我想更容易地使用GAN。
三个要点
✔️ 从草图中创建生成模型
✔️ 与基线相比,实现了高准确率
✔️ 预计在未来会有改善
Sketch Your Own GAN
written by Sheng-Yu Wang, David Bau, Jun-Yan Zhu
(Submitted on 5 Aug 2021)
Comments: Accepted by ICCV 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本文所使用的图片要么来自该文件,要么是参照该文件制作的。
简介
GANs在技术上有所发展,现在能够产生高质量的图像。当然,也有一些局限性,但GANs正变得越来越有用。然而,由于存在一些局限性,出现了它是否能被普通公众使用的问题。使用这种有用的方法的主要障碍之一是,只有专家才能使用。例如,一个以猫为题材创作的用户如何能生成一个特殊姿势的猫咪图像,如猫咪躺下,或猫咪向左看?为了获得这种定制的生成,本文通过提出从手绘草图中创建生成模型的任务来迎接这一挑战。问题是,不是从草图中创建一个单一的图像,而是是否有可能从手绘草图中创建一个真实的图像生成模型。如下图所示,仅用四张手绘草图就可以改变一个物体的姿势或放大一只猫的脸。
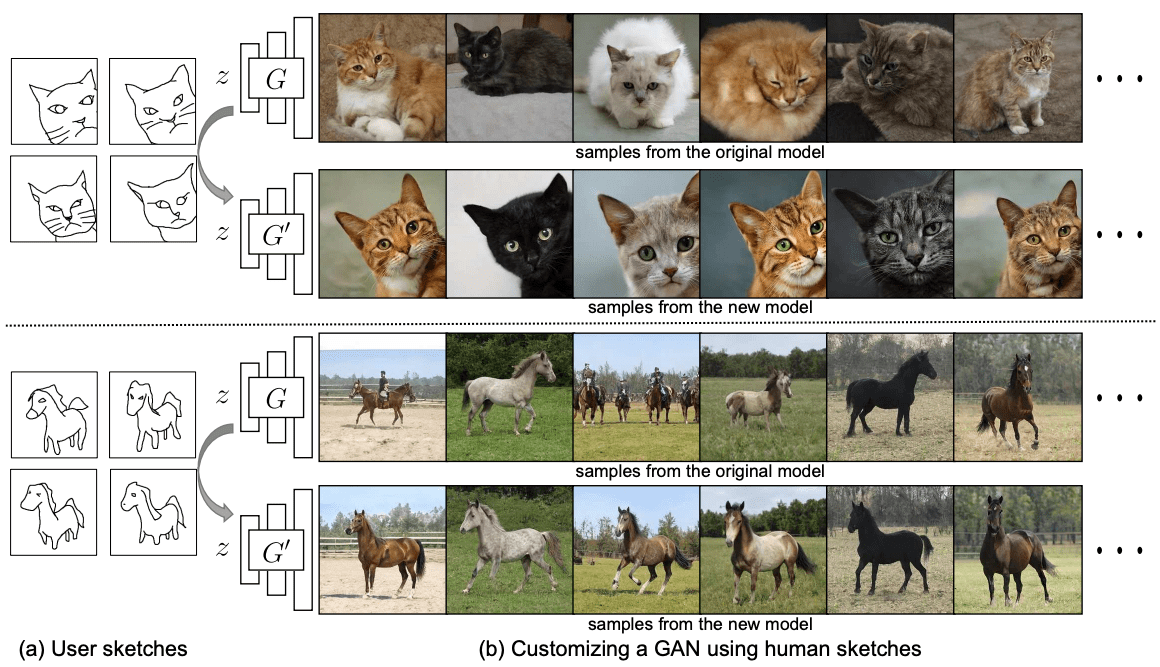
下面你将看到这项任务的概述图片。

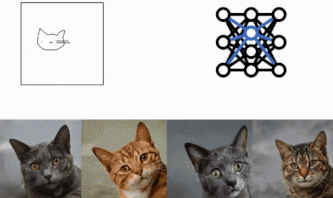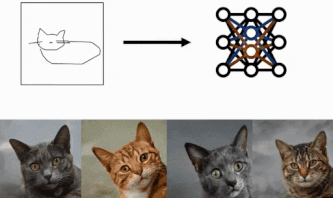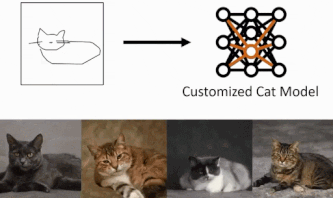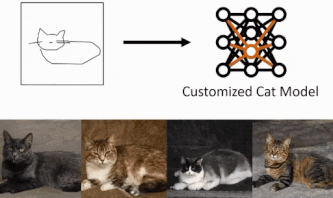
方法
我们将使用三个主要组件。
- 为了从草图中创建一个GAN模型,我们引入了一个跨领域的对抗性损失,和之前一样,使用领域转换网络,因为它是训练数据(=草图)和输出(=图像)之间的不匹配。然而,简单地使用这种损失会导致模型本身的行为发生相当大的变化,并导致不现实的结果,所以我们提出了一种改进的损失。跨域对抗性学习→跨域对抗性学习
- 为了保留原始数据集的内容及其多样性,该模型通过应用图像空间正则化进行训练。→ 图像空间正则化
- 为了减少模型的过拟合,更新被限制在特定的层,并进行数据增强。→ 优化
整个学习过程如下图所示。
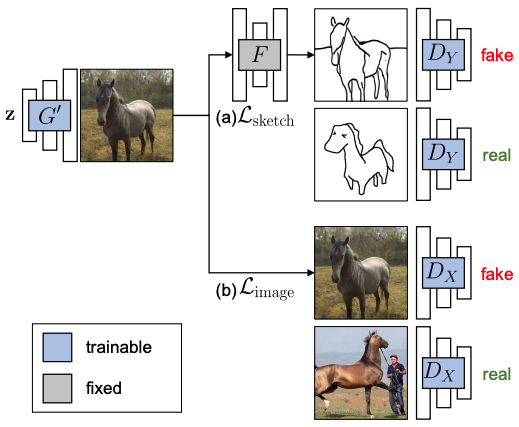
跨域对抗性学习
让X , Y分别是一个由图像和草图组成的域。我们收集一个大的训练图像x~$p_(data)$(x)和一些人类草图y~$p_(data)$(y)。让$G(z;θ)$是一个预训练的GAN,它从低维代码z中生成一个图像x。我们想创建一个新的GAN模型$G(z;θ')$,其中输出图像仍然遵循X的数据分布,而输出图像的草图版本则类似于Y的数据分布。这个网络可以使用输入-输出对进行训练,比如一张照片和它的草图,但我们将使用一个跨领域的图像-草图图像转换网络F : X → Y(F:Photosketch)。为了弥补草图训练数据和图像生成模型之间的差距,我们使用跨域对抗性损失来确保生成的图像与草图Y相匹配。在传递给鉴别器之前,生成器的输出被一个预先训练好的图像-草图网络F(见下文)转移到草图中。
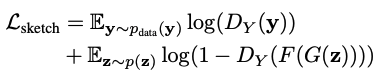
图像空间正则化
仅仅损失到草图,只会迫使生成的图像的形状与草图一致。这意味着图像质量和生成的多样性会大大降低。为了解决这个问题,我们增加了一个对抗性损失,将输出与原始模型的训练集进行比较。
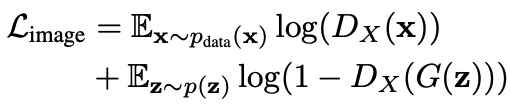
这里,判别器$D_(X)$被用来保持模型输出的质量和多样性,并使其适应用户的草图。
我们还试验了权重正则化,使用下式中的损失来明确地惩罚大的变化。我们发现,在实践中,这并没有提高准确性,反而造成了性能的下降。然而,结果表明,应用权重正则化或图像空间正则化对于实现图像质量和形状匹配之间的平衡非常重要。
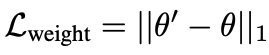
优化
为了防止模型的过度拟合和加快微调,StyleGAN2只改变映射网络的权重,并将z∼N(0,I)重新映射到不同的中间势空间(W-空间)。此外,他们使用预先训练好的Photosketch网络F,并通过训练固定F的权重。 他们在训练草图上实验了一种最小化的增强策略,并发现轻微的增强在场景测试中得到了更好的结果。 在这项研究中,使用了转化的增强。
最终的优化公式如下
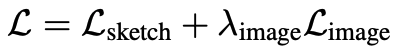 设置$λ_(image)$ = 0.7以控制图像空间正则化项的重要性。我们在以下最小化中训练一组新的权重$G(z; θ')$。
设置$λ_(image)$ = 0.7以控制图像空间正则化项的重要性。我们在以下最小化中训练一组新的权重$G(z; θ')$。
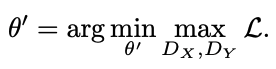
实验
数据集
为了能够进行大规模的定量评估,我们构建了一个模型草图的数据集,其正确答案的分布定义如下:使用PhotoSketch将LSUN马、猫和教堂的图像转换为草图,如下图所示,30个具有类似形状和姿势的草图被这套作品是手工挑选的,并作为用户的输入。为了确定目标分布,我们又手工挑选了2500张与输入草图相匹配的图像。只有指定的30张草图是可以访问的,而2500张真实图像的集合是从未真正见过的目标分布。
评价指标
该模型的评估依据是生成的图像和评估集之间的弗莱切入射距离(FID),它衡量了两组图像之间分布的相似性,并提供了生成图像的多样性和质量以及图像与草图的匹配程度的指示。FID衡量两组图像之间的分布的相似性。
基准线
与Radford等人提出的矢量算术方法类似,我们通过使用与用户草图相似的平均样本获得的常数矢量$Δw$来转移潜在的$w_(new)$ = w + $Δw$,评估定制模型输出的效果。($L_(草图)$+$L_(图像)$为全额(不含八月),$L_(草图)$+$L_(图像)$+aug.为全额(含八月))
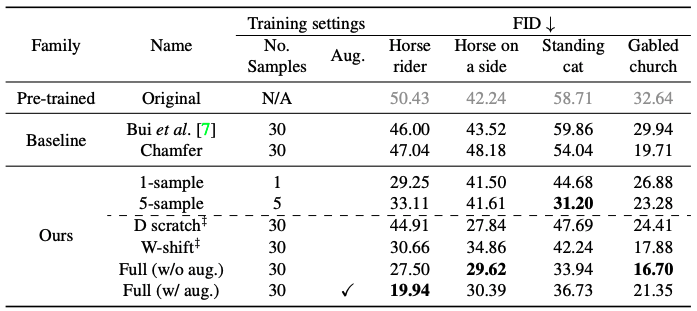
该表显示了定量的比较。可以看出,结果与上图所示的对比是一致的。可以看出,基线方法并不符合用户的草图。
消融研究
研究了正则化方法和数据增强的效果。结果显示在表中。
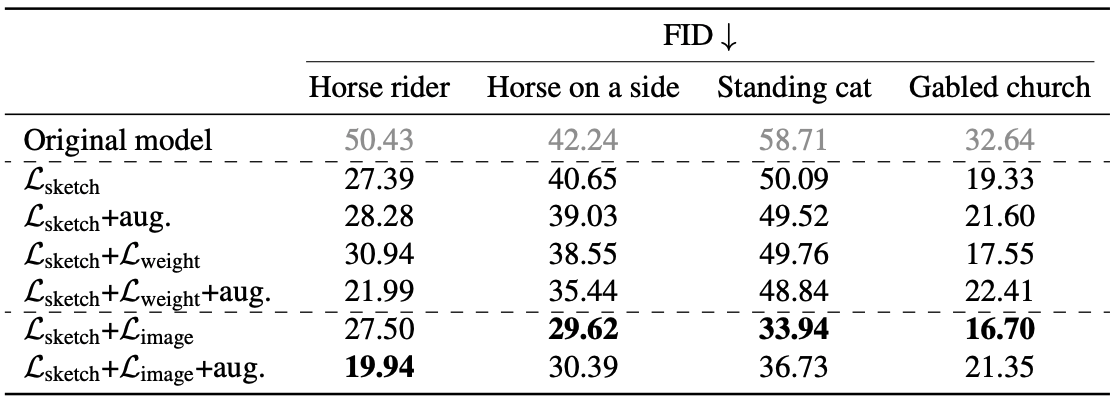
对于从Photosketch生成的草图,我们可以看到,扩增不一定能提高性能。在应用图像正则化时,骑马者的模型受益于增强,但在生成侧卧的马、站立的猫等模型时,没有增强的结果会更好。
正则化方法的比较
正则化方法$L_(image)$或$L_(weight)$比单独用$L_(sketch)$训练的模型提高了FID,但用图像正则化训练的模型比用$L_(weight)$训练的模型要好。这与上面的结果是一致的,在下图中显示了用和不用正则化训练的模型。

摘要
我们提出了一种方法,允许用户使用现成的训练模型和跨领域训练来创建定制的生成模型。使用单一的手写草图作为输入,我们的方法甚至允许新手用户为该草图创建一个生成模型。
然而,该方法并不对所有的草图都有效。例如,在对毕加索的马的素描进行测试时,它失败了。毕加索的草图并不完美,因为它们是以一种特殊的风格绘制的,这可能是失败的原因。此外,虽然我们对形状和姿势有灵活的控制,但我们还不能定制其他特征,如颜色和纹理。然而,我们确信,这一领域将在未来得到改善。



与本文相关的类别





