二维GAN对三维形状了解吗?
3个要点
✔️ 证明GANs隐性学习3D信息。
✔️ 提出了一种无监督的方法,从2D图像上训练的GANs中恢复3D形状。
✔️ 与现有的3D形状恢复和人脸图像旋转方法相比,表现出优越的性能。
Do 2D GANs Know 3D Shape? Unsupervised 3D shape reconstruction from 2D Image GANs
written by Xingang Pan, Bo Dai, Ziwei Liu, Chen Change Loy, Ping Luo
(Submitted on 2 Nov 2020 (v1), last revised 21 Feb 2021 (this version, v2))
Comments: Accepted to ICLR2021 oral.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
dataset:

首先
生成式对抗网络(GAN)在图像生成和其他应用中表现出了非常好的性能,并成功地生成了各种各样的数据。在本文介绍的论文中,我们展示了用2D图像训练的GANs也可以隐性地捕捉3D信息。
换句话说,我们已经证明了从对二维图像进行训练的GAN中恢复二维图像的三维形状是可能的。画面如下图所示。

所提出的框架能够从二维图像中恢复(无监督)三维形状,还能进行改变视角(旋转)和改变证明等高级操作。下面就让我们一起来看看吧。
技巧
所提出的方法的整体图示如下 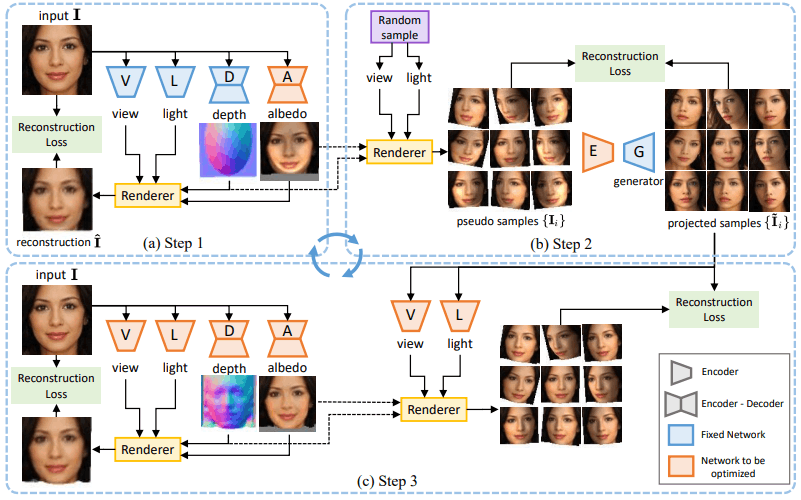
这种方法沿用了以往的研究。
在这种情况下,我们将图像$I \in R^{3×H×W}$作为输入,并使用函数预测由深度图$d \in R^{H×W}$(深度信息)、反射率(反射率)图像$I \in R^{3×H×W}$、视点$v \in R^6$和光照方向$l \in S^2$组成的四条信息。是用。从图中左上角(a)可以看出,这是用分别对应四种信息的子网络($D,A,V,L$)来预测的。
这四条信息被训练成通过渲染过程来恢复原始输入,包括两个步骤,即Lighting$\Lambda$和Reprojection$\Pi$。
照明$/Lambda$可以说是根据图像的三维信息(深度、反射率和光照方向)来构造三维外观的图像,重投影$/Pi$可以说是将三维的外观投射到二维的图像上。 通过这些还原图像并获得$/hat{I}$的过程可以用下面的公式来概括。
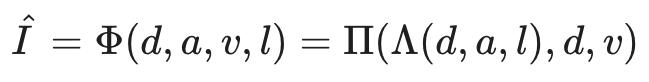
本设计沿用了前面提到的前人研究,但前人研究采用物体形状对称作为假设,而我们的方法则避免了这一假设,通过以下程序使用GAN更好地捕捉物体的不对称性。
第1步(图a):使用弱电形状。
许多物体,包括人脸和汽车,都被认为具有微凸的形状。
然后,我们初始化深度图$d$,对应图像$I$,以椭圆的形式,如图(a)中的深度。我们利用现有的场景分析模型对椭圆进行定位,使其与图像中的物体大致匹配。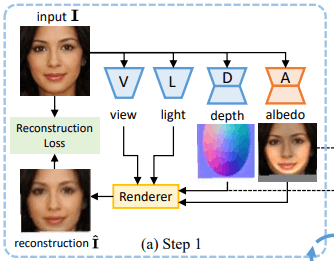
此外,我们初始化视点为$v_0=0$,光照方向为来自正面,并根据重建损失训练反射率网络$A$。
第二步:取样并投射到GAN图像上的manifold上
将视点$v$和光照方向$l$随机采样并渲染,得到伪样本${I_i\}$。
如下图所示,这些伪样本有不自然的扭曲和阴影,但它们也有关于人脸的旋转(对应视角的变化)和光线的变化(对应光线方向的变化)的信息。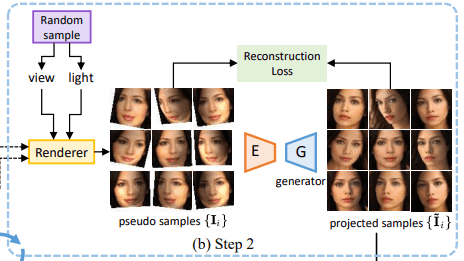
现在,我们通过GAN的生成器重建这些伪样本。具体来说,我们训练编码器$E$来预测每个样本的中间潜伏向量$w_i$(我们不训练GAN的生成器)。在这种情况下,优化目标由下式给出
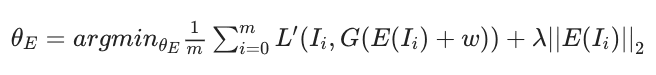
其中,$m$是样本数,$\theta_E$是编码器$E$的参数,$\lambda$是正则化因子,$L^{\prime}$是图像距离的度量(所提出的方法中的L1距离)。
$lambda||E(I_i)||_2$是一个正则化项,它可以防止潜伏偏移量变大(远在中间潜伏向量分布之外)(本文也采用了强正则化方法)。
我们使用的是GAN的发电机,但如前所述,我们不训练发电机。因此,即使输入图像中存在非自然的扭曲或阴影(这些扭曲或阴影在普通的二维图像中并不存在,通常也不会包含在 GAN 的输出中),这些扭曲或阴影也不会出现在生成器生成的结果中(以及普通 GAN 的输出中)。
因此,在适当保留伪样图像的视点、光线变化等信息的前提下,通过修正正常二维图像中不包含的非自然变形和阴影,就可以生成自然图像。
第三步:学习3D形状
在步骤2中得到的生成结果(投影样本$tilde{I}_i$)可以说是成功改变了原图像$I$的视角和光照方向。
在步骤3中,我们利用这些信息来学习3D形状。具体来说,如下图所示,视点和照明网络$V,L$预测每个样本$tilde{v}_i,/tilde{l}_i$的视点和照明方向$tilde{I}$。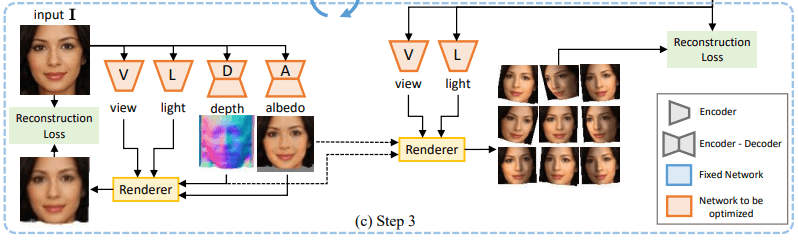
深度和反照率网络$D,A$以原始图像$I$为输入,输出深度和反照率图像$\tilde{d},\tilde{a}$。根据这些预测进行渲染,并进行训练,这样就可以重建每个样本图像。在这里,四个网络是由以下重建目标联合训练的。
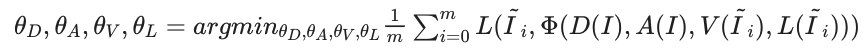 在这种情况下,不仅步骤2中生成的投影样本$tilde{I}_i$,而且还同时使用原始图像$I$作为样本之一。
在这种情况下,不仅步骤2中生成的投影样本$tilde{I}_i$,而且还同时使用原始图像$I$作为样本之一。
此外,我们在步骤2中对每个样本的视点和光照方向$v_i,l_i$进行随机采样,但在步骤3的训练过程中并没有使用到这一点(因为当GAN生成器生成时,视点和光照方向可能会发生变化)。 通过这1-3步的迭代,我们适当地学习了3D信息(在我们的实验中迭代了四次)。 
在迄今为止的讨论中,我们假设原始图像$I$是一个单一的图像,但这可以扩展到多个图像。
实验
在实验中,我们对所提出的三维形状恢复方法进行了评估,然后将其应用于三维图像操作,如视点改变。
实验设置
数据集
使用的数据集如下
GAN模型
所提出的方法内使用的GAN是StyleGAN2,它已经在前面提到的数据集上进行了预训练。
无监督的三维形状重建
定性评价
所提出的方法和前人在Unsup3d中的研究的定性结果如下图所示。

从图中可以看出,人脸、猫咪、汽车、建筑等3D造型都可以高质量的还原。Unsup3d方法也显示出一些良好的效果,但它往往表现不佳,特别是对于汽车和建筑物等不对称的对象。
量化评估
对于定量评估,我们使用BFM数据集。在这里,沿用以前的研究,我们使用SIDE(标尺不变深度误差)和MAD(平均角度偏差)作为评价指标。结果如下: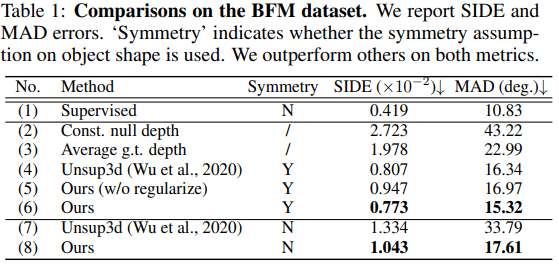
对称性表示有(Y)或无(N)对称性假设的情况。总的来说,结果优于前面的研究(Unsup3d)(表中的(6)、(8))。另外,不进行潜伏偏移正则化的情况如(5)所示,这说明所提出的方法中的正则化是有效的。
此外,所提出的方法使用椭圆来初始化形状(深度图),但用不同的设置初始化时的比较结果如下所示。

不去细说,我们可以看到形状初始化设置对性能的影响很小。然而,在平面几何体(Flat)的情况下,性能明显差了很多,所以有必要对3D几何体进行初始化,至少能够捕捉到视点和光线方向的变化。
关于三维图像处理
物体的旋转和重新点亮
训练完成后,所提出的方法可以通过改变视点$v$和光照方向$l$进行三维图像处理,并进行渲染(或通过编码器$E$和GAN Generator$G$)。
在下图中,我们展示了物体旋转并重新发光时的结果。 
Rotation(Relighting)-3D显示的是渲染的情况(从恢复的3D形状和反射率图像),Relighting(Relighting)-GAN显示的是通过编码器-GAN生成图像的结果。渲染结果忠实地反映了物体的结构,GAN生成的图像非常自然、逼真,说明两者都在有效地工作。
面部旋转以保持身份
我们将提出的方法与可以使用GAN进行人脸旋转的无监督方法(HoloGAN、GANSpace和SeFa)进行比较。
具体来说,对于每种方法,将100张随机的人脸图像从-20度旋转到20度,并获取20张样本图像。 当使用一般的人脸身份检测模型ArcFace时,我们评估人脸身份在旋转过程中的变化。如果人脸图像旋转得当,人脸身份不会发生明显变化。结果如下:
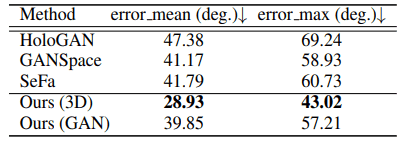
如表所示,我们可以看到,与现有方法相比,损失非常小,人脸身份得到了有效的保留。此外,下面是一个实际生成的例子。
在现有的方法中,由于旋转,人脸会发生很大的变化(例如,GANSpace右边的性别变化),而提出的方法(Ours)可以识别同一个人。
今后的问题
虽然提出的方法效果很好,但也有一些情况下不能准确恢复三维形状,如下图所示。
这可以归因于所提出的方法的形状初始化是一个简单的凸形。此外,由于所提出的方法的三维形状是以深度图为参数的,所以不能对物体后面的形状进行建模。这可能会通过更好的参数化来解决,比如处理深度图以外的某种形式的3D网格,未来有望得到发展。
摘要
在本文介绍的论文中,我们提出了一种创新的方法,用于从对2D图像进行训练的GAN中进行无监督的3D形状恢复。这不仅为3D形状恢复任务提供了一种有效的方法,而且表明GANs也能隐性地学习3D信息。GANs在图像生成方面已经非常成功,但现在其潜力更加明显。



与本文相关的类别






