![使用梯度流改进生成的样品[ICLR2021]](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/September2021/dgflow_1_-min.png)
使用梯度流改进生成的样品[ICLR2021]
三个要点
✔️ 提高深度生成模型(DG$f$low)所产生的样本质量的方法建议(DG$f$low)
✔️ DG$f$low扩展到VAEs和归一化流量,这是明确处理可能性的生成模型。
✔️ 提高图像和文本数据集上生成样本的质量
Refining Deep Generative Models via Discriminator Gradient Flow
written by Abdul Fatir Ansari, Ming Liang Ang, Harold Soh
(Submitted on 1 Dec 2020 (v1), last revised 5 Jun 2021 (this version, v4))
Comments: Accepted by ICLR2021
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Machine Learning (stat.ML)
code:

本文所使用的图片要么来自该文件,要么是参照该文件制作的。
简介
深度生成模型是机器学习的一个最新发展领域。深度生成模型的目的是人为地生成与现实世界中存在的数据非常相似的数据。
深度学习模型之一是生成对抗网络(GAN),它由两类神经网络组成:判别器(Discriminator)用于判别真实数据和生成数据,生成器(Generator)用于生成样本。GANs通过使用最小优化来最小化真实和生成的数据分布之间的 "距离 "来学习。
由于GAN的目的是生成与真实数据非常相似的新数据,通常的做法是在训练完成后丢弃判别器,只使用生成器生成样本。
在这篇文章中,我们介绍了一个框架(DG$f$low),通过使用经过训练的Discriminator留下的真实数据分布的信息来改善劣质的生成样本。
什么是梯度流?
在我们讨论DG$F$low的具体内容之前,我们先来谈谈梯度流。梯度流是标量函数$F(x)$最小化过程中的 "最短路径"。
这里的 "最短路径 "是指在每个时间段的运动都是在减少$F$最多的方向。因此,梯度流$mathbf{x}(t)$满足以下方程
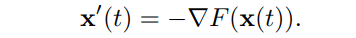
使用梯度流改进生成的样本(DG$f$low)
传统的深度生成模型的问题之一是,生成的数据质量会因潜伏空间的样本不同而有很大差异。为了提高生成模型的性能,重要的是要知道如何减少质量差的数据量。在DG$f$low中,我们提出了一种方法来提高生成模型的性能,而不需要丢弃质量差的样本,传统的做法是用Metropolis-Hastings方法来拒绝质量差的样本。
构建梯度流
我们考虑我们要最小化的$F$,作为构建梯度流的第一步。这与传统的GANs中的损失函数没有太大区别,后者是代表生成的数据分布与真实数据分布之间 "距离 "的$f$-分歧。然而,在模拟离散时间步长的梯度流时,加入了一个负熵项以确保多样性。函数$F$定义如下其中$mu$是真实数据的概率测量,$rho$是生成数据的概率测量。
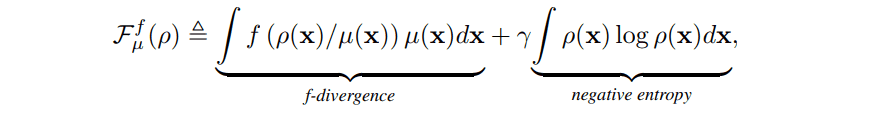
作为下一步,我们考虑$F$的梯度流。这种梯度流可以表示为Fokker-Plank方程,这是一种偏微分方程,而且已知满足该方程的$mathbf{x}$遵循McKean-Vlasov过程,这是一种随机过程。在每个时间点上的数据点$mathbf{x_t}$可以通过执行以下操作获得

从数据空间的改进到潜在空间的改进
(1)中的数值模拟表明,样本细化程序是在数据空间中进行的,但在图像等高维数据的情况下,误差会累积,生成的数据质量会恶化。我们修改了样本细化程序,使其在生成器为单次拍摄的条件下在潜空间中进行,经验表明,尽管对生成器的条件并不总是得到满足,但这一方法效果良好。
基于上述,DG$f$low的算法如下。

实验结果
对二维数据集进行验证
我们首先在一个二维人工数据集(25Gaussians[上],2DSwissroll[下])上检查了DG$f$low的性能。对于每个数据集,我们训练了WGAN-GP(蓝色),然后用包括DG$f$low(红色)在内的三种不同的方法来改进样本。
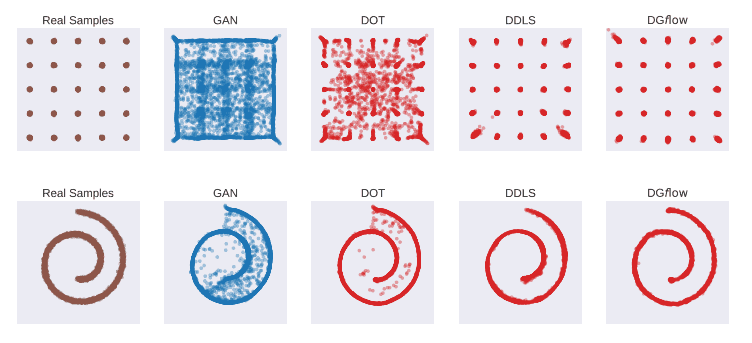
上图显示,WGAN-GP生成的一些样本与真实数据相差甚远,而DG$f$low和DDLS能够改善它们。
对图像数据集进行验证
对于图像数据的生成,我们使用CIFAR10和STL10数据集。有两个指标被用来评估生成的样本:Frechet Inception Distance(FID)和Inception Score(IS)。(在这篇博客中,我们将只处理FID的比较。)FID越小,措施越好。
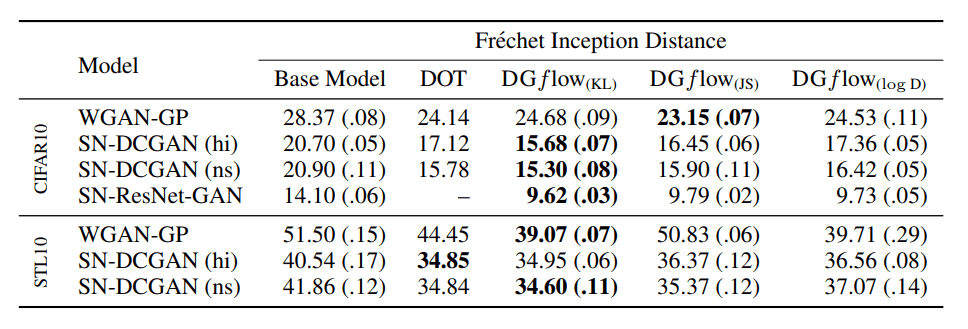
在上表中,我们对FID进行了比较。作为基础使用的深度生成模型是WGAN-GP、SN-DCGAN和SN-ResNet-GAN。这些都是GAN,其中判别器输出一个标量。在大多数情况下,这些方法的性能超过了传统DOT的性能。
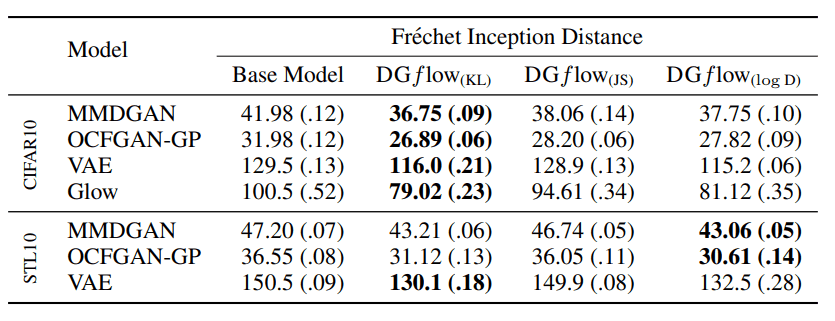
上表显示了以各种类型的深度生成模型为基础的测试结果。例如,MMDGAN是GAN的衍生物,其中判别器的输出是一个矢量。另外,VAE和Glow是深度生成模型,明确处理对数可能性,与GANs不同。事实证明,即使架构和生成模型不同,也可以用DGflow来改善样本。
对语言数据集进行验证
为了生成文本数据,我们使用了Billion Words Dataset,该数据集用于字符级语言建模,是一个由32个字符串组成的预处理数据集。为了评估生成的样本,我们使用生成的样本和真实数据n-grams之间计算的JS分歧。(JS-4, JS-6)

上表显示,对于文本数据,WGAN-GP生成的样本也被DG$f$low改进。
总结
你怎么看?DG$f$low是一个强大的框架,可以提高生成样本的质量,无论深度生成模型的类型如何(GAN、VAE、归一化流)。然而,梯度流模拟的时间步数是一个超参数,如何确定它是值得商榷的。有趣的是,该方法的名称是"$f$"(表示$f$发散)和 "flow"(表示梯度流)的组合。
如果您对梯度流数值模拟的理论背景感兴趣,请阅读原始论文!



与本文相关的类别






