
无需共享原始数据,通过模型对比联合学习实现准确的图像分类!
三个要点
✔️ 在联盟学习中引入对比学习,实现高精度图像分类
✔️ 在对比学习中,引入了 SimCLR,利用数据增强
✔️ 除了图像之间的对比,还引入了模型之间的输出对比,以提高准确性。
Model-Contrastive Federated Learning
written by Qinbin Li, Bingsheng He, Dawn Song
(Submitted on 30 Mar 2021)
Comments: Accepted by CVPR 2021
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
协调学习概述
联合学习是一种机器学习方法,在数据集分布在多个客户端或设备上的情况下,为每个客户端或模型准备和训练一个机器学习模型,并共享每个模型的更新结果(权重差异)。这是一种开发模型的方法。
如何引入联合学习
在联合学习出现之前,如果数据分散,学习之前必须在中央服务器上汇总数据。
然而,传统方法要求每个介质将原始数据发送到中央服务器,这在处理包含个人或机密信息的数据时会造成信息泄漏的风险。此外,数据集中在一个地方的中央服务器容易受到攻击,这反过来又会造成安全漏洞。
此外,随着近年来人们隐私意识的增强,越来越多的公司和组织不愿意在数据聚合后使用传统的机器学习方法。在这种情况下,一种名为联合学习的方法被提出来。
联盟学习是一种无需共享分布式数据即可开发机器学习模型的方法,近年来备受关注。
联盟学习的类型(横向联盟学习和纵向联盟学习)
联盟学习可分为横向联盟学习和纵向联盟学习,其标准是几种媒体的数据有哪些共同点。
水平联盟学习是一种联盟学习方法,用于数据具有多个不同媒体共同特征的情况。例如,在不同医院病人的属性中,年龄和性别等基本要素被认为是所有医院共有的。因此,横向联盟学习可用于整合这些数据。
而垂直联合学习则是当来自多个不同媒体的数据有共同目标时使用的一种方法。例如,一个用户隶属于一家医院和一家金融机构,垂直联盟学习就是用来整合它们的数据。
由于本文介绍的是横向联合学习,因此本文将更详细地介绍横向联合学习。
联盟学习算法
如上所述,横向联合学习是一种用于整合分布在多个组织中的数据的模型,这些数据具有一组共同的特征。水平联盟学习的算法如下。
步骤 0:将中央服务器拥有的模型参数(该模型称为全局模型)固定为随机状态。
步骤 1:将中央服务器拥有的全局模型分发给参与联合学习的每个客户端。
步骤 2:每个客户端使用自己的本地数据,使用分布式模型进行训练。
步骤 3:每个客户端向中央服务器发送更新后的更新权重差。
步骤 4:中央服务器接收从每个客户端收集到的本地模型信息,并根据这些信息更新全局模型。
从步骤 1 到步骤 4 的一系列步骤被称为一轮,而在联盟学习中,要重复多轮才能逐步提高全局模型的准确性。
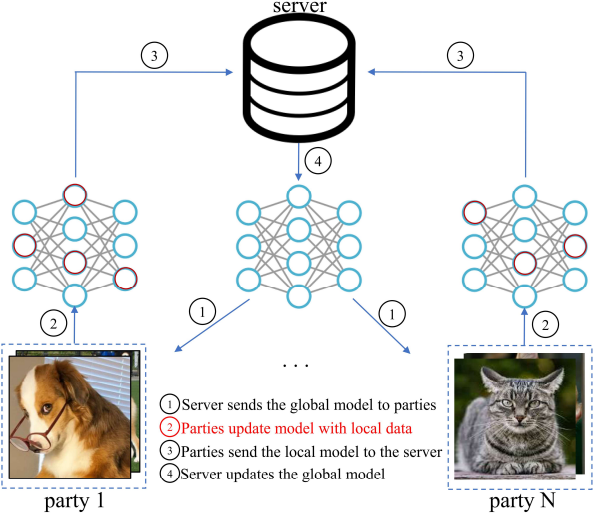
在首次提出联盟学习的论文中,全局模型的确定是为了最小化从每个客户端收集到的损失函数的加权平均值。然而,当客户所拥有的数据不平衡时,联盟学习的准确性就会下降,这对这一模型提出了挑战。
因此,现在有人提出了一些改进方法,例如根据数据集的性质在损失函数中加入一个修正项,而不是简单地对客户进行加权平均。(本文介绍的 MOON 就是这样一种改进方法)。
联盟学习在图像分类中的应用
联盟学习是一种用于表格数据分析和文本数据分类等领域的技术,目前正被应用于图像分类领域。
然而,与表格或文本数据相比,图像数据更加复杂多样,而且这些数据在客户端之间往往不平衡。因此,当联盟学习应用于图像分类时,全局模型和局部模型可能会出现分歧,从而导致准确率不高。
因此,为了解决这些问题,有一种技术可以引入对比学习,作为联想学习的预习。
对比学习概述
对比学习是一种无监督学习方法,它利用了最终分类结果相似的图像彼此相似这一事实。对比学习的损失函数是,属于同一类别的图像对之间的相似度较高,而属于不同类别的图像对之间的相似度较低。
在对比学习中,通常比较的是通过将图像投射到特征空间而获得的特征向量,而不是图像本身。这种特征向量是通过使用 CNN 编码器从客户图像中提取特征而获得的。
CNN是一种专门用于图像分类的神经网络模型,它通过引入卷积来提高学习参数的效率。其特点是:卷积层提取特征,汇集层压缩信息,并通过学习保持对平行移动的鲁棒性。著名的 CNN 模型包括AlexNet 和GoogleNet。
对比学习如何发挥作用
对比学习是主要的无监督学习方法之一,其中包括自监督学习。
无监督学习有多种方法,如基于生成任务的方法、基于判别回归任务的方法和基于比较任务的方法,但归类为判别和回归任务以及比较任务的方法有时被称为自监督学习方法。
正如 "自我监督 "这一名称所暗示的,这种方法可以从数据本身创建教师信号(标签)。这种方法可用于使用自动编码器生成图像,以及在自然语言处理中学习嵌入式单词表示法。
自监督学习具有预学习和微调相结合的结构,是一个有潜力应用于广泛任务的领域,同时提高了学习的普遍性。它有望应用于语音识别和自动驾驶等多个领域。
对比学习(SimCLR)机制的典型范例
在没有老师的情况下,如何学习图像之间的语义距离?在本文中,我们将利用对比度学习的典型范例SimCLR模型来解读对比度学习,以说明对比度学习的要点。
SimCLR是一种对比度学习模型,在这种模型中,从一幅特定图像中故意翻转或旋转的图像被准备好,从而使来自同一图像的图像之间的距离变小,而不同图像之间的距离变大。换句话说,通过学习,可以将原本是同一幅图像但经过翻转或旋转的图像识别为源自同一幅图像。从单组数据中生成多样化数据的过程称为数据增强。
对比学习中的预训练可以让机器学习模型考虑到数据的许多方面,从而提高模型的分类质量。SimCLR 模型因其简单和高性能而成为对比学习的主流模型,被广泛应用于自然语言处理和图像处理等领域。它被广泛应用于自然语言处理和图像处理等领域。
SimCLR 采用归一化温度交叉 Entoropy概念。其损失函数如下式所示。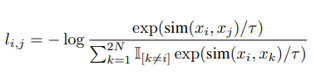
这里,sim 是余弦相似度的函数,即特征向量在方向上的相似程度。
分子表明,我们的学习效果越好,源自同一图像的特征向量的相似性就越大,损失函数就越小。分母计算的是特定单一图像 xk 与除 xk 以外所有图像的余弦相似度,它表明我们学习的越好,从不同图像中提取的特征向量的相似度就越小,损失函数就越小。
月球概述
模型对比联合学习(俗称 MOON)是 2021 年提出的一种模型,它成功地将这种方法的准确性向前推进了一步。
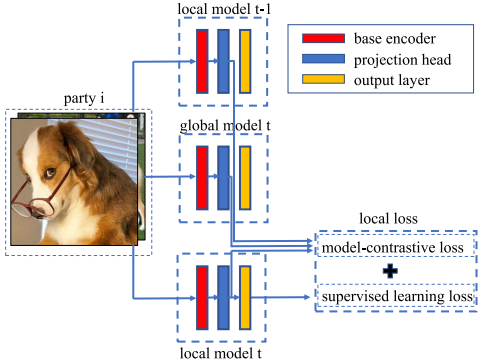
MOON 机制如图所示。三个不同的机器学习模型(从上到下依次为:客户端一轮前的模型、全局模型和当前的本地模型)通过客户端拥有的图像数据进行学习。对输出结果进行比较。
红色层是CNN 的编码器,执行特征提取。蓝色层是多层感知器层,专门用于表征学习,将特征向量转换为一定维度(本文中为 256 维)。黄色层表示分类结果的概率分布,作为最终输出。多层感知器层是一种完全由耦合层组成的神经网络模型,以其简单性和学习复杂模型的能力而著称。
MOON 损失函数的定义
如前所述,在用于图像分类的传统联盟学习中,图像分类是通过在客户端拥有的图像之间引入对比学习(即通过单一机器学习模型传递客户端内的图像并比较其输出)来实现的。相比之下,MOON 方法采用不同的方法得出损失函数,并将其添加到传统的损失函数中。
具体的损失函数如下
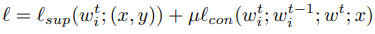
μ 是预先指定的超参数。基于单一模型的对比度训练所产生的损失函数会被添加到基于单一图像的对比度训练所产生的损失函数中。
等式的后半部分显示,对于给定的某幅图像,通过客户端模型获得的输出结果与该客户端一轮之前的模型输出结果进行对比,以进行学习。
由于这可能是模型中最重要的部分,我们将通过概念对比图来重申这一点。
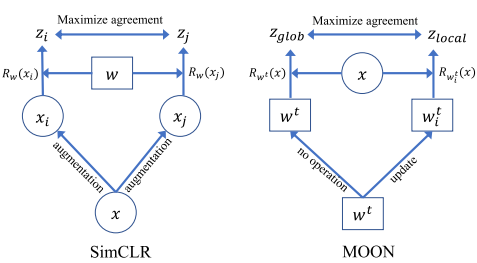
左图显示的是 SimCLR 方法,来自一个客户端的图像通过一个机器学习模型来得出图像的相似度。右图显示的是 MOON 方法,该方法将一张图像通过多个不同的机器学习模型运行,并比较它们的输出结果。从图中可以看出,虽然构成相似,但我们比较的是不同的概念。
如何确定 MOON 模型
联盟学习中的全局模型是将每个客户的平均损失函数加权值与所有客户的平均损失函数加权值相加,并学习如何使损失函数最小化。每个客户的平均损失函数是该客户所有图像对损失函数的平均值。
如何确定 MOON 算法

MOON 的模型更新算法如图所示。其中,T 是通信总数,N 是客户总数,E 是局部历元数,η 是联盟学习中的学习率,τ 是预先指定的超参数。
实验结果
为了证实 MOON 在图像分类方面的准确性,我们将图像分类的准确性与 Fed Average、Fed Prox 和其他联盟学习方法等现有方法进行了比较。我们使用了三个图像数据集:CIFAR-10、CIFAR-100 和 Tiny-ImageNet。这三个数据集都是计算机视觉领域的基准自然图像数据集。
Res-Net50 被用作图像分类的基础。Res-Net 是一种专门用于图像分类的机器学习模型。该模型引入了一种称为 "跳过连接"(skip connections)的机制,通过一种称为 "跳过连接"(skip connections)的过程,即跳过各层,解决了 "梯度损失"(de-gradation)问题,即随着层数加深,准确率下降,难以优化函数。这一概念已被引入各种深度学习模型中。
假设局部历时(虚拟客户机数量)为 10,实验次数为 3,得出的平均值和标准偏差结果如下。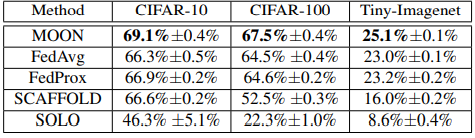
实验表明,在这两个图像数据集上,MOON 的图像分类准确率均高于现有方法。
总结和未来展望
联盟学习是一种在数据分布的情况下,既能以低成本进行机器学习,又能保护隐私的方法,引入这种方法不仅能保护隐私,还能降低更新模型时向中央服务器发送数据的通信成本。这种方法的引入不仅有望保护隐私,还能降低更新模型时向中央服务器发送数据的通信成本。
还考虑了实时更新模型的能力,以便灵活学习。
本文提出了一种专门用于图像分类的联盟学习模型--MOON,结果表明,该模型的准确性明显优于现有的联盟学习模型。
MOON 预计将应用于各种计算机视觉应用,如医学图像分类和物体检测。此外,MOON 并不局限于将图像作为输入数据,这表明该方法可应用于视觉图像以外的各种领域。不仅是 MOON,利用自监督学习的方法也有望在未来发挥重要作用,我们将密切关注未来的研究。



与本文相关的类别




