
人脸检测模型中的人脸定位是否存在偏差?
三个要点
✔️ 验证人脸检测模型中定位精度的偏差
✔️ 创建一个具有10个属性标签的新数据集以验证多维偏差
✔️ 检查所有人脸检测模型中的性别、年龄和肤色的偏差
Are Face Detection Models Biased?
written by Surbhi Mittal, Kartik Thakral, Puspita Majumdar, Mayank Vatsa, Richa Singh
(Submitted on 7 Nov 2022)
Comments: Accepted in FG 2023
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述
机器学习被用于各种服务中,但机器学习模型中的偏见是一个主要问题。这是因为偏见使具有某些属性的人处于不利地位,导致不公平的结果。特别是,基于性别或种族的准确性差异会导致人脸识别、面部识别、面部属性预测和人脸检测中的 "歧视",这些都是处理女性生物特征信息的。事实上,在2020年,在发现公开使用的人脸识别系统因种族不同而存在准确性差异后,提供人脸相关技术的公司相继停止提供其系统。从那时起,关于人脸相关技术中的偏见的研究就开始活跃起来。
虽然对人脸识别和脸部识别的研究,已经成为越来越多的关注和实际应用的焦点,但对人脸检测的研究并不充分。然而,由于人脸检测技术在所有与人脸有关的技术管道中都有应用,可以认为了解人脸检测技术中的偏差将有助于揭示各种与人脸有关的技术中存在的偏差。
尽管一些关于人脸检测中的偏见的研究将偏见作为 "人脸 "和 "非人脸 "类之间的二元分类来研究,但人脸检测中最重要的方面--定位,还没有被研究。因此,本文从人脸区域定位的准确性方面调查了偏见,这一点到目前为止还没有得到验证。
为了从多个角度研究偏见,本文曝光了一个新的数据集,其中的属性数据是现有数据库中缺少的。除了人脸位置数据外,数据集F2LA还为每张脸贴上了10个属性数据。然后,这个数据集被用来研究现有人脸检测模型在性别、肤色和年龄方面的检测准确性偏差,以及除这些人口因素外可能影响偏差的混杂因素。
F2LA数据集。
一个名为 "带属性的公平脸部定位"(F2LA)的数据集已被创建。这个数据集包含1,774张人脸的1200张图像,每张图像都有位置和属性信息(10)。这些图片是在CC-BY许可下从互联网上收集的。下图显示了收集到的图像的一个样本。

这些工具是用来定位面和分配属性信息的,如下图所示。它已经由参与人脸相关技术研究的人进行了注释。该工具的使用如下图所示(a)确定脸部的位置,(b)分配属性信息。

要分配的属性信息在下表中的属性中显示。从上到下,性别、肤色、明显年龄、模糊、光照、面部方向、面部毛发、隐藏区域(Occlusion)、背景(Background)和图像的颜色属性(Colour Properties)被分配为属性信息。
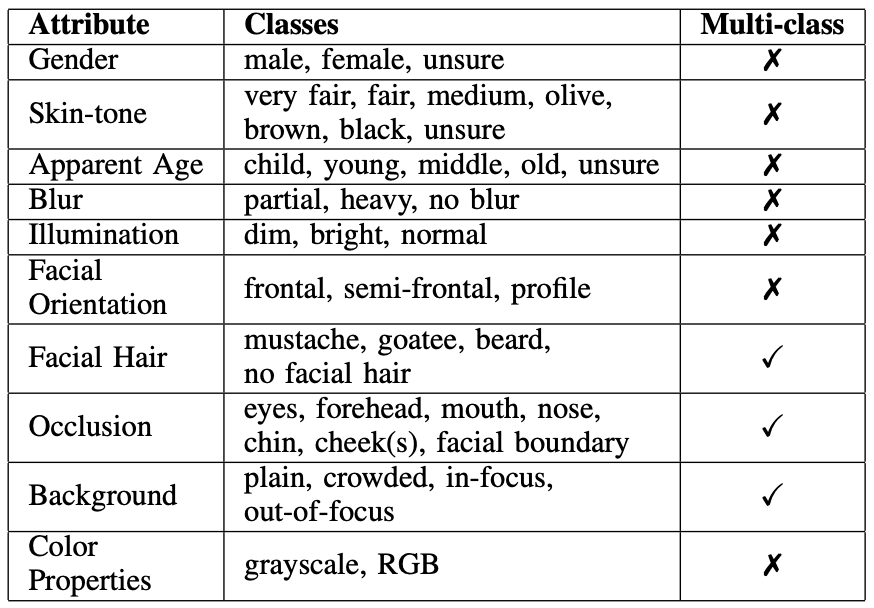
每个属性的信息类型也显示在表中的类别中。顺便说一下,菲茨帕特里克量表用于肤色(Skin-tone),不确定的主要用于灰度。请注意,Muti-Class表示一个特定的脸是否可以属于具有相同属性的多个Class。'✔'表示该面孔可以属于一个以上的类别。
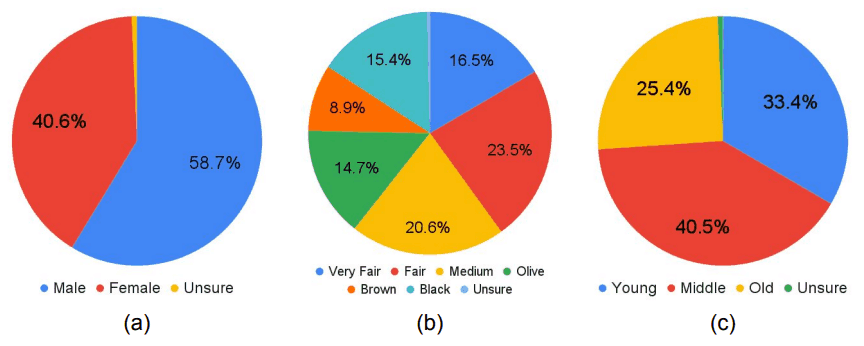
为了进行性能评估,包含1,774张脸的1,200张图像被分成包含1,486张脸的1,000张图像(训练数据)和包含288张脸的200张图像(测试数据)。测试数据已被调整为尽可能的平等,特别是在性别、肤色和表面年龄方面。这些属性在测试数据中的分布如下图所示。
实验
首先,评估了一个预先训练好的代表性人脸检测模型的性能。接下来,为了证实F2LA的人脸检测模型的性能改进,我们还对F2LA训练数据以及F2LA训练数据的一个子集进行了微调,调整了性别、肤色和年龄的平衡,评估了微调的结果。
MTCNN、BlazeFace、DSFD和RetinaFace被用作预训练的人脸检测模型;MTCNN、DSFD和RetinaFace使用由WIDER FACE 训练的模型作为预训练模型(pre-trained)和BlazeFace使用谷歌的MediaPipe提供的模型作为预训练的模型。
脸部的包围盒(Bounding Box)的IoU(Intersection over Union)被用来评估性能。换句话说,它使用人脸检测模型预测的人脸框与正确的人脸框之间的重合程度。完全重合的结果是IoU=1.0。在计算精确度时,为IoU设定了一个阈值。例如,如果阈值被设置为IoU=0.5,这意味着 "如果IoU=0.5或更多,则认为人脸被正确检测到"。然后,系统将评估在此阈值条件下检测到的人脸百分比。
下表显示了在F2LA测试数据上对预先训练的人脸检测模型(MTCNN、BlazeFace、DSFD和RetinaFace)进行性能评估的结果,其中t代表IoU阈值。当人脸周围框架的重叠度(IoU)为0.5或更高时被认为是成功的检测,当人脸周围框架的重叠度(IoU)为0.6或更高时被认为是成功的检测,准确度显示。
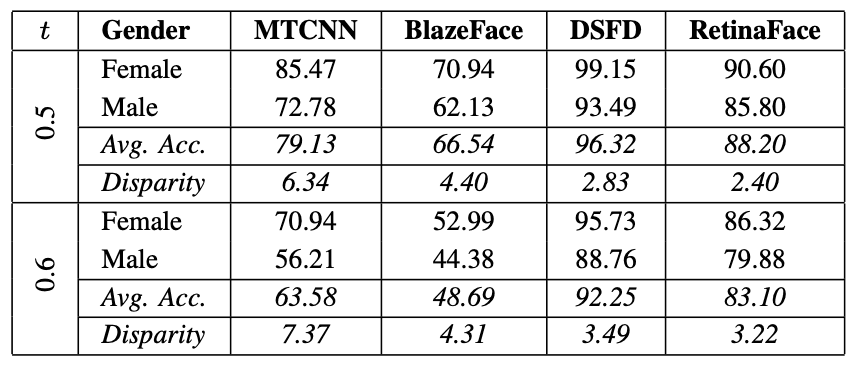
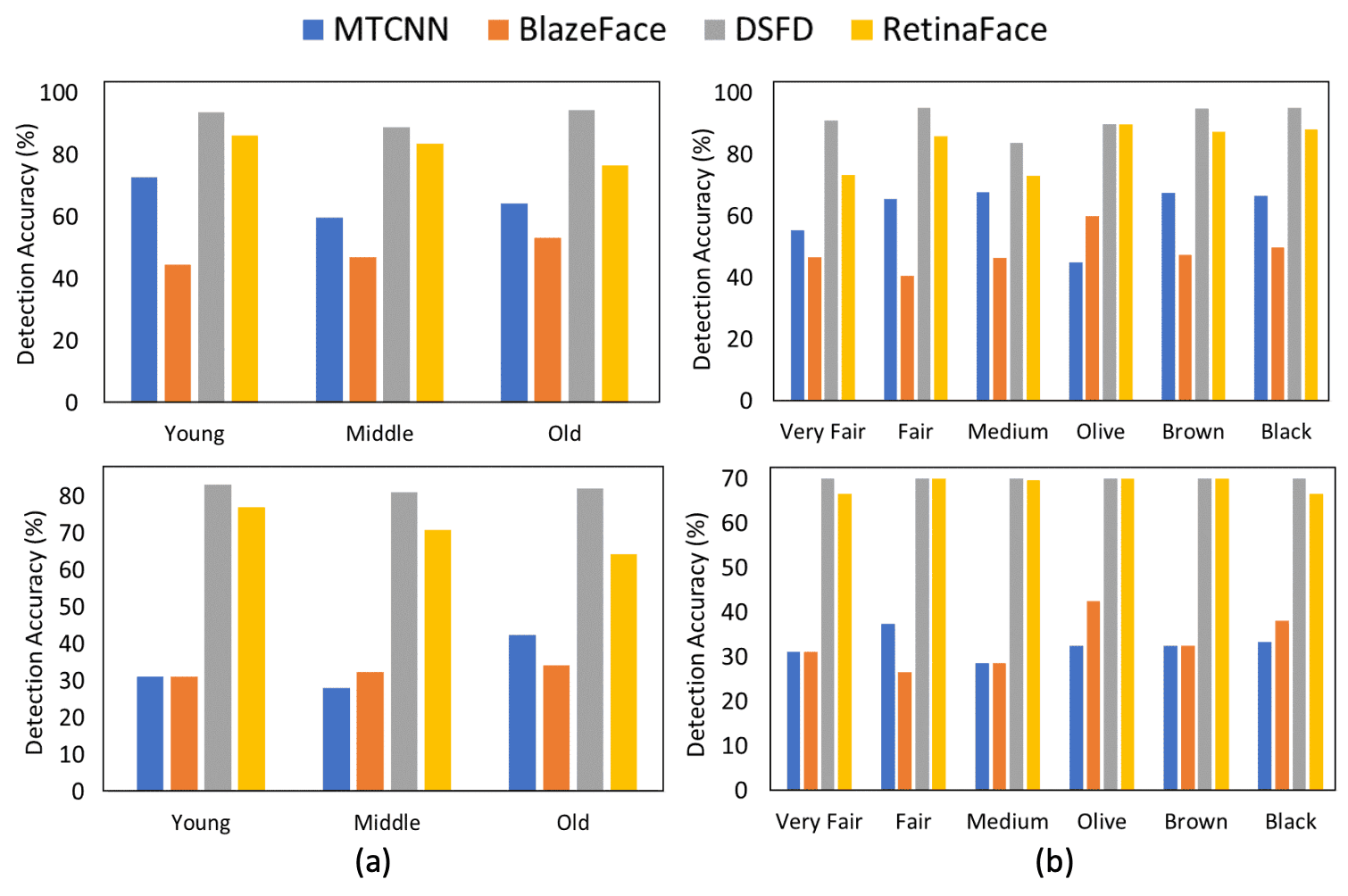
对于t=0.5和0.6,男性和女性的检测准确率都有明显差异,在t=0.5时,MTCNN和RetinaFace的差异率分别为6.34%和2.40%。在所有模型中,男性(Male)的检测准确率始终较低。年龄和肤色的结果也显示在下图中。上面一行代表t=0.6的情况,下面一行代表t=0.7的情况。同样,可以看出,每个班级的表现都 有差异 。
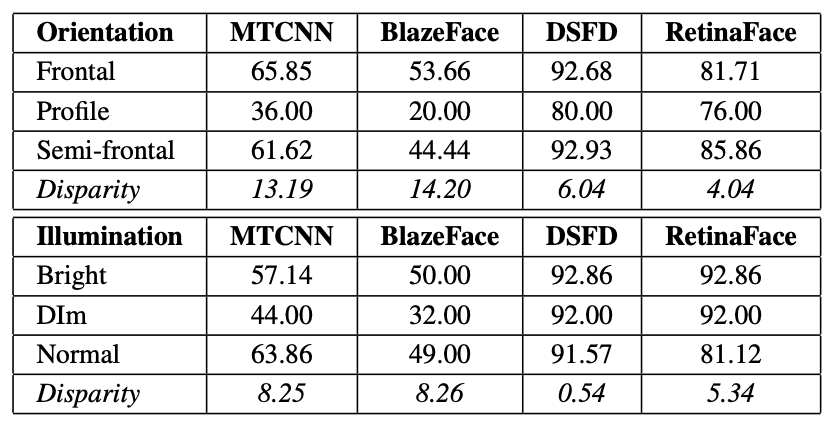
此外,下图显示了针对面部方向(Orientation)和照明条件(Illumination)的性能。可以看出,在高照度(Bright)下,正面脸(Frontal)的表现要好于在昏暗照度(Dim)下的侧面脸(Profile)。同样,我们可以看到,各班级的表现差异大致一致。
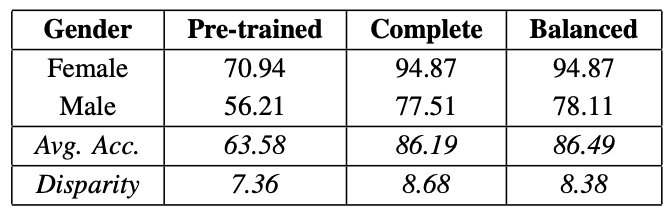
接下来,利用F2LA的训练数据,对每个训练过的模型进行了微调,下表对每个性别的检测精度进行了完整的检查。然后准备了F2LA训练数据的一个子集,对男性(Male)和女性(Female)模型的平衡进行了调整和微调,以产生平衡。
从表中可以看出,微调明显提高了性能。然而,不同性别(Gender)的表现差异仍然存在。这似乎是皮肤颜色和年龄的相同趋势。
可能影响偏见的因素。
关于影响人脸检测模型性能的因素,还发现了其他几种情况。下面的数字显示了用MTCNN、BlazeFace和RetinaFace 不能正确检测到人脸的样本图像。 (a) 由BlazeFace (b) 由MTCNN (c) 由RetinaFace。

可以看出,BlazeFace和MTCNN都不能很好地检测,尤其是在属于年长(老人)和男性(男子)的年龄组。还可以看出,它们对灰度图像的检测效果并不好。此外,BlazeFace似乎对小脸尺寸的人不太合适。另一方面,RetinaFace似乎在检测大尺寸人脸方面表现不佳。
此外,还讨论了用于预训练的WIDER FACE对模型性能偏差的影响。如上所述,MTCNN、DSFD和RetinaFace是用WIDER FACE进行预训练的,其中包括脸部方向(典型、非典型)、隐藏区域(无、部分、重)、光照(正常。极端)和模糊度(清晰、正常模糊、严重模糊),训练数据的分布如下图所示。(a)代表人脸的方向,(b)隐藏区域,(c)光照度和(d)模糊度。
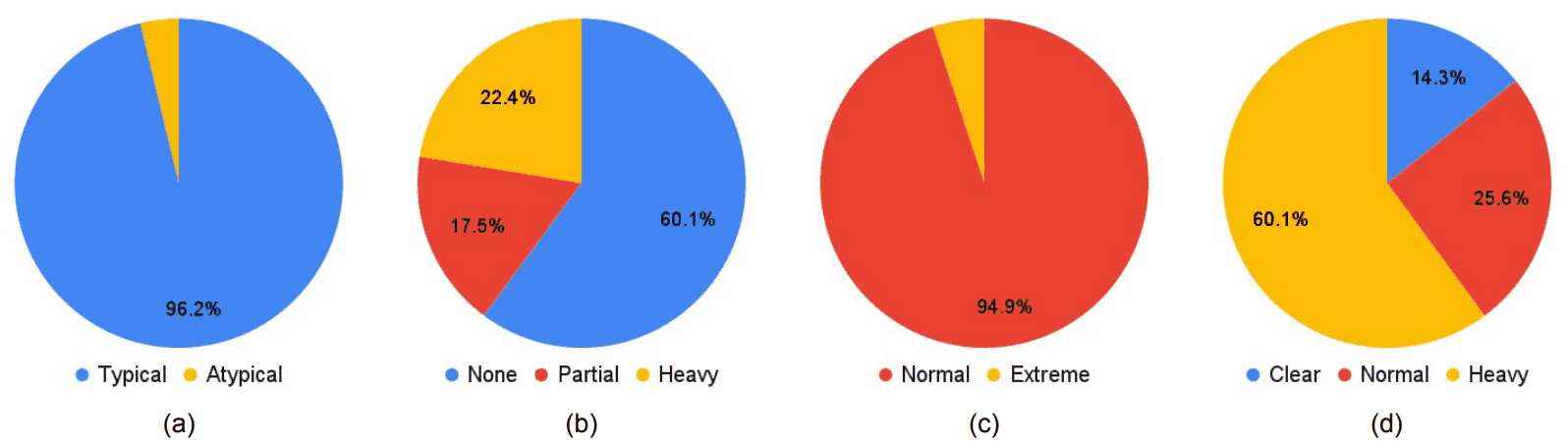
从饼状图中可以看出,WIDER FACE偏向于典型脸部方向和Noemal照明。而且,从之前的下表可以看出,对于F2LA测试数据的WIDER FACE中包含的属性(在下表中,正面和正常),其性能也相对较高。换句话说,正如预期的那样,我们可以认为训练数据中的偏差对性能有影响。
当目测由DSFD和RetinaFace检测到的人脸时,对两种性别来说,它们的检测似乎都没有问题。然而,在现实中,如下表所示,不同性别的人在表现上存在着明显的差异。
这部分是由于注释在脸部周围有一个较大的框架,而模型预测的框架较小,导致IoU较小。要检测的物体越小,这种影响就越大。在这种情况下,包含男性的图像包括大量的小脸,如下图所示。该研究指出,这可能也是造成两性之间表现差异的原因。下图(a)显示了正确的框架和(b)预测的框架。
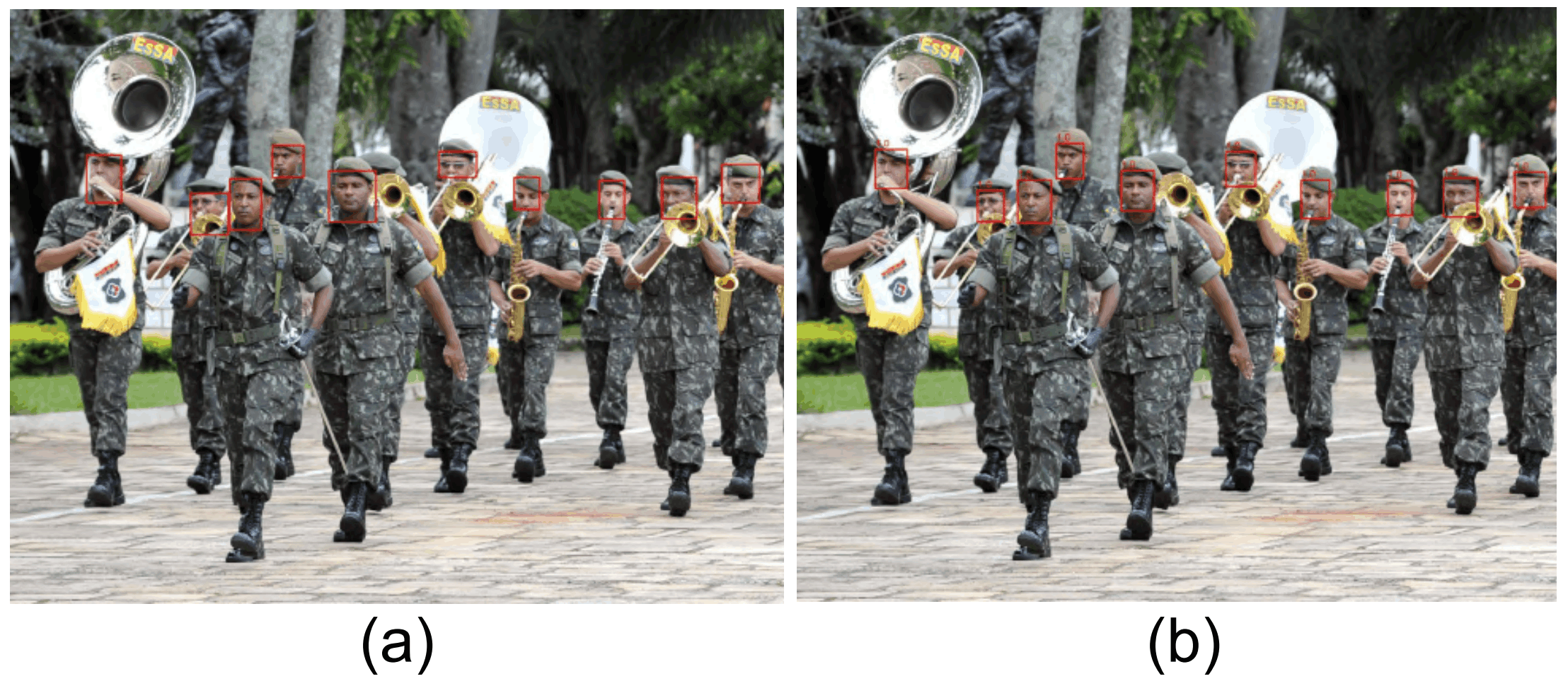
摘要
本文研究了在使用深度学习的人脸检测模型中是否以及何时存在偏见。
一般来说,使用深度学习的模型的偏见归因于人口统计学因素,如种族、性别和肤色,但也归因于非人口统计学因素(如脸部方向、脸部大小、照明、图像质量),因此对偏见的全面分析需要对现有数据集进行全面分析,缺乏将需要添加各种属性数据。
因此,在本文中,首次公布了一个新的数据集,称为 "带属性的公平脸部定位"(F2LA)。在这个数据集中,不仅给出了人脸的位置信息,而且还给出了每个人脸的10个不同的属性数据。这使得我们不仅可以检查人口统计学因素的偏差,还可以检查非人口统计学因素引起的混杂因素。
说实话,本文对偏差因素的分析还不够充分,但希望未来具有多样化属性数据的F2LA的发表能加速对人脸检测中的偏差的研究。



与本文相关的类别






