
YLFW,一个新的大规模数据集,旨在用于儿童保护的人脸识别技术。
三个要点
✔️ 新的数据集和基准旨在提高儿童人脸识别的准确性。
✔️ 新的数据集和基准评估了现有的人脸识别算法并揭示了其局限性。
✔️ 新的数据集和基准训练和评估了一种人脸识别算法并提高了其性能。
Young Labeled Faces in the Wild (YLFW): A Dataset for Children Faces Recognition
written by Iurii Medvedev, Farhad Shadmand, Nuno Gonçalves
(Submitted on 13 Jan 2023)
Subjects: Computer Vision and Pattern Recognition (cs.CV)
Comments: Published on arxiv.
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述。
随着过去十年深度学习的发展,人脸识别已经变得非常准确,并被广泛应用于刑事调查、移民控制和银行开户等各种场合。然而,许多挑战依然存在。例如双胞胎识别和年龄/性别/种族偏差。尤其重要的是儿童的面部识别。
迫切需要寻找和保护失踪或被绑架的儿童。例如,许多国家的年度报告中都报告了大量失踪儿童。2020年至2021年,英国警方记录了5万名失踪儿童。美国在2021年报告了约34万名失踪儿童。同年,加拿大政府报告了约28,000名失踪儿童。日本也不例外。根据国家警察厅的数据,每年约有1,000名儿童(9岁及9岁以下)被报告失踪,尽管这一数字低于其他国家。此外,日本还存在一些特殊情况:由于婚姻不和,在未经儿童同意的情况下将其带走是一个社会问题,儿童被带走后成为失踪人员的情况时有发生。在一些跨国婚姻中,孩子被带到国外后就再也找不到了。虽然没有准确的统计数字,但据信失踪儿童的数量相当大。
人脸识别技术对于寻找和保护此类失踪儿童至关重要。例如,在中国,一个家庭利用人脸识别技术找到了被拐卖的儿子,并与他团聚。警方通过将他童年时的照片与成年时的照片合并,并在数据库中进行识别,从而找到了他(被拐儿童32年后与父母团聚,面部识别技术提供帮助,CNN)。
此外,根据联合国儿童基金会的数据,2021年,129个国家约有440万名儿童遭受暴力侵害(其中230万名儿童有按性别分列的数据,其中53%为女性)。与2017年相比,这一数字增长了80%。一个更为紧迫的问题是儿童参与犯罪活动,他们不仅是受害者,也是犯罪者。例如,全世界都有证据表明儿童参与毒品和贩毒活动。面部识别技术在这方面也很重要。例如,布宜诺斯艾利斯市政府部署的面部识别系统就使用了登记在册儿童的身份数据。该系统利用面部识别技术监控城市并追踪特定个人。
因此,儿童人脸识别被认为是保护儿童人权的一项全球重要技术。然而,用于建立人脸识别模型的人脸数据集偏重于成人,而对于面孔稚嫩、面部随时间发生显著变化的儿童,人脸识别的准确率往往较低。尽管并不是完全没有数据集,但其中许多都是私人的,规模较小,而且还没有标准化的数据集。下表列出了迄今为止报告的儿童人脸数据集。
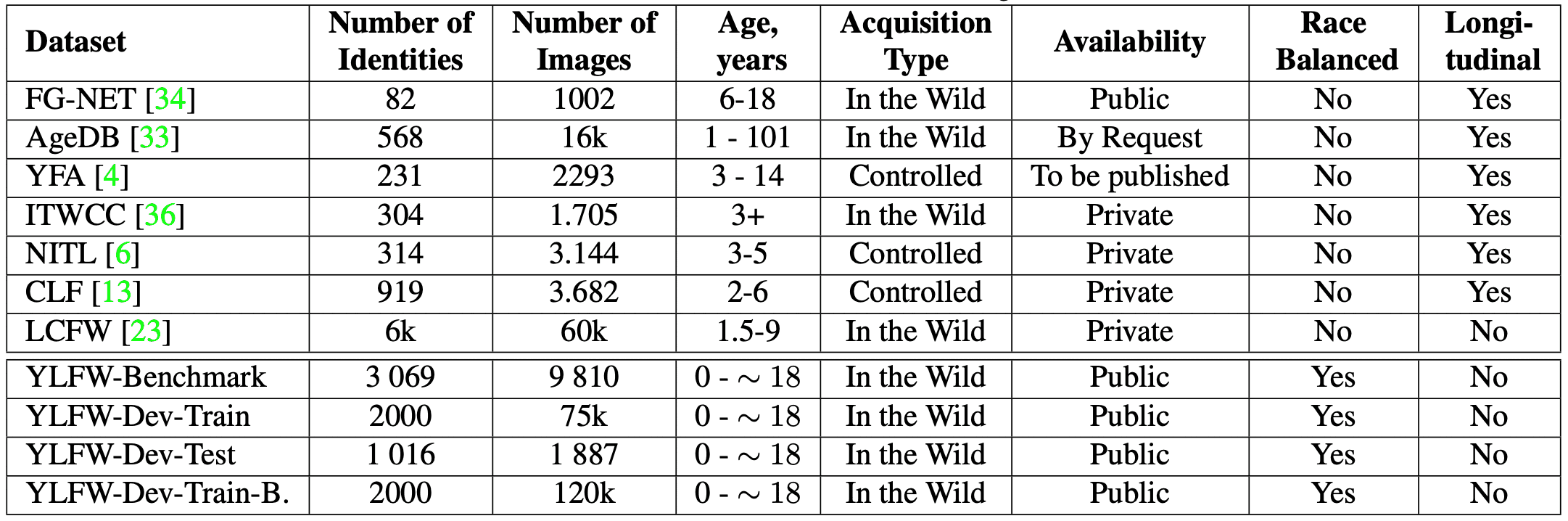
因此,本文提供了一个儿童人脸识别的参考数据集 "YLFW"。YLFW "是第一个用于儿童人脸识别的标准数据集,也是用于开发儿童人脸识别模型的最大数据集。该数据集的创建方式与其他著名的人脸数据集(如LFW、CALFW、CPLFW、XQLFW和AgeDB)类似。训练和测试数据集也用于调整儿童人脸图像的人脸识别模型。
YLFW数据集概览
YLFW包括两个数据集:"YLFW-Benchmark "和 "YLFW-Dev"。第一个 "YLFW-Benchmark "是用于评估儿童人脸识别算法性能的数据集,由大约10,000张图像和大约3,000个ID(单个人脸实体)组成。该数据集采用一种验证协议,将一张查询图像与一张图库图像进行比较。该协议提供约3,000对匹配图像(同一人的不同图像)和约3,000对非匹配图像(不同人的图像)。
下一部分是关于 "YLFW-Dev"。这是一个用于建立适合儿童人脸识别模型的数据集,分为 "YLFW-Dev-Train "和 "YLFW-Dev-Test "两组。数据集。另一方面,YLFW-Dev-Test是一个测试数据集,包含约1,900张图像和约1,000个ID;YLFW-Dev-Train和YLFW-Dev-Test各自设计为没有重叠的ID。这意味着训练数据集中使用的ID不包括在测试数据集中。当YLFW-Dev-Train作为训练数据集时,YLFW-Dev-Test也用于基准测试(性能评估)。
另一个数据集YLFW-Dev-Train-Balanced也可用于平衡数据集中的不同种族。该数据集是通过在原始YLFW-Dev-Train数据中随机添加少量种族的图像而创建的。通过水平翻转(将图像从左到右翻转)、调整亮度和对比度、旋转图像以及注入噪声等方法来添加图像。下表概述了所创建的数据集。
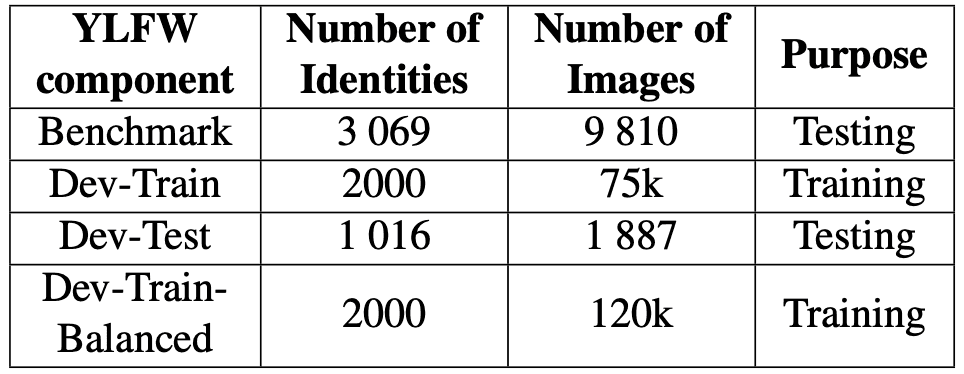
通过YLFW-Benchmark进行性能评估。
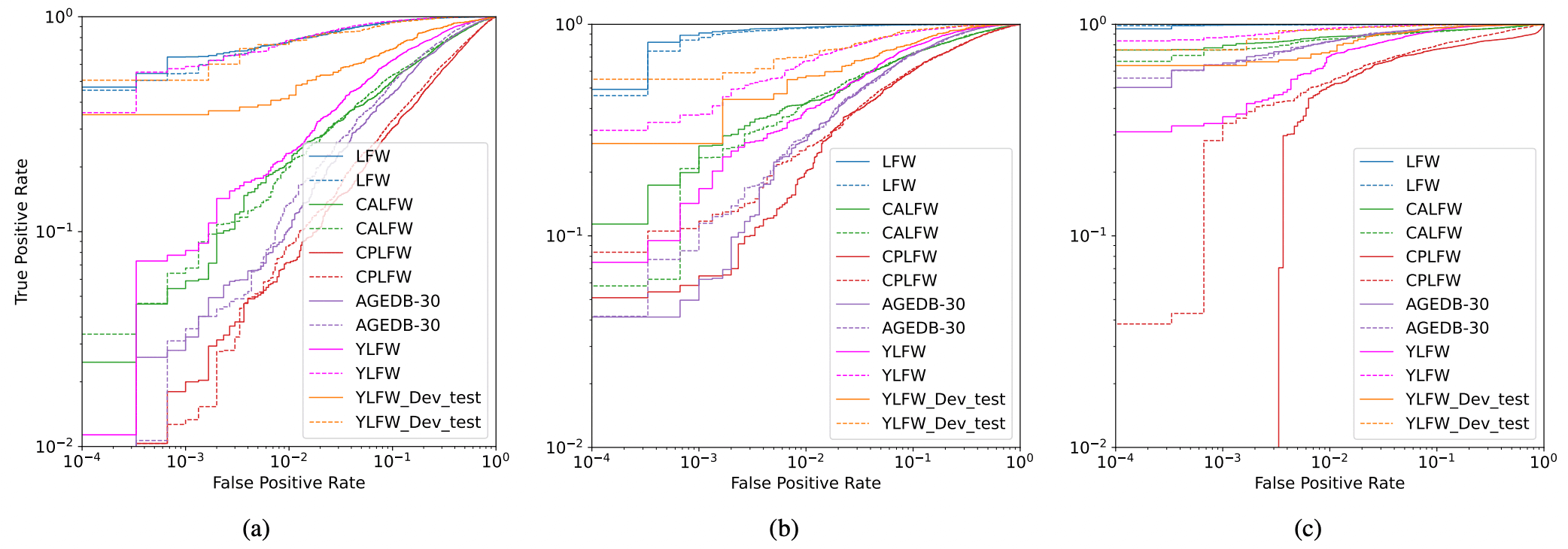
YLFW-Benchmark用于评估最先进(state-of-the-art,SOTA)的人脸识别模型在儿童人脸识别中的表现。这里使用的最先进(state-of-the-art,SOTA)人脸识别模型是在MS1MV2数据集上训练的ResNet-50人脸识别模型;我们尝试应用ArcFace、MagFace和AdaFace。结果如下图和下表所示。注意种族缩写如下:Afr. - 非洲人,As. - 亚洲人,Cau. - 高加索人,Ind. - 印度人。
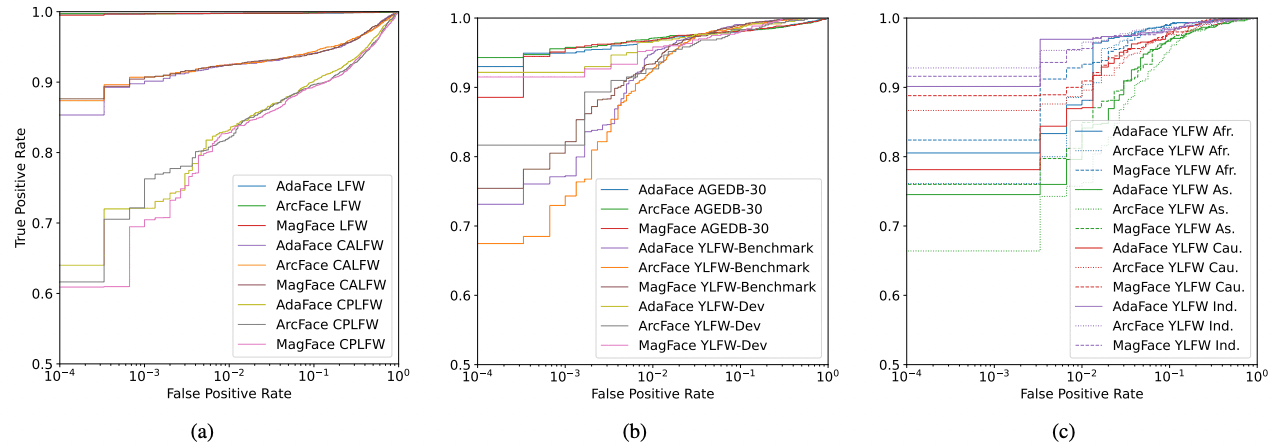
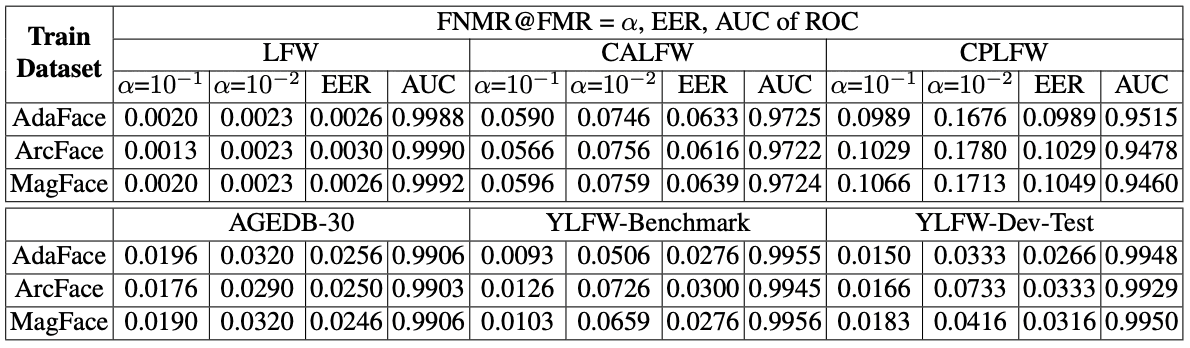
YLFW-Benchmark的结果表明,它是一个与CALFW和CPLFW难度相同的基准。YLFW-Dev-Test的结果也表明,当FMR较高时,即错误人脸识别概率较高时,其难度水平与YLFW-Benchmark相似,但当FMR较低时,该难度水平略低。
使用YLFW-Dev进行性能评估。
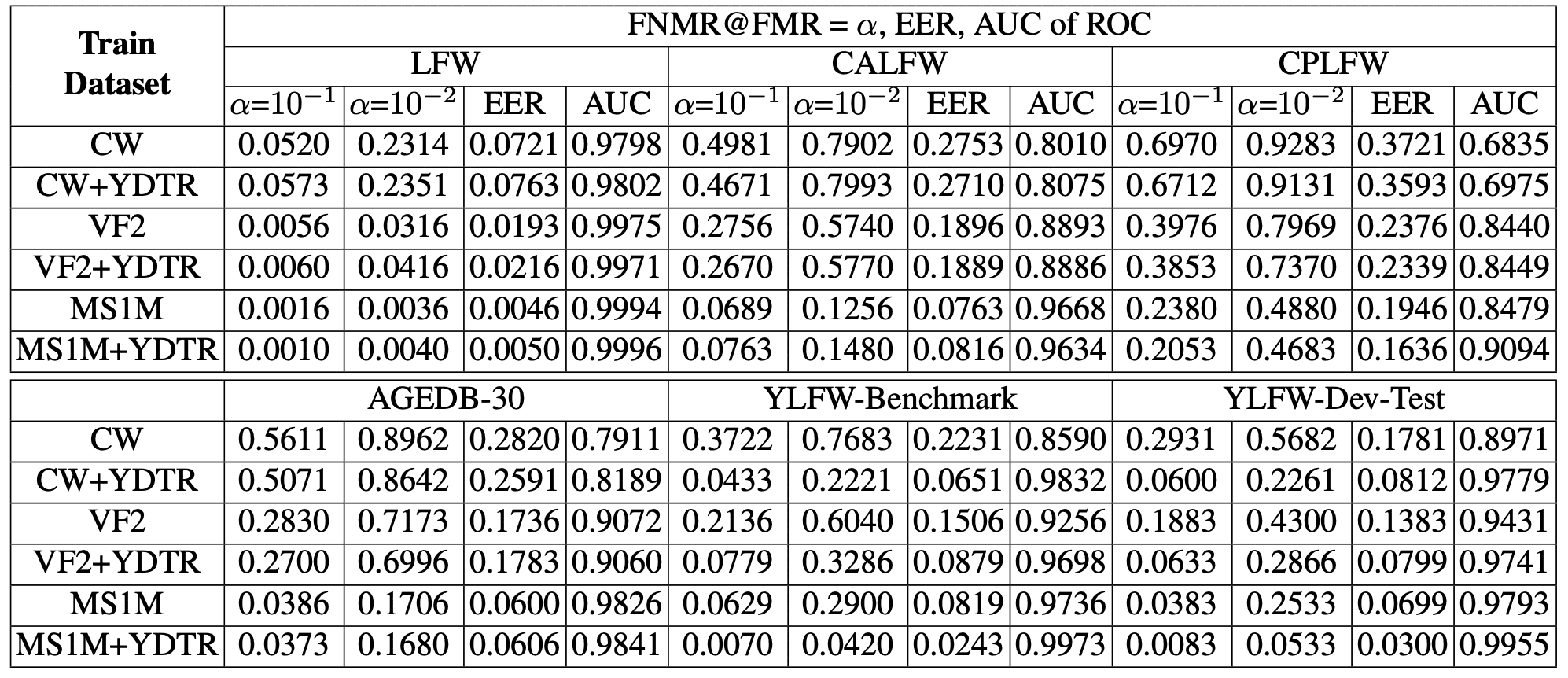
本节介绍使用YLFW-Dev进行的实验,该实验旨在通过提供训练和测试数据来支持儿童人脸识别模型的开发。 本实验还使用了ResNet-50,并使用ArcFace作为损失函数。下图和下表中的结果显示,使用YLFW-Dev-Train-Balanced数据作为训练数据明显提高了性能。请注意,下表使用了以下缩写:CW - CASIA-Webface,VF2 - VGGFace2,MS1M - MS1MV2,YDTR - YLFW-Dev-Train-Balanced。
摘要
本文提出了一个专门用于儿童人脸识别的新的人脸数据集YLFW。该数据集由两部分组成,YLFW-Benchmark和YLFW-Dev,每一部分都涉及青少年人脸识别研究的不同方面。该数据集是第一个专门用于儿童人脸识别的标准化基准,也是最大的数据集。此外,YLFW的实验表明,目前的人脸识别对儿童人脸的识别效果不够好。我们还表明,该数据集可用于提高青少年人脸识别的准确性。
据报道,在乌克兰战争中,许多父母和孩子失散。希望这项研究能够促进更多有关儿童保护的人脸识别研究,并希望人脸识别/身份验证能够帮助尽快解决涉及儿童的事件和犯罪。



与本文相关的类别






