用GAN从有限的数据中生成高精度的图像
三个要点
✔️提出了一种新的增强方法,称为自适应伪增强(APA),用于在有限的数据下学习GANs。
✔️理论上证明,APA收敛于最优解
✔️对于多个数据集,使用APA的模型表现优于传统的SOTA模型。
Deceive D: Adaptive Pseudo Augmentation for GAN Training with Limited Data
written by Liming Jiang, Bo Dai, Wayne Wu, Chen Change Loy
(Submitted on 12 Nov 2021)
Comments: NeurIPS 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
GANs的SOTA模型,如StyleGAN2,可以产生非常准确的图像,但它们需要大量的训练数据。然而,由于数据的稀缺性和隐私问题,并不总是能够获得足够的训练数据。一般来说,当GAN的训练数据稀少时,Discriminator会过度拟合,真假图像的输出分布会相差甚远。因此,反馈给生成器的信息变成了无意义的信息,而生成的图像的准确性也会恶化。在本文中,我们提出使用在本文中,我们开发了一种新的增强方法,称为自适应伪增强(APA),它可以根据过拟合的程度,自适应地欺骗判别器将生成的图像视为真实图像。APA通过自适应地欺骗鉴别器,使其相信由生成器生成的图像是真实的图像,从而降低了准确性。因此,判别器不太可能被过度拟合,生成的图像的准确性可以得到提高。
APA
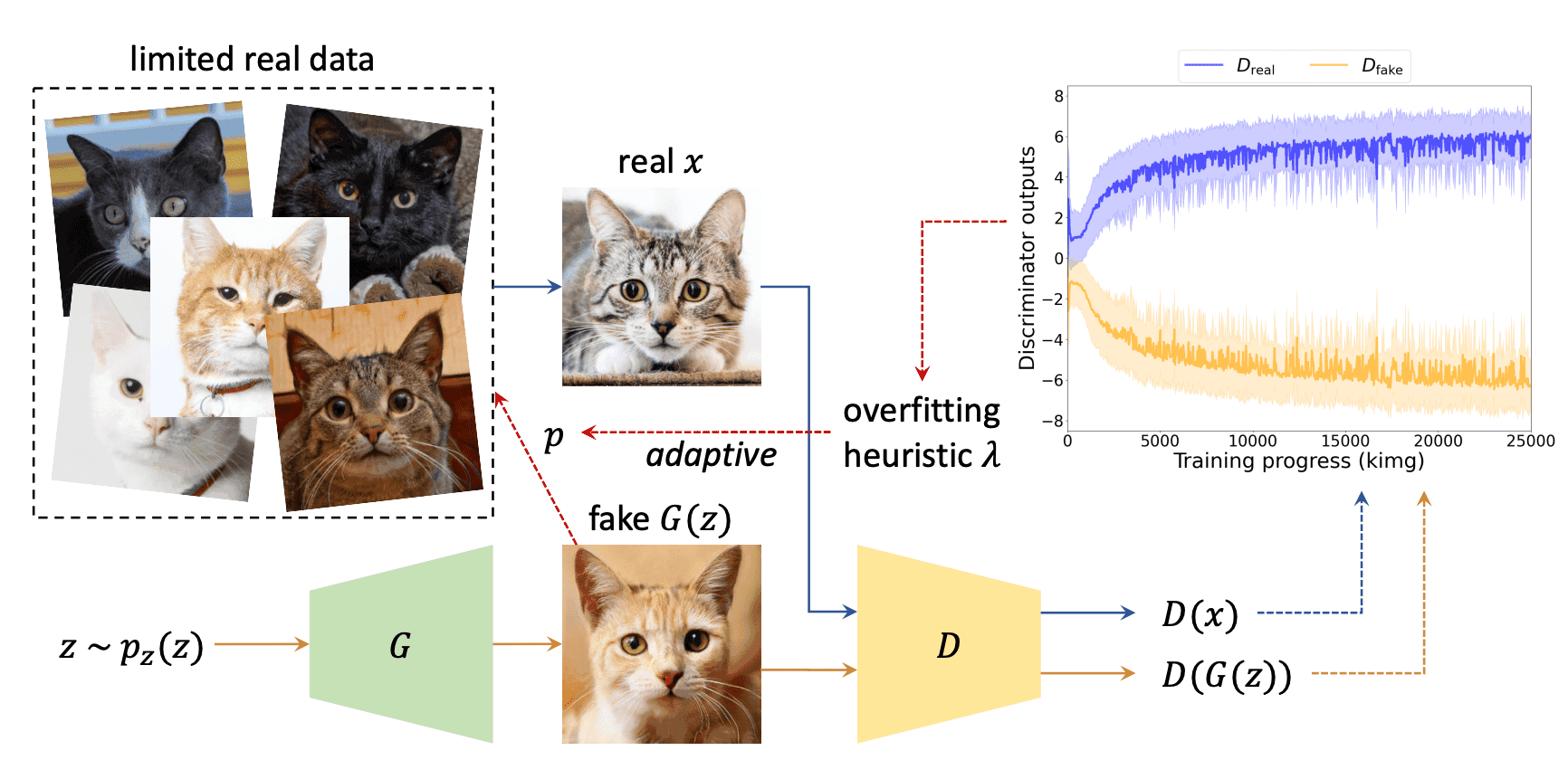
如上图所示,我们将生成器生成的图像视为伪真图像,并愚弄鉴别器。由于把假图像当作真图像的效果不好,我们使用了一个伪增强,它以一定的概率$p在[0,1]$运行,以1-p$的概率不做任何事情。这里$p$根据判别器的过拟合程度而变化,并使用参数$lambda$进行调整,定义为
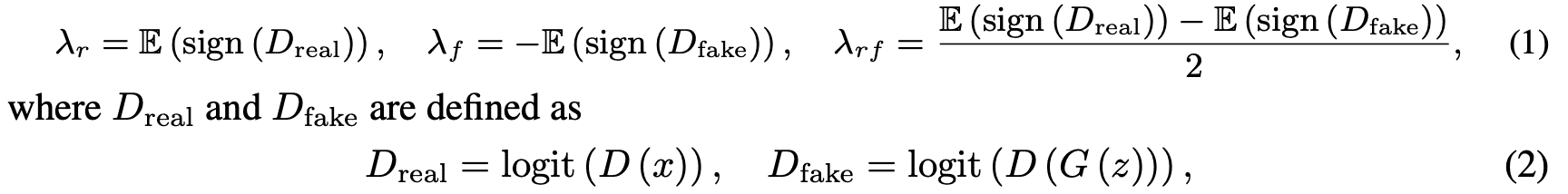
其中$D,G$是判别器和发生器,$x$是真实图像,$z$是噪声参数,logit是对数函数。$lambda_r$代表鉴别器对真实图像预测的阳性对数的百分比,$lambda_f$代表对错误图像的百分比。此外,$lambda_{rf}$代表真假图像的对数之间的一半距离。对于所有的$lambda$,$lambda=0$代表完全没有过拟合,$lambda=1$代表完全过拟合。在本文中,我们特别使用$lambda_r$作为参数。具体来说,它初始化为$p=0$,对于一个阈值$t$(主要使用的值是0.6),如果$lambda$高于(低于)$t$,$p$会增加(减少)一个步骤。每4次迭代重复一次,以便根据过拟合的程度进行适应性的伪增强。
理论上的考虑
让$alpha$是$p$的期望值,则满足$0\leq\alpha<p_{rm max}<1$,生成器和鉴别器的价值函数$V(G,D)$如下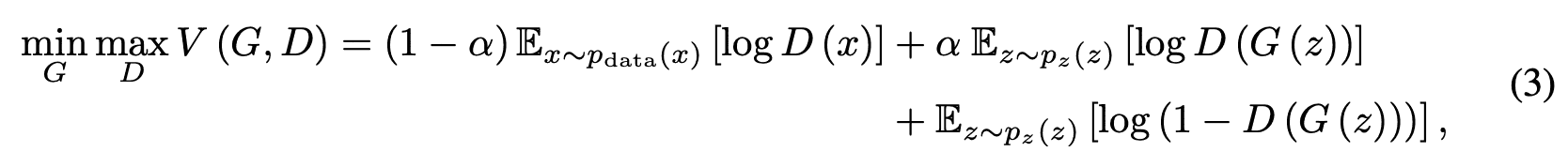
那么以下命题成立。
命题1
当$G$固定时,$D$的最优解是
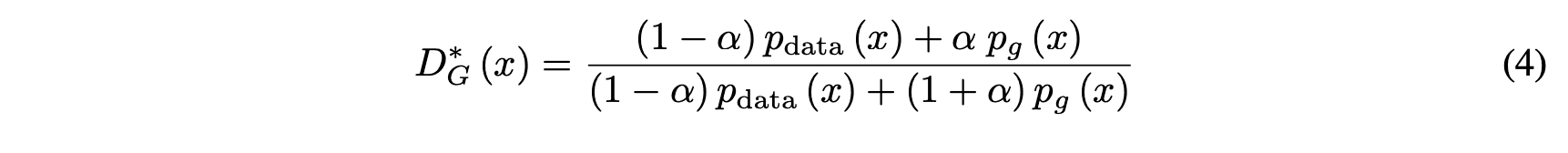
其中$p_{data}(x), p_g(x)$是真实和虚假数据所遵循的概率分布
证明
对于任何$G$,$D$,因为目标是最大化$V(G,D)$。
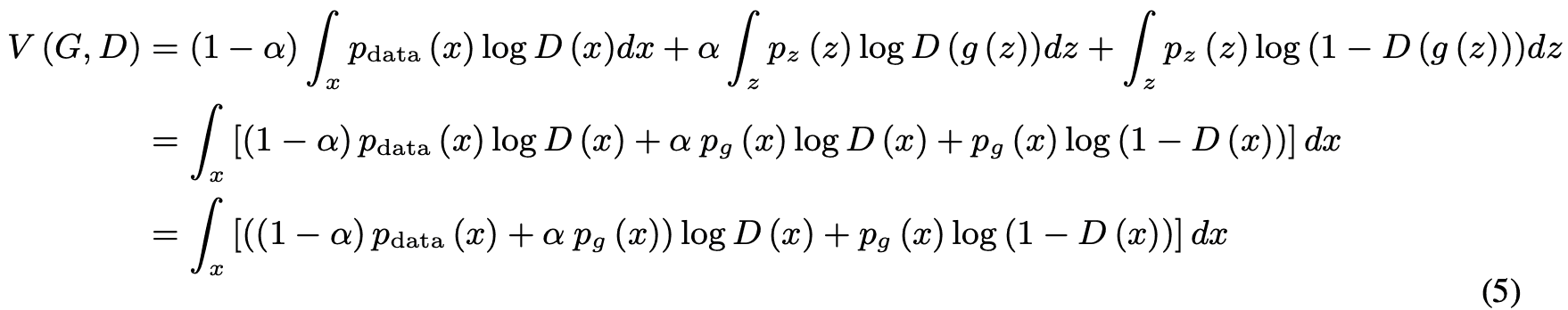
这里,对于除$m=n=0$以外的任何实数$(m,n)$,当$y=frac{m}{m+n}$时,$f(y)=m/log(y)+nlog(1-y)$是最大的。另外,由于$D$是在$p_{data}$或$supp$(table)中定义的,所以命题1得到满足。(证明完毕)
顺便说一下,当$D$采取最优解时,$G$的目标是最小化$V(G,D)$,但$D$的目标是使输入$x$的预测$Y$的条件概率$P(Y=y|x)/(其中/y=0/{/rm or}/1)$的对数可能性最大化,所以评价函数可以写成评价函数可写为
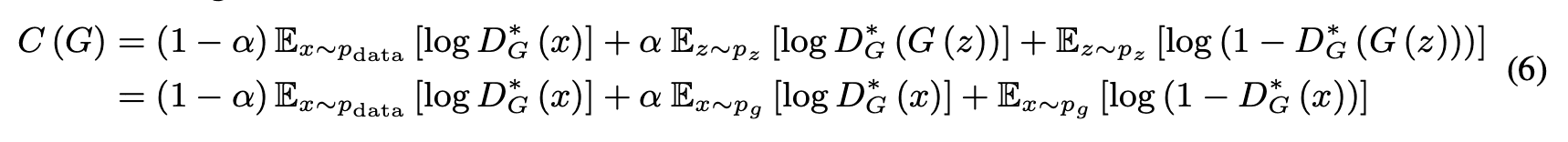
接下来,我们考虑$C(G)$的全球最小值。
命题2
当且仅当$p_g=p_{data}$时,$C(G)$是全局最小值,其中最小值为$C(G)=-/log 4$。
证明
1)当$p_g=p_{data}$时,从方程(4)来看,$D^*_G(x)=frac{1}{2}$。
将其代入方程(6),得到$C^*(G)=(1-α)logfrac{1}{2}+α\log{1}{2}+\log{1}{2}=-log4$。
2)从方程(5)来看
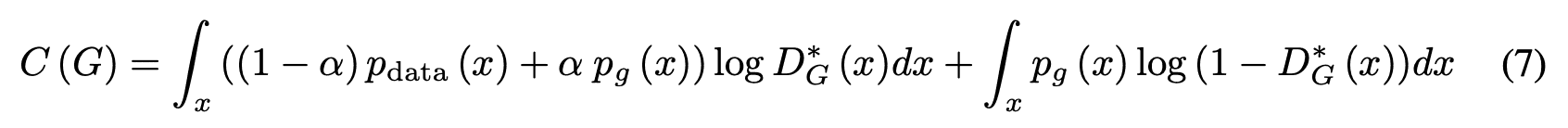
方程(6)是当$p_g=p_{data}$。
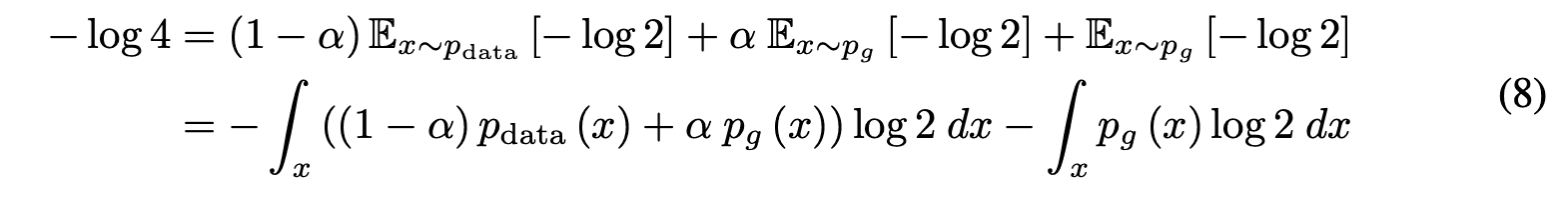
用方程(8)减去方程(7),得到
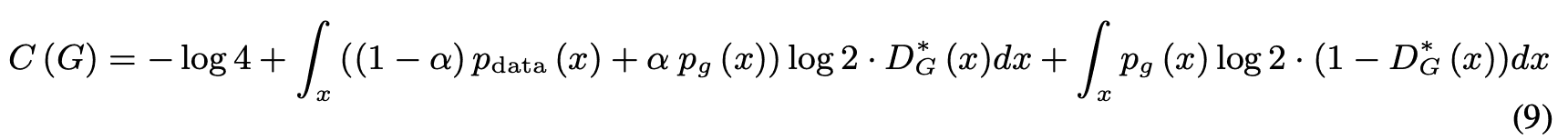
将方程(4)代入方程(9),我们得到
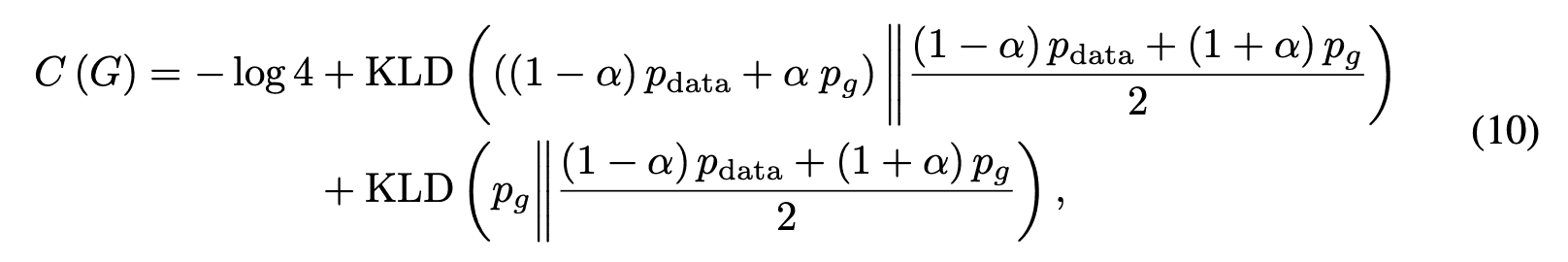
这里KLD是KL分歧。此外,方程(10)可以用JS发散JSD表示如下
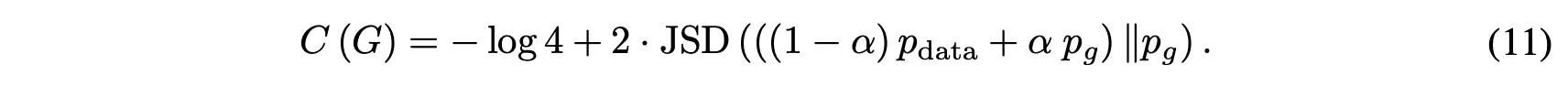
由于$JSD(P||Q)$在$P=Q$时取最小值为0,$C(G)$只有在${p_g}=p_{data}$时取最小值为$-log 4$。(证明完毕)
实验结果
在有限的数据量上进行训练。StyleGAN2和APA生成的图像如下所示。对于所有的数据集,StyleGAN2显示了退化,而APA几乎没有显示退化。

使用的评价指标是FID(Frechet Inception Distance)和IS(Inception Score),如下表所示:FID越低越好,IS越高,APA在所有数据集上的表现越好。

此外,对于FFHQ数据集,不同数量的训练数据的结果分别显示在下图和表中。同样,APA在所有模式的质量和数量上都优于StyleGAN2,表明APA在经过足够的数据训练后仍然有效。

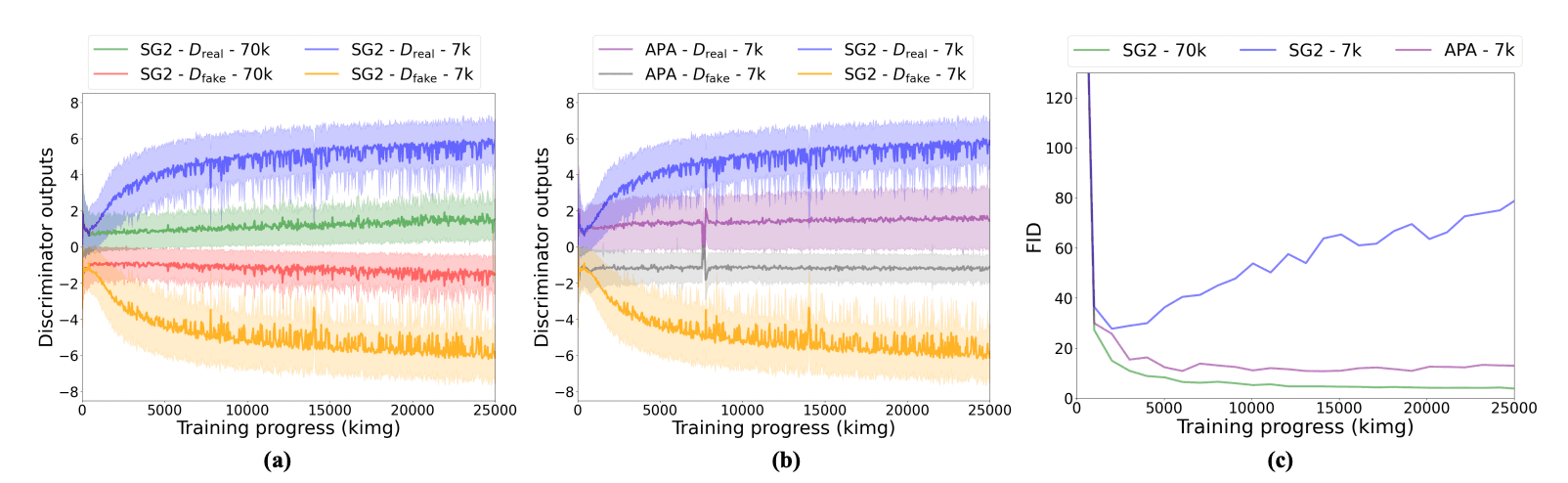
至于判别器的输出,在StyleGAN2的情况下,当数据数量变少时,真假预测概率的差异会扩大,如下图(a)所示,它变得过拟合,而APA的差异会缩小,如下图(b)所示,它的表现与用足够的数据量训练的StyleGAN2相似。至于FID,即使训练数据有限,APA也能收敛,如下图(c)所示。
最后,对于不同的参数$lambda, p$,对于真假标签反转,以及不同的阈值$t$的比较结果如下表所示,性能接近APA的主用值,比StyleGAN2好。

摘要
在本文中,我们提出了一种名为APA的方法,在GAN中从有限的数据中生成高度精确的图像。该结果比传统方法有了很大的改进,计算成本可以忽略不计,有望在未来的各种情况下得到应用。然而,该技术可以从有限的数据中生成高度准确的图像,有被滥用的风险,在处理数据集时应谨慎。



与本文相关的类别






