在少量数据上训练GAN的技术
三个要点
✔️ 仅用10张纸就成功微调了GAN
✔️ 费舍尔信息很重要
✔️ 弹性重量巩固对GAN是有效的
Few-shot Image Generation with Elastic Weight Consolidation
written by Yijun Li, Richard Zhang, Jingwan Lu, Eli Shechtman
(Submitted on 4 Dec 2020)
Comments: Accepted by NeurIPS 2020.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
简介
近年来,许多GAN学习理论已经发表,GAN只能在大数据集上学习已经不再是事实。↓
如果你读了这两篇文章和这篇,你应该能赶上专注于用少量数据学习的GAN。我在这里要介绍的论文是关于只用10个数据对GANs进行微调的成功。下面的概述显示了我们想做的事情。

建议的方法
用少量的数据进行微调从根本上说是困难的。认为可以完美地推断出少量数据的分布通常是不合理的。这是同样的问题,因为从一个点推断出一条曲线显然是很困难的。因此,尝试使用一个预先学习的源域是很自然的。然而,一般来说,如果你让转移学习发生,在目标的性能在目标领域的表现良好然而,转移学习通常会导致在目标领域的良好表现,但在源领域的表现却急剧恶化(这种现象被称为灾难性遗忘)。(这种现象被称为灾难性遗忘。)这就是为什么任何试图使用源域的尝试都不会成功。
所以我们的主要技术是弹性重量巩固(持续学习)。持续学习与转移学习相似,但框架略有不同。持续学习已经在AI-SCHOLAR的文章中解释过了,请查看这篇文章。→(学习持续学习。选择性可塑性的元学习和预防灾难性遗忘!)
在这篇文章中,我们将展示如何将弹性权重整合应用于GANs,以及如何用它来学习少量的数据,这在GANs中很难做到。
弹性重量巩固
作者假定,目标域有一个假设有大量的数据可以用来训练生成模型,他们进行实验,以获得关于好的权重可能是什么样子的灵感。
大规模的我们收集了源数据和大规模的目标数据,并使用5层的DCGAN测量了权重的变化率。结果如下图所示。
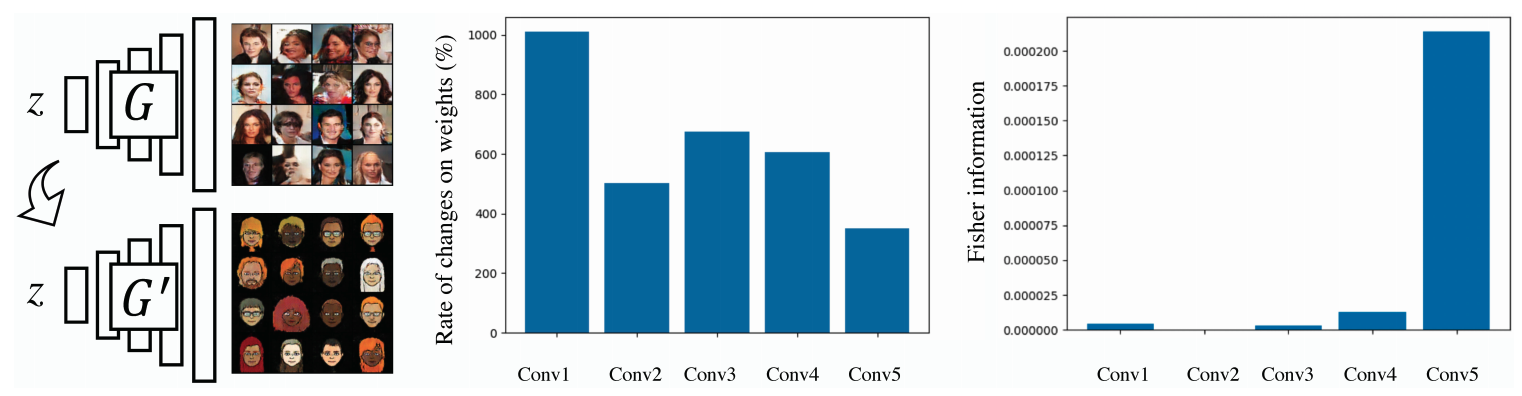
我们在这里发现了一些重要的东西!也就是说,最后一层(Conv5)的权重变化率要比Conv1小。事实证明,初始层中从源数据学到的权重并不重要,因为它们在学习目标领域时发生了很大的变化,而最后一层对源数据和目标数据都有更重要的权重。与其说是简单的微调,不如说是通过更容易保留最后一层的重要权重来提高微调的成功率。这意味着不同层的权重应以不同方式规范化。
下一个问题是如何量化或衡量这些权重中每一个的重要性。如果你有良好的直觉,你会注意到每个重量的重要性都可以被量化或测量。回顾一下,在数学统计中,Fisher信息F可以表明在给定观察值的情况下,一个模型的参数可以被估计得多好。(费雪信息教程)
给定源域的预训练生成模型,通过生成一定数量的数据$X$,给定网络参数$θ_s$的训练值,可以计算出Fisher信息$F$,如下所示
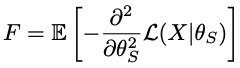
$L(X|θ_s)$是对数似然函数,相当于用判别器的输出计算二元交叉熵损失。
为了简单起见,使用判别器的输出,在真实人脸图像上训练的G模型的不同层的权重的平均F显示在上图的右边。很明显,我们可以看到最后一层的权重比其他层的权重高得多。考虑到权重的变化率,我们可以直接使用$F$作为权重重要性的衡量标准,并增加一个正则化损失来惩罚权重在适应目标区域期间的变化。
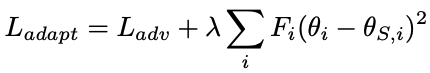

因此,在预学习之后,$F$被存储起来,并在微调期间使用$F$进行正则化。
定性评价
我们将看到NST、BSA和MineGAN的实际生成结果的比较,用10个Emoji数据对FFHQ训练的模型进行微调。

结果很明显:所有其他方法都不能正常生成。MineGAN似乎也能生成,但它显然训练过度。建议的方法能够从源头上继承多样性,因为它生成的图像不在训练数据中。
实验还表明,源域和目标域之间的差距越大,其成功率就越低。

CelebA-Female和Emoji的效果相对较好,因为差距很小,但Color pencil landscape却不能正常生成,因为差距太大。
量化评价
FID和LPIPS对10幅图像进行微调,并对用户进行主观评价(在图像对中选择生成的图像时的错误率)。

通过比较,可以看出其准确性很高。此外,用户评价也明显比其他方法更准确。
摘要
弹性权重整合在训练GAN方面效果很好,与其他方法相比,该方法的准确性是压倒性的。该方法也相当简单,容易理解。



与本文相关的类别





