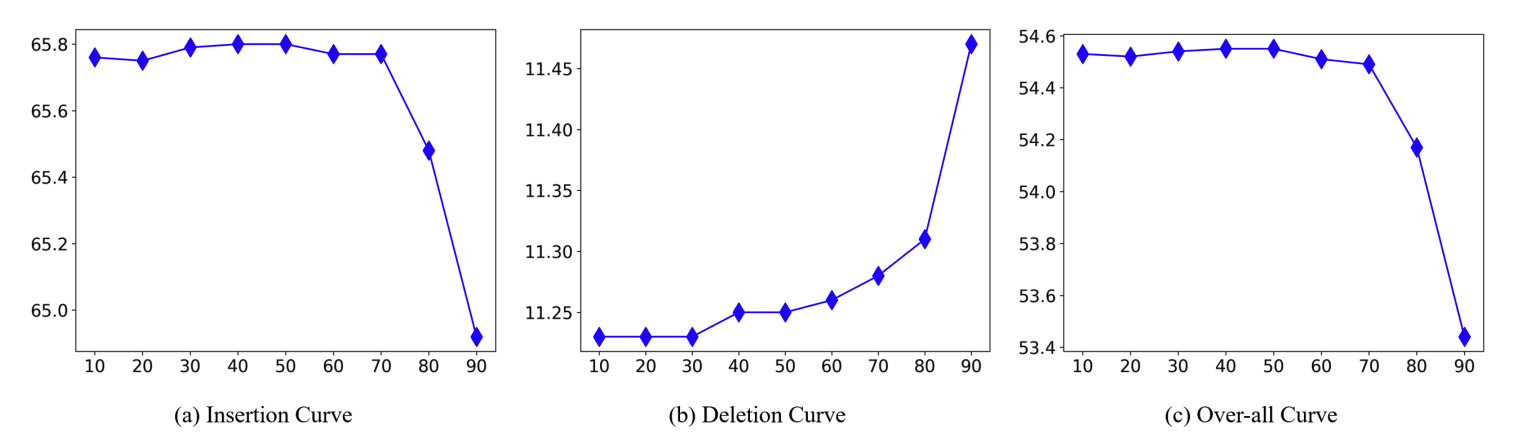
去噪超参数θ
研究发现,当θ低于70时,AUC是恒定的,当θ高于70时,AUC突然下降。
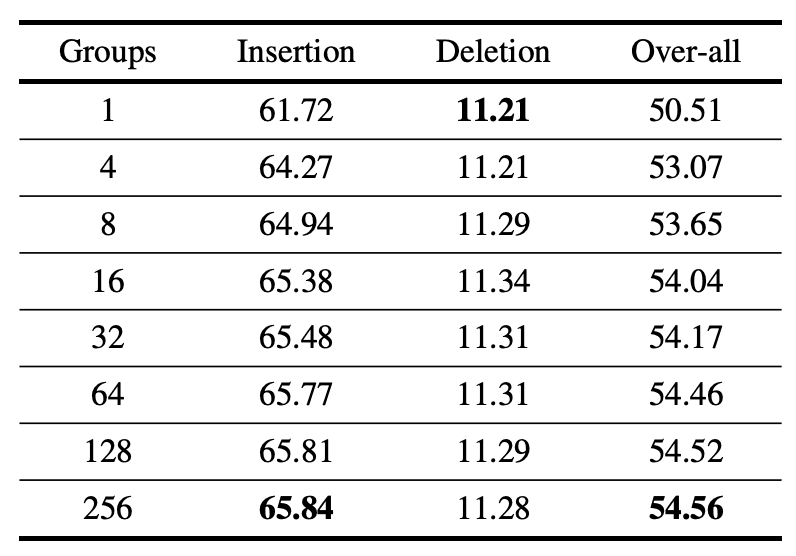
组数G
我们发现,G增加得越多,总的AUC值就越高。然而,增加G会增加计算成本,所以我们在实验中使用32。
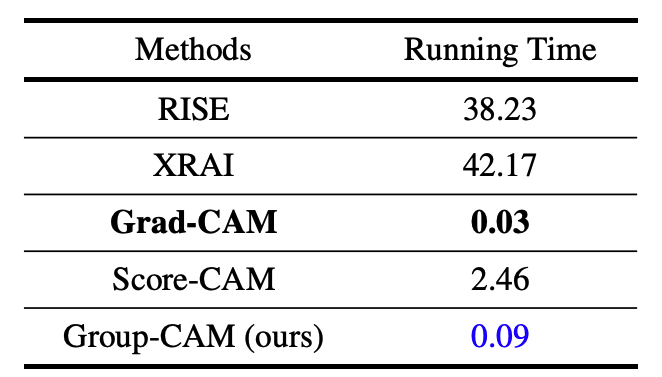
执行时间
下面是在NVIDIA 2080Ti GPU上的结果,显示Grad-CAM和Group-CAM的速度很快,运行时间不到0.1秒。
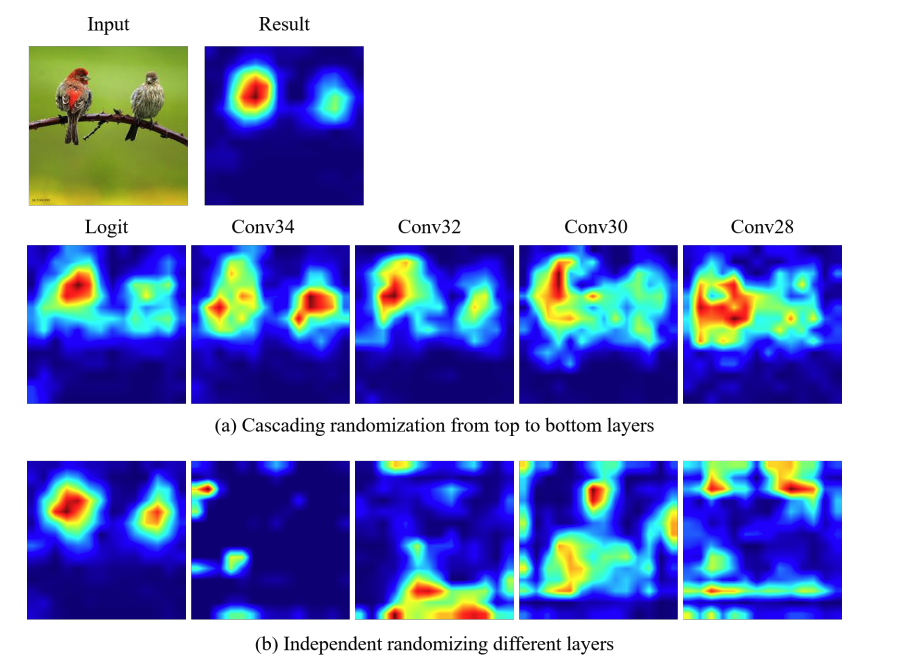
理智的检查
Sanity Check是谷歌大脑的团队提出的一种方法,用于评估XAI方法。如果参数完全不同,但输出却相似,那就不能很好地反映学习结果。
在本文中,我们通过比较从分类器初始化到目标层的热图所得到的结果,表明该方法是依赖于参数的。
数据增强
Group-CAM也可以应用于数据增强的方法。在论文中,我们报告说,在Il'上训练时,ResNet-50比ImageNet-1k的准确率高0.59%,Il'是一个通过消除wkc和误差反向传播以减少训练时间而产生的掩码,其中低于θ%的像素为0,其余为1。这项研究的结果如下
摘要
CNN大致可分为基于激活的模型和基于区域的模型,而Group-CAM是一个弥补了两者缺点的模型:它的优点是减少了使用Grad-CAM的噪音和推断单一决策基础的计算成本。看看这项研究将来如何应用于ViT原理的可视化,将是一件有趣的事情。



与本文相关的类别


