
预先训练好的模型作为GAN! 什么是Projected GAN,甚至比StyleGAN2-ADA更好!
三个要点
✔️ 最先进的模型 "Projected GAN "的解释。
✔️ 使用预训练模型的特征表示作为判别器
✔️ 在FID得分、收敛速度和样本效率方面优于现有方法
Projected GANs Converge Faster
written by Axel Sauer, Kashyap Chitta, Jens Müller, Andreas Geiger
(Submitted on 1 Nov 2021)
Comments: NeurIPS 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
生成对抗网络(GANs)的使用取得了巨大的成功,包括用于图像生成,但它们面临各种挑战,如学习不稳定、巨大的计算成本和超参数调整。
在这篇文章中,通过在Discriminator中适当使用预训练模型的表示方法,我们提高了生成图像的质量、采样效率和收敛速度,并显示出比StyleGAN2-ADA和FastGAN(在本网站的文章中描述)更好的结果。

建议的方法(预测的GAN)。
GAN由一个生成器$G$和一个判别器$D$组成。
其中$G$是一个从简单分布(通常是正态分布)$P_z$中取样的潜在向量$z$,以产生相应的样本$G(z)$。
D$也被训练来区分真实样本$x~P_x$和生成样本$G(z)~P_{G(z)}$。
在这种情况下,GAN的目标函数由以下公式表示

在所提出的方法中,即投影GAN,我们引入了一组特征投影器${P_l\}$,将真实的和生成的图像转化为判别器的输入空间。在这种情况下,上述的目标函数被以下的方程式所取代

这里,${D_l\}$是对应于${P_l\}$中不同特征投影仪$P_l$的判别器集合。接下来,我们将讨论生成器、判别器和特征投射器的更具体配置。
模型概述
在Projected GANs中,生成器来自现有的GAN方法(StyleGAN2-ADA,FastGAN等)。因此,本节主要讨论判别器$D_l$和特征投影器$P_l$。
多尺度判别器
正如介绍中所解释的,Projected GAN使用一个预训练模型的表征作为判别器。
具体来说,我们从预先训练好的网络$F$的四层(分辨率分别为$L_1=64^2,L_2=32^2,L_3=16^2和L_4=8^2$)获得特征。然后我们将每个分辨率的特征通过一个特征投影仪$P_l$,并引入一个简单的卷积结构作为相应的判别器$D_l$。大致上,结构如下。
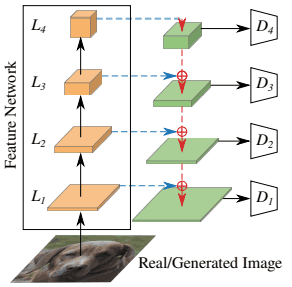
如该图所示,对于每个层的表示,$L_1,.,L_4$的预训练模型通过特征投影仪并输入到相应的判别器$D_1,...,D_4$。D_4$.同时,判别器$D_l$都被设置为4x4$的输出分辨率(通过调整下采样层的数量),这些对数被加起来计算出总的损失。
此外,鉴别器的结构如下

关于表格,DB(DownBlock)由内核大小为4、步长为2的卷积、BatchNorm和LeakyReLU(斜率为0.2)组成。同时,光谱归一化被应用于所有卷积层。
随机功能投影仪
其次,特征投影仪由两部分组成,CCM(跨通道混合)和CSM(跨饼混合)。这些都是随机的和固定的,在训练期间不更新(只有生成器和鉴别器在训练期间更新)。
CCM(跨渠道混合)。
跨渠道混合(CCM)通过对从预训练模型中获得的特征进行随机的1x1$卷积运算,在渠道层面混合特征。这与下图中的蓝色箭头相对应。
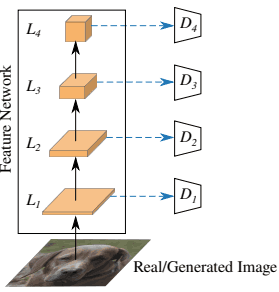
这个卷积层的权重是通过Kaiming初始化随机初始化的。
CSM(跨尺度混合)。
跨尺度混合(CSM)由一个3x3美元的卷积层和一个双线性上采样层组成,混合不同分辨率的特征,如下图所示。
CSM与图中的红色箭头相对应。随着这一过程的加入,该架构变得类似于U-Net。
与CCM中一样,权重是随机初始化的。
关于预训练的模型
有各种可能的预训练模型用于特征提取,但在原始论文的实验中,使用了以下模型
其中,EfficientNet(lite1)的效果最好,所以在没有提到的情况下,采用了EfficientNet(lite1)。
实验结果
与最先进的模型比较
在实验的第一部分,我们提出了与现有最先进的GAN模型的比较结果。这里,我们使用StyleGAN2-ADA和FastGAN作为基线进行比较。
FID(Fréchet Inception Distance)被用来作为评价指标。(在原论文的附录中,还报告了不同评价指标的结果,如KID、SwAV-FID、精度和召回率)。
收敛速度和采样效率
首先,我们比较了LSUN-Church和CLEVR数据集的收敛速度和采样效率。在这种情况下,收敛速度的比较结果如下
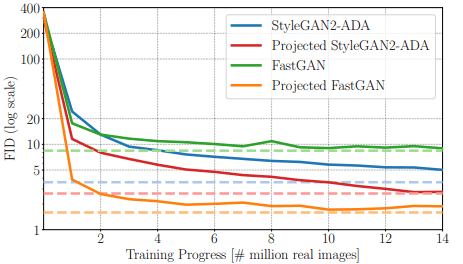
关于图表,Projected StyleGAN2-ADA和Projected FastGAN是使用相应架构作为生成器的Projected GANs。
如图所示,FastGAN收敛较早,但FID得分在高值时达到饱和;StyleGAN2-ADA收敛缓慢,但FID下降到低值。所提出的方法,即Projected GAN,在收敛速度和FID方面都有很好的改善,特别是在使用FastGAN架构时。
令人惊讶的是,在88M图像上训练的StyleGAN2-ADA的性能(图中的蓝色虚线)被Projected FastGAN在1.1M图像上实现,这清楚地表明了所提方法的有效性。
由于其高性能,从现在开始,作为FastGAN的生成器所采用的模型将被用作建议的方法,它被称为Projected GAN。接下来,样本效率的比较如下。
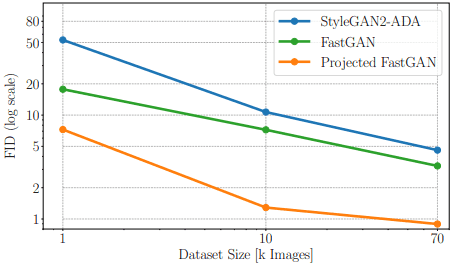
从图中可以看出,与现有方法相比,小数据集的性能也非常好。
在大型和小型数据集上的比较
接下来,不同大小和分辨率的数据集的比较结果显示如下。
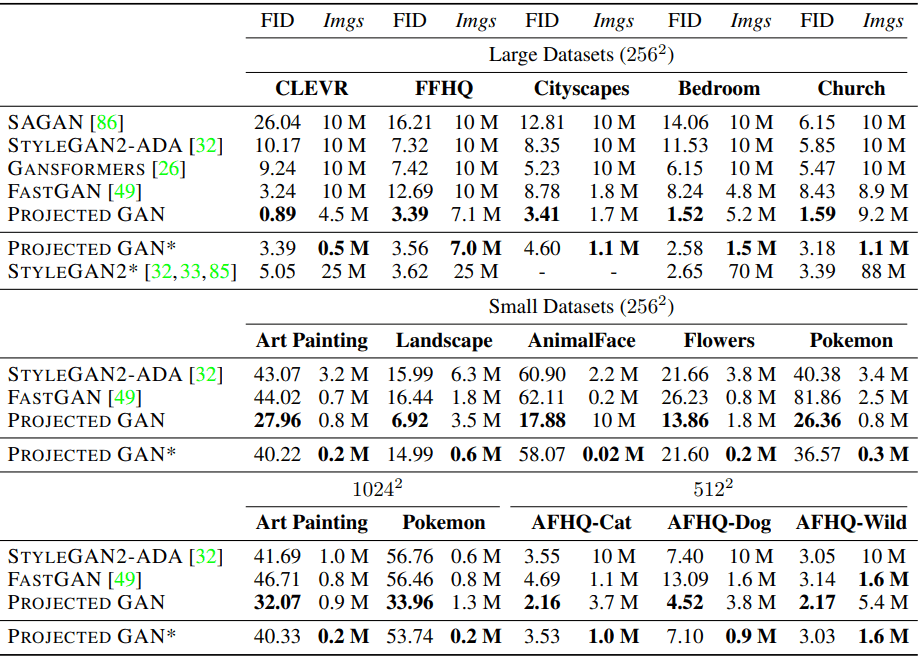
在表中,PROJECTED GAN*表示当提出的方法超过了现有模型的最佳性能时。
例如,CLEVR在对0.5M的图像进行训练时,表现出优于以往文献中最低的FID得分。
如表所示,在大/小数据集和分辨率(256^2,512^2,1024^2$)的所有情况下,建议的方法在FID得分和数据效率方面都明显优于现有方法。
尽管一贯使用在ImageNet上训练的EfficientNet作为预训练模型,但在各种数据集上都获得了良好的结果。这显示了ImageNet训练的模型特征的多功能性。
消融研究
在下文中,我们将进行消融研究。开始时,作为特征提取器的预训练模型的比较结果如下

从表中可以看出,ImageNet top-1的准确率与FID得分之间的相关性似乎不大,EfficientNet-lite1显示了最好的结果。在相对较小的模型上实现高性能的能力是降低整体计算成本的一个有用的特征。
鉴别器和特征投影器的消融结果也显示如下。
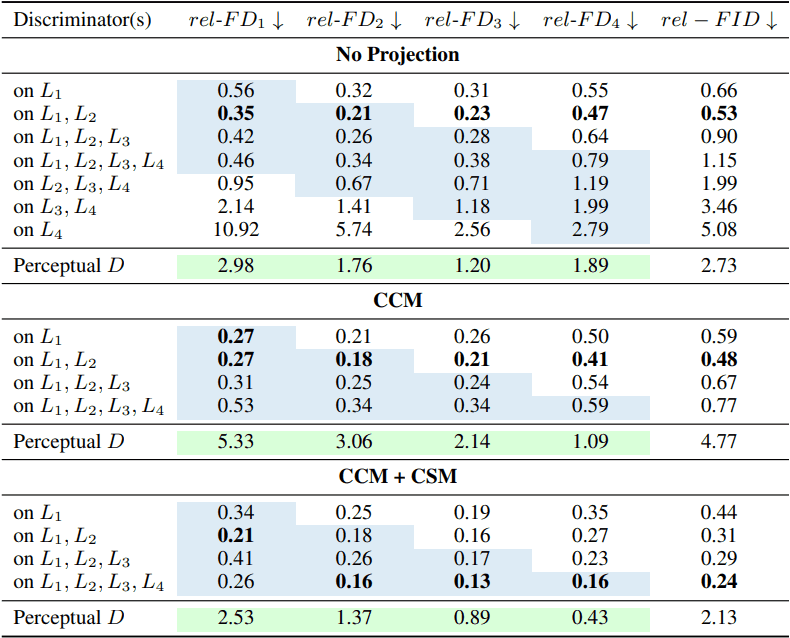
总的来说,事实表明,使用多尺度特征和使用由CCM和CSM组成的特征投影仪可以得到更好的结果。
摘要
现有的最先进的GAN模型,如StyleGAN2-ADA,存在着诸如训练的巨大计算成本等挑战。
本文提出的论文表明,通过使用预训练模型的特征,生成图像的质量、采样效率和收敛速度都明显优于现有的最先进的模型。
这一结果不仅提供了更好的图像生成,而且还允许没有大量计算资源的人创建和研究最先进的GAN模型。然而,所提出的方法可能会产生带有伪影或生成不良的非面部区域的图像,如下图所示。


尽管有这些挑战,高效和高质量的GAN模型的出现,如所提出的方法(尽管它可能会增加滥用的风险,如深度造假)是一个非常重要和有用的研究,将导致更多的人参与到这个领域的发展中来。
官方代码也是可用的,所以你可以把它和原始论文一起查看。



与本文相关的类别






