
GT-GAN,它也统一了缺失的数据列,并实现了时间序列数据的合成。
三个要点
✔️ 在时间序列数据合成中,传统上很难在一个生成模型中处理规则数据和具有缺失数据的不规则数据
✔️ GT-GAN是一个GAN、自动编码器、神经常微分方程、神经控制微分方程和连续时间流过程它是三个数据流结合模型的综合体。
✔️ 不规则数据通过解码器中的常微分方程,从隐藏矢量数据反向传播到生成器,以及统一的数据生成,也有规则数据的补充。
AutoFormer: Searching Transformers for Visual Recognition
written by Jinsung Jeon, Jeonghak Kim, Haryong Song, Seunghyeon Cho, Noseong Park
(Submitted on 5 Oct 2022 (v1), last revised 11 Oct 2022 (this version, v3))
Comments: NeurIPs 2022
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
概述
这是一篇NeurIPS 2022年接受的论文。时间序列合成是深度学习领域的重要研究课题之一,可用于数据增量。时间序列数据大致可分为规则和不规则(故障序列)。然而,对于这两种类型,现有的生成模型都没有在不修改模型的情况下表现出良好的性能。因此,我们提出了一个通用模型,可以合成规则和不规则的时间序列数据。据我们所知,本文是第一个为时间序列合成中最具挑战性的环境之一设计通用模型的文章。为此,我们设计了一种基于生成对抗网络的方法,并将许多相关的技术,从神经普通/控制微分方程到连续时间流动过程,仔细地整合到一个单一的框架中。该方法优于所有现有的方法。
介绍。
由于现实世界中的时间序列数据经常是不平衡和/或不充分的,综合时间序列数据已成为与时间序列相关的众多任务中最重要的一项。然而,由于定期和不定期的时间序列数据具有不同的特点,对两者都采用了不同的模型设计。因此,现有的时间序列合成研究集中在规则或不规则时间序列的合成上[Yoon等人,2019,Alaa等人,2021]。据我们所知,目前还没有对这两种类型都能很好工作的现有方法。
有规律的时间序列指的是有规律的抽样观察,没有缺失值,而不规律的时间序列指的是一些观察值时常缺失。不规则时间序列比规则时间序列更难处理。例如,众所周知,在将时间序列数据转化为其频域,即傅里叶变换后,神经网络的性能会得到改善,一些时间序列生成模型采用了这种方法[Alaa等人,2021]。然而,要从高度不规则的时间序列中观察到预先确定的频率并不容易[Kidger等人,2019]。在此,连续时间模型[Chen等人,2018,Kidger等人,2020,Brouwer等人,2019]在处理规则和不规则时间序列方面都表现出良好的性能。在它们的基础上,本文提出了一个通用模型,可以在不修改模型的情况下合成两种时间序列类型。
为了实现其目标,该方法使用了多种技术,从生成对抗网络(GANs[Goodfellow等人,2014])、自动编码器(AEs)到神经常微分方程(NODEs[Chen等人,2018])、神经控制微分方程(NCDEs [Kidger等人,2020])和连续时间流过程(CTFPs[Deng等人,2020]),到利用各种技术设计复杂的模型。这反映了问题的难度 。
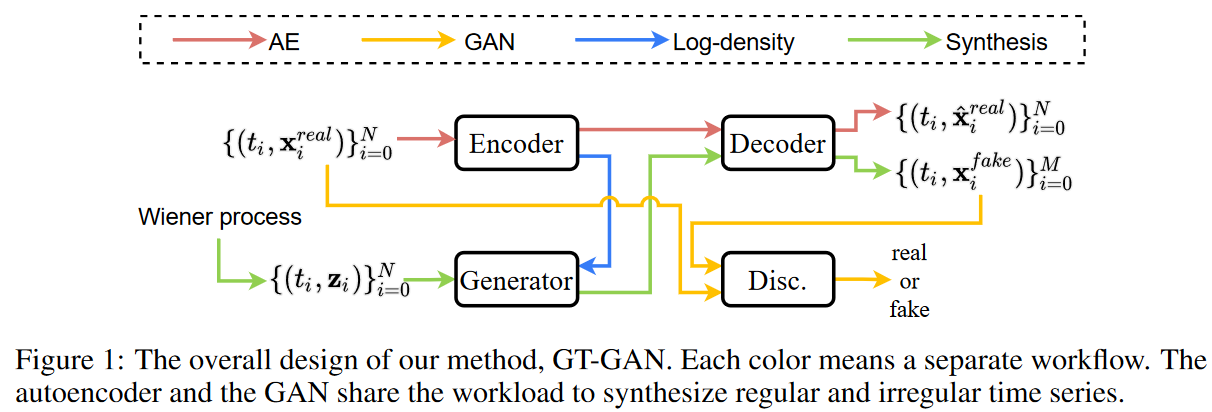
图1显示了拟议方法的整体设计。所提方法的关键点是,它在一个框架内结合了GANs的对抗性学习和CTFP的精确最大似然学习。然而,精确最大似然学习只适用于输入和输出具有相同大小的可逆映射函数。因此,在本文中,我们设计了一个可逆生成器,并采用了一个自动编码器,其中GAN在其隐藏空间进行对抗性学习。也就是说、
i) 编码器的隐藏向量大小与发生器的噪声向量相同,并且
生成器生成一组错误的隐藏向量,并在此基础上生成一个新的隐藏向量。
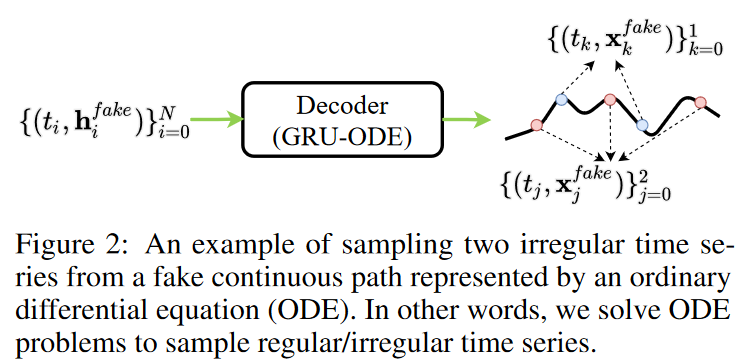
iii) 解码器将这组数据转换为假的连续路径(见图2),并且
iv) 鉴别器读取采样的虚假样本并提供反馈。
我们在此强调,在第三步中,解码器创建了一个虚假的连续路径。因此,任何有规律/无规律的时间序列样本都可以从假的路径中取样,显示了该方法的灵活性。
使用四个数据集和七个基线进行了实验。 对有规律和无规律的时间序列都进行了测试。该方法在两种环境下的表现都优于其他基线。
这一方法的贡献可以概括为以下几点
1.基于各种最先进的深度学习技术设计模型。该方法能够处理所有类型的时间序列数据,从规则的到不规则的,不需要修改模型。
2. 通过实验结果和可视化证明所提出的模型的有效性。
3.由于我们的任务是时间序列合成中最具挑战性的任务之一,所提出的模型的结构是经过精心设计的。
4.隔离研究表明,如果缺少任何部分,所提出的模型都不能很好地工作。
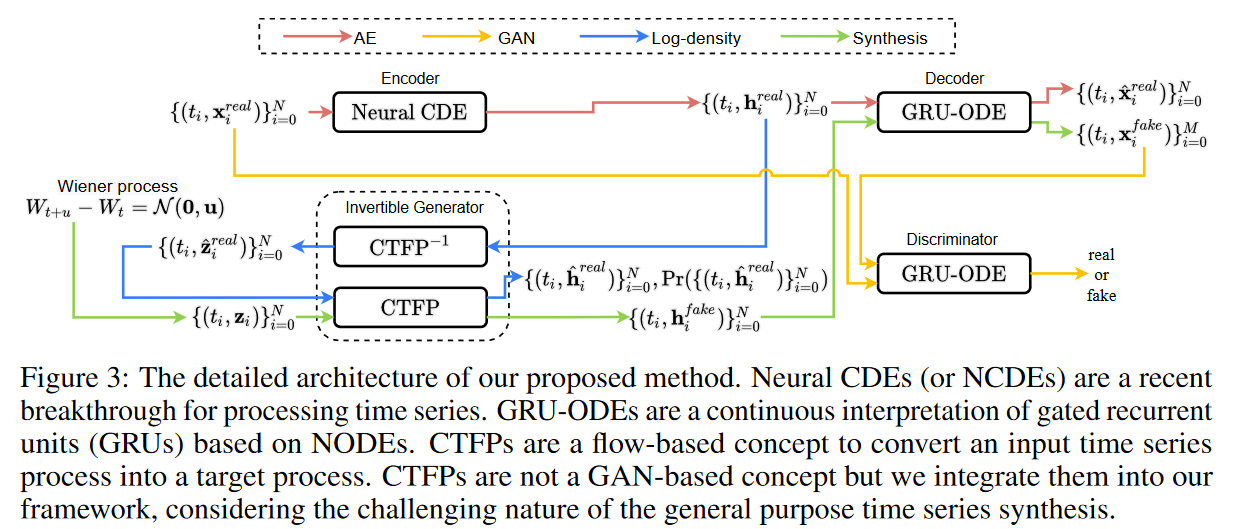
建议的方法
时间序列合成是一项具有挑战性的任务,所提出的设计要比其他基线复杂得多。
整体工作流程。
首先,整个工作流程包括几个不同的数据路径(和几个基于数据路径的不同学习方法),如下所述。
1.自动编码器路径
给定一个时间序列样本,编码器生成一组隐藏向量。解码器恢复一个连续的路径,这增加了拟议方法的灵活性。从这个路径进行采样。编码器和解码器使用标准的自动编码器(AE)损失进行训练,以匹配所有采样点的连续路径和采样值。
2.敌对的渠道
给定一个噪声向量,生成器生成一组虚假的隐藏向量。解码器从虚假的隐藏向量中恢复虚假的连续路径。对于不规则时间序列的合成,tj 的采样点是[0, T]。生成器、解码器和鉴别器用标准的对抗性损失进行训练。
3.对数密度途径
给定一组时间序列样本的隐藏向量,发生器的逆向传递再生出噪声向量。在正向传递期间,受Grover等人[2018]和Deng等人[2020]的启发,用变量变化定理计算每个采样点i的负对数概率,然后将其最小化并学习。
特别是要注意,自动编码器的隐藏空间的维度与生成器的潜在输入空间的维度相同,即dim(h)= dim(z)。这对于生成器中的精确似然学习是必要的。为了估计精确似然,变量变化定理要求输入和输出的大小是相同的。除此之外,合成虚假时间序列的任务是通过将自动编码器和生成器整合到一个框架中来完成的。换句话说,生成器合成虚假的隐藏向量,而解码器则从这些向量中再生出人类可读的虚假时间序列。
自动编码器
编码器
一个通用的NCDE被认为是循环神经网络(RNN)的连续类似物,定义如下。
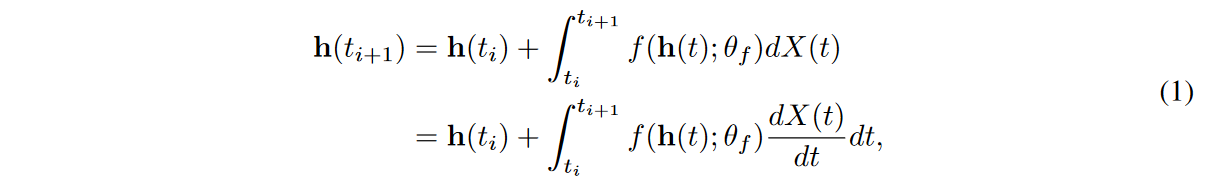
其中X(t)是插值算法 从原始离散时间序列样本{(ti,xreal i )}N i=0创建的连续路径,其中 X(ti)= (ti, xreal i )为所有i,对于其他未观察到的时间点,插值算法填入值注意,NCDE继续读取X(t)的时间导数。在这种情况下,它收集{hreal i }N i=0,如下所示。
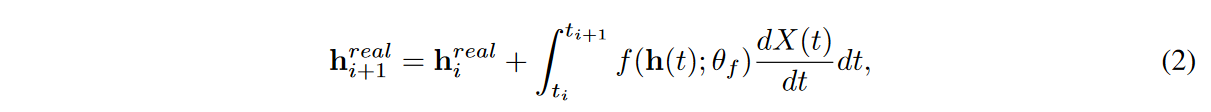
其中hreal 0 = FCdim(x)→dim(h)(xreal 0 ),FCinput_size→output_size 是具有特定输入和输出大小的全连接层。 因此,输入时间序列{(ti,xreal i )}N i=0由一组隐藏向量{(ti, hreal i )}N i=0表示。NCDEs是RNNs的连续类似物,因此最适合处理不规则时间序列[Kidger等人,2020]。
解码器
这种从隐性表征重现时间序列的方法的解码器是基于GRU-ODE[Brouwer等,2019],定义如下。
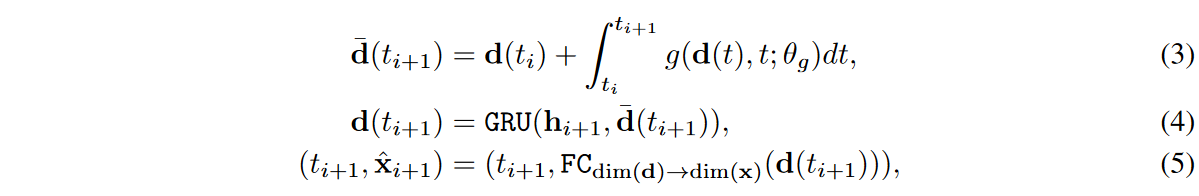
其中d(t0)= FCdim(h) → dim(d)(h0),hi 表示第i个真实或虚假的隐藏向量,即hreal i 或hfake i 。 回顾一下,在图3中,解码器同时参与了自动编码和合成过程;GRU-ODE使用一种叫做神经常微分方程(NODE)的技术来连续解释GRU。
特别是,方程(4)中的门控递归单元(GRU)被称为跳跃,已知其对NODE的时间序列处理是有效的[Brouwer等人,2019,Jia和Benson,2019] 。对于所有训练的时间序列样本,使用xreal i和ˆxreal i之间的标准重建损失来训练编码器-解码器,对于所有i。
通用敌方网络
发电机
在标准的GAN中,生成器通常通过读取噪声矢量来产生虚假样本,而本方法中的生成器通过读取从维纳过程中采样的连续路径(或时间序列)来产生虚假的时间序列样本。这种生成概念被称为连续时间流过程(CTFP[Deng等人,2020])。该方法的生成过程的输入是一个从维纳过程中采样的随机路径,由该路径的潜在向量的时间序列表示,输出是一个隐藏向量路径,也由隐藏向量的时间序列表示。
因此,发电机可以写成如下。
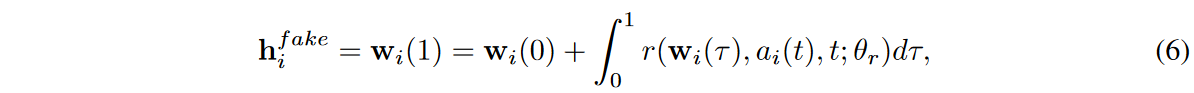
其中τ是积分问题的虚拟时间变量,ti是时间序列样本{(ti,xreal i )}M i=0中包含的真实物理时间。要强调的是,这种设计对应于由ai(t)扩展的NODE模型。
由于NODE的可逆性,hreal i的确切对数密度,即hreal i由生成器生成的概率,可以使用变量变化定理和Hutchinson的随机跟踪估计器计算如下[Graswohl等人,2019,Deng等人、2020].
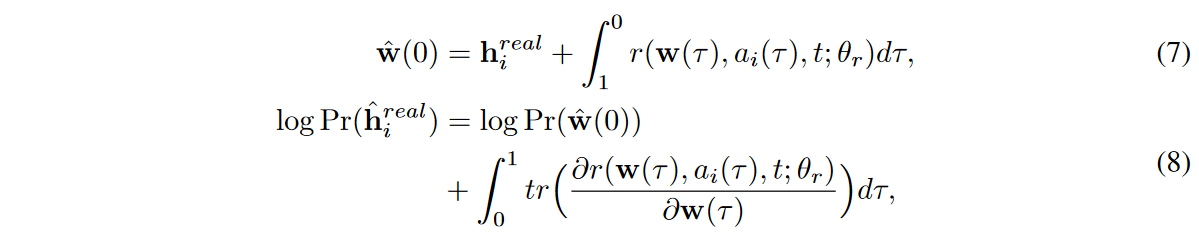
方程(7)对应于图3中的'CTFP-1',而方程(6)和(8)对应于'CTFP'。请注意,在方程(7)中,为了解决反模式积分问题,积分时间是相反的。因此,我们对每个ti的负对数密度进行最小化,并在两种不同的学习范式中训练生成器:i)对判别器的对抗性学习,以及ii)使用对数密度的最大似然估计器(MLE)学习。
鉴别器
基于GRU-ODE技术,识别器设计如下
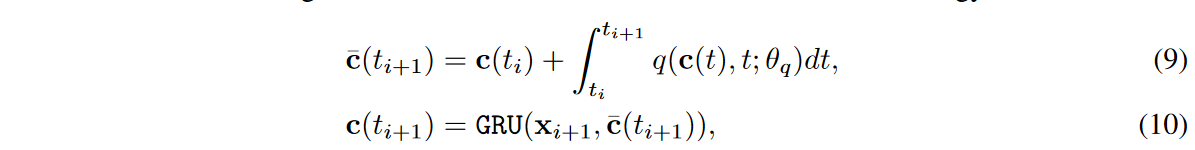
其中c(t0)= FCdim(x) → dim(c)(x0),xi表示第i个时间序列值,即xreal i 或xfake i。ODE函数q的结构与g相同,但有自己的参数 θq 。 然后计算出真假分类y = σ(FCdim(c) → 2(c(tN ))),其中σ是软最大激活。
学习的方法
编码器-解码器的训练采用平均平方修复损失,即所有i的‖xreal i -ˆ xreal i ‖22 的平均数。然后用标准的GAN损失来训练生成器和鉴别器。初步实验表明,原始的GAN损失适用于本方法的任务。因此,我们使用标准GAN损失,而不是其他变体,如WGAN-GP[Gulrajani等人,2017]。我们按照以下顺序训练模型。
1. 预先训练编码器-解码器网络的KAE迭代的重新配置损失。
2.在KJOINT迭代中,经过上述预训练后,所有网络的联合学习按以下顺序开始:i)编码器-解码器网络用重建损失训练,ii)识别器和生成器的网络用GAN损失训练,iii)改善分类器分类输出的解码器用鉴别器损失训练在每次PMLE迭代中用MLE损失学习生成器,iv)在每次PMLE迭代中用MLE损失训练生成器,因为发现太频繁的MLE学习会导致模式崩溃。
特别是,训练解码器以帮助判别器的2-ii步骤是自动编码器和GANs被整合到一个单一框架中的一个额外点。这意味着生成器需要同时欺骗解码器和判别器。
在Lipschitz连续性的温和条件下,NCDE和GRU-ODE的良好设置性(well-posedness)已经在Lyons等人[2007,定理1.3]和Brouwer等人[2019]中被证明。本文表明,该方法的NCDE层也是一个很好的设置问题:几乎所有的激活函数,如ReLU、Leaky ReLU、SoftPlus、Tanh、Sigmoid、ArcTan和Softsign的Lipschitz常数为1,并且不存在丢弃、批量正常化或其他其他常见的神经网络层,如集合方法,有明确的Lipschitz常数的值。因此,在这种方法的情况下,ODE/CDE函数的Lipschitz连续性也可以得到满足。换句话说,这是一个很好解决的学习问题。因此,我们的学习算法解决了一个好集问题,其学习过程实际上是稳定的。
实验评价
实验环境
数据集。
本文在两个模拟数据集和两个真实世界数据集上进行了实验;正弦波有五个特征,每个特征在不同的频率和相位上独立创建。对于每个特征,i∈{1, ., 5},xi(t) = sin(2πfit + θi),其中efi∼U [0, 1],θi∼U [-π, π];MuJoCo是具有14个特征的多变量物理模拟时间序列数据;Stocks是2004至2019年的谷歌股票价格数据Stocks是2004年到2019年的谷歌股票价格数据。每个观察值代表一天,有6个特征;Energy是UCI家电能源预测数据集,有28个值。为了创造一个具有挑战性的随机环境,每个时间序列样本{(ti, xreal i )}N i=0到30,50,70%的观测值被随机丢弃。丢弃随机值在文献中主要用于创建不规则的时间序列环境[Kidger等人,2019,Xu和Xie,2020,Huang等人,2020b,Tang等人,2020,Zhang等人,2021,Jhin等人。., 2021, Deng等人, 2021]。因此,我们在常规和非常规环境中都进行了实验。
基线。
对于有规律的时间序列的实验,考虑了以下基线:timeGAN、RCGAN、C-RNN-GAN、WaveGAN、WaveNet、T-Forcing和P-Forcing。在不规则实验中,排除了不能处理不规则时间序列的WaveGAN和WaveNet,其他基线被重新设计,其GRU被GRU-4t和GRU-Decay(GRU-D)取代[Che et al, 2018]。数据;GRU-4t另外使用观测值之间的时间差作为输入;GRU-D是对GRU-4t的修改,学习观测值之间的指数衰减;TimeGAN-4t、RCGAN-4t、C-RNN-GAN-4t、T-Forcing-4t, P-Forcing-4t (resp. TimeGAN-D, RCGAN-D, C-RNN-GAN-D, T-Forcing-D, P-Forcing-Decay)在GRU-4t(resp. GRU-D)中被修改,以便能够处理不规则数据。此外,许多先进的方法,如NODE、VAE和流动模型被用于我们的消融研究中。建议的方法将这些先进的方法作为内部的子部分,所以我们敢于在消融研究中留下它们。
评价指标
对于合成数据的定量评价,用TimeGAN[Yoon等人,2019]中使用的判别性和预测性分数进行评价。鉴别性分数衡量原始数据和合成数据之间的相似度。在使用神经网络训练一个模型对原始数据和合成数据进行分类后,测试原始数据和合成数据是否得到良好的分类。辨别分数为|准确率-0.5|,分数低说明原始数据和合成数据相似,因为分类困难。预测得分使用训练-合成-测试-真实(TSTR)方法衡量合成数据的有效性。在使用合成数据训练模型预测下一步后,计算预测值和测试数据的真实值之间的平均绝对误差(MAE);如果MAE小,则认为在合成数据上训练的模型与原始数据相似。为了进行定性评价,将合成的数据与原始数据进行可视化处理。有两种可视化的方法。一种是用t-SNE[Van der Maaten and Hinton, 2008]将原始数据和合成数据投影到一个二维空间。另一种是用核密度估计法画出数据的分布。
实验结果
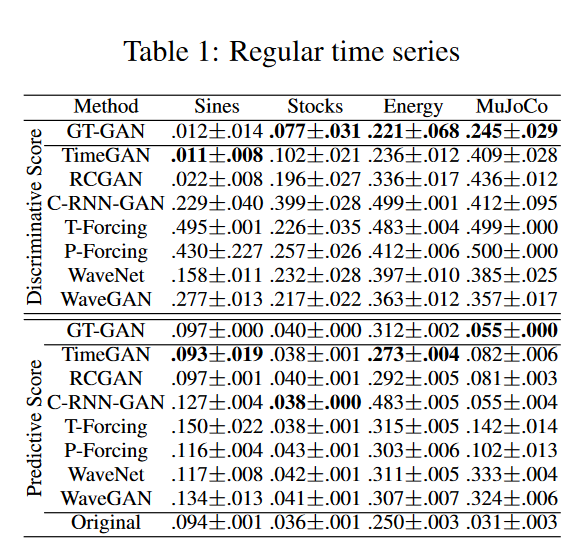
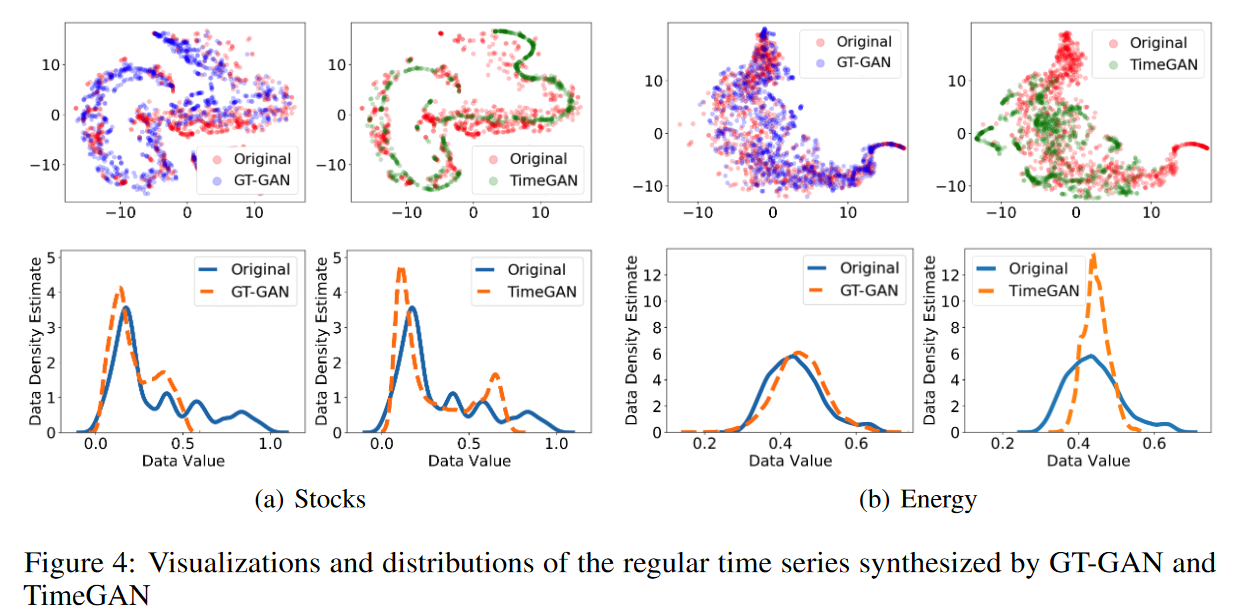
正常时间序列的合成。
表1列出了常规时间序列合成的结果,GT-GAN在大多数情况下比传统的最先进的模型TimeGAN表现更好,如图4第一行所示,GT-GAN比TimeGAN更能覆盖原始数据域。图4第一行显示,GT-GAN比TimeGAN更好地覆盖了原始数据区域。图4第二行显示了GT-GAN和TimeGAN生成的假数据的分布:GT-GAN的合成数据的分布比TimeGAN更接近原始数据的分布,说明GT-GAN的显性似然学习比TimeGAN的隐性似然学习更有效。
.不规则时间序列的合成。
表2、3和4列出了不规则时间序列合成的结果;GT-GAN在所有情况下都显示出比其他基线更好的识别和预测分数;在表2中,当从每个时间序列样本中随机删除30%的观测值时,GT-GAN明显优于TimeGAN,显示出最好的结果,而用GRU-4t和GRU-Decay修改的基线显示出相当的结果,所以在这个表中无法说哪个更好。

在表3(下降50%)中,许多基线没有显示出合理的综合质量,例如,TimeGAND、TimeGAN-4t、RCGAN-D、C-RNN-GAN-D和C-RNN-GAN-4t的区分度为0.5分。令人惊讶的是,T-Forcing-D、T-Forcing-4t、P-Forcing-D和P-Forcing-4t在这种情况下表现良好。然而,该方法的模型在所有的数据集中显然表现最好:用GRU-4t修改的基线在这种情况下比用GRU-Decay修改的基线表现略好。

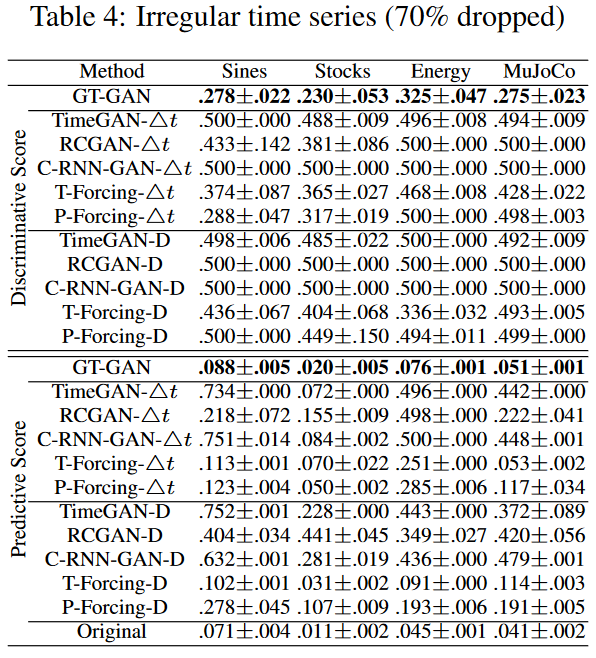
最后,表4(70% 掉线)显示了本文中最具挑战性的实验结果。所有的基线都因为高丢弃率而表现不佳,尽管T-ForcingD、T-Forcing-4t、P-Forcing-D和P-Forcing-4t在丢弃率不超过50%时表现出合理的性能。这表明它们容易受到高度不规则的时间序列数据的影响。其他基于GAN的基线也同样脆弱。我们的方法明显优于所有现有的方法,例如Sines对GT-GAN的识别得分为0.278,T-Forcing-D为0.436,P-Forcing4t为0.288;MuJoCo对GT-GAN的预测得分为0.051,T-Forcing-D为0.图5显示了我们的方法和表现最好的基线之间的视觉比较。
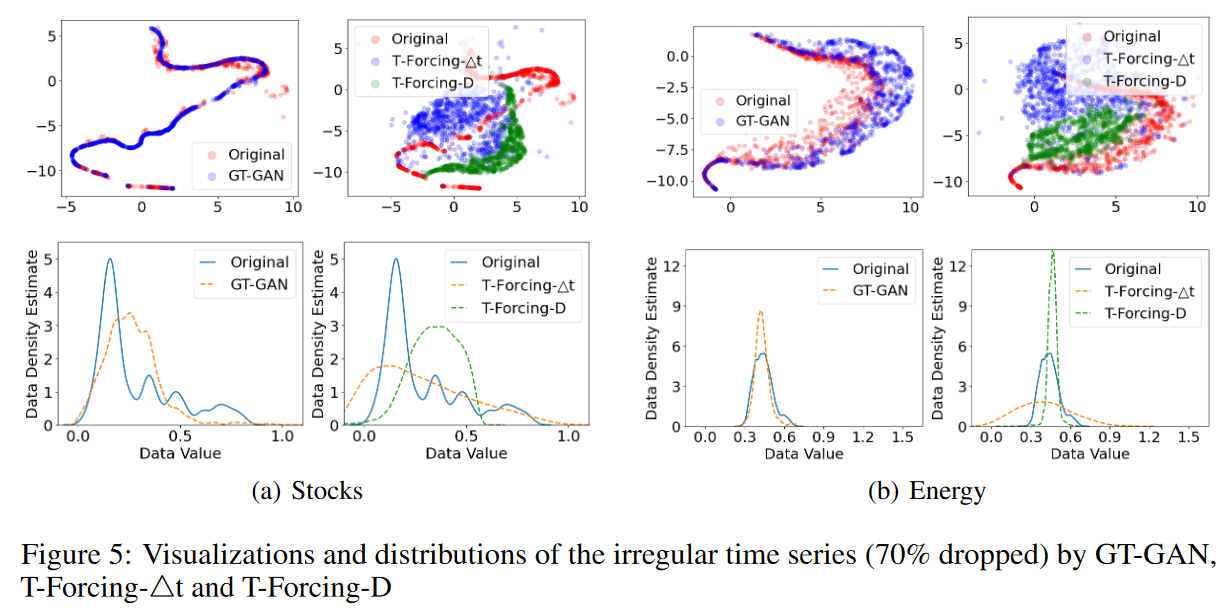
隔离和敏感性分析
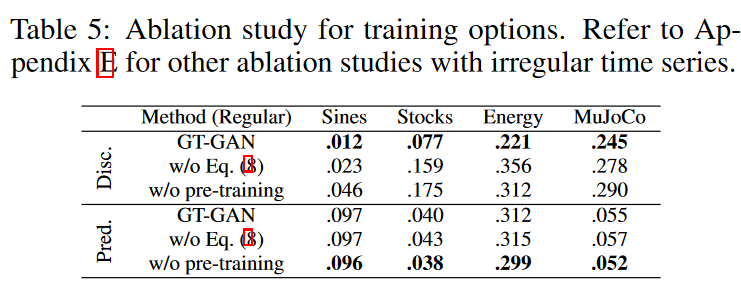
GT-GAN的特点是使用方程(8)中的负对数密度进行MLE学习,并对编码器和解码器进行预训练表5显示了去除一些学习机制后各种GT-GAN的修改结果。有负对数密度学习的模型比没有的模型表现更好。换句话说,MLE学习使合成数据更接近于真实数据。没有预训练的自动编码器,预测得分比GT-GAN好。然而,区分度得分是最差的。
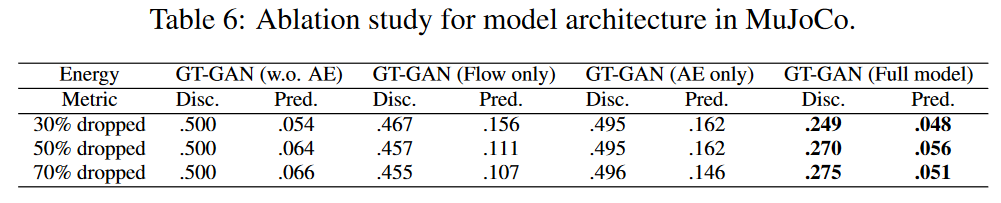
在表6中,该方法的模型架构已经被修改。
i) 在第一个分割模型中,自动编码器被移除,仅使用生成器和鉴别器进行对抗性学习(被称为GT-GAN(w.o. AE))。
ii) 第二个分割模型(GT-GAN(仅流))只有一个基于CTFP的发生器,并通过最大似然法训练。该模型等同于原始的CTFP模型[Deng等人,2020]。
iii) 第三个分割模型只有一个自动编码器,被表示为 "GT-GAN(仅AE)"。然而,它转换为一个变异自动编码器(VAE)模型:在完整的GT-GAN模型中,编码器产生隐藏向量{(ti,hreal i )}N i=0 ,但在这个分割模型中,它变为{(ti, N(hreal i, 1))}N i=0 和其中N (hreal i, 1)被认为是指以hreal i 为中心的单位高斯。解码器与完整模型中的相同。这个模型使用了变异学习。
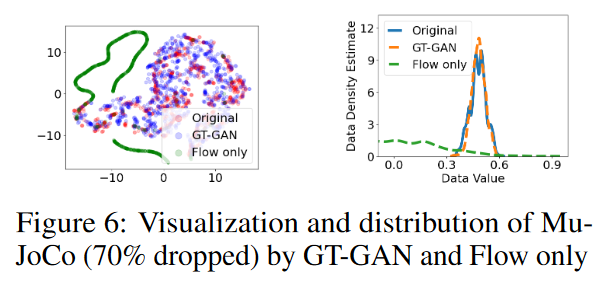
在分离模型中,GT-GAN(仅Flow)在大多数情况下都优于判别器的得分。然而,在所有情况下,该方法的完整模型显然是最好的。本文的研究表明,当任何部分缺失时,GT-GAN截断模型的表现不如其完整模型好,如表6所示。
显著影响模型性能的超参数是发生器的绝对公差(atol)、相对公差(rtol)和MLE训练的周期(PMLE)。atol和rtol决定了CTFP的ODE求解器所进行的误差控制。结果显示,根据数据输入大小,有适当的误差容限(atol, rtol)。例如,发现输入规模小的数据集(如正弦波、股票)在(1e-2,1e-3)时获得良好的辨别分数,输入规模大的数据集(如能源、MuJoCo)在(1e-3,1e-2)。
相关研究
GAN是最具代表性的生成技术之一。自从在一篇开创性的研究论文中首次提出以来,GANs已经被运用于各种主要学科。近年来,用于时间序列数据的GANs的合成得到了越来越多的关注。为此,人们提出了几种用于时间序列数据合成的GAN:C-RNN-GAN[Mogren, 2016]通过使用LSTM作为生成器和判别器,具有适用于顺序数据的通常GAN框架;Recurrent ConditionalGAN(RCGAN[Esteban等人,2017])有一个类似的方法,只是它的生成器和判别器采取了条件输入,以便更好地进行合成;WaveNet[van den Oord等人,2016]也使用了扩展的随意卷积与来从历史数据的条件概率中生成时间序列数据。
WaveGAN[Donahue等人,2019]是一种类似于DCGAN[Radford等人,2016]的方法,其生成器基于WaveNet;虽然它不是一个GAN模型,但它可以被修改为从教师强迫(T-Forcing [Graves, 2014])和教授强迫(P-Forcing [Lamb et al., 2016])模型可以被修改为从噪声向量中生成时间序列数据,利用TimeGAN[Yoon et al., 2019]的预测特性,这是一个进一步的另一个用于时间序列合成的模型。这些模型主要是为了合成虚假的规则时间序列样本。他们提出了一个框架,其中GAN是对抗性和监督性学习,从xi预测xi+1,其中xi和xi+1分别指时间ti和ti+1的两个多元时间序列值。
摘要
时间序列合成是深度学习的一个重要研究课题,人们分别对规则和不规则时间序列合成进行了研究。然而,目前还没有现成的生成模型可以在不修改模型的情况下同时处理规则和不规则时间序列。所提出的方法,GT-GAN,是基于从GAN到NODE和NCDE的各种先进的深度学习技术,能够处理所有可能的时间序列类型,而不需要对模型结构或参数进行任何修改。纳入各种合成和真实世界数据集的实验已经证明了所提方法的有效性。在对切分的研究中,只有没有缺失部分的完整方法显示了合理的合成能力。
(文章作者)整个复杂模型在训练时的稳定性没有详细说明,但假设神经控制微分方程和常微分方程部分有良好的设置和稳定性。



与本文相关的类别






