理发店生成多张面孔的合成图像!
三个要点
✔️ 通过组合两个人脸图像来生成图像的任务
✔️ 新提出的FS空间,而不是CycleGAN2中使用的W空间等。
✔️ 生成的图像在所有指标上都优于现有方法。
Barbershop: GAN-based Image Compositing using Segmentation Masks
written by Peihao Zhu, Rameen Abdal, John Femiani, Peter Wonka
(Submitted on 2 Jun 2021)
Comments: Accepted by arXiv
Subjects: Computer Vision and Pattern Recognition (cs.CV); Graphics (cs.GR)
code:

首先
使用生成对抗网络(GAN)进行图像编辑,最近已被广泛用于专业应用和普通用户的社交媒体照片编辑工具。特别是,用于编辑人脸图片的工具引起了人们的广泛关注。在本文中,我们提出了一个新的图像编辑工具,通过生成一个结合多个图像元素的复合图像。
最近,通过操纵潜伏空间进行人脸编辑已经被成功应用,但这些图像是通过改变全局属性,如姿势、表情、性别和年龄来操纵的。由于一些原因,我们在本文中希望执行的综合任务具有挑战性。首先,每个部分的视觉属性并不是相互独立的。就头发而言,它受到环境光和来自面部、衣服和背景的透射光的影响。此外,面部和肩部也会影响头发和阴影。由于这些原因,如果不考虑图像的整体一致性,就会出现假象,即图像的不同区域会显得不连贯,即使每个部分都是高质量的。因此,在本文中,我们提出了一个新的$FS$潜在空间,允许通过结构张量$F$对特征进行粗略的空间位置控制,并通过外观代码$S$对全局风格属性进行精细控制。

本文提出的方法如图1所示。它只能将目标图像中的头发形状转移到原始图像(b)。它还能够转移直发和卷发之间的差异(d~g)。
技术

拟议方法的流程如图3所示。一般流程如下。
- 参考图像的分割是生成的或手动生成的
- 潜伏代码$C^{align}_k=(F^{align}_k,S^{align}_k)$从每个分割的图像$Z_k$中被检测出来。
- 对于每个$k$,复制$F^{align}_k$的区域$k$,形成联合结构的张量$F^{blend}$
- $S^{align}_k$的权重被推导出来,从而使外观代码$S^{blend}$被对齐为一个图像
初步细分
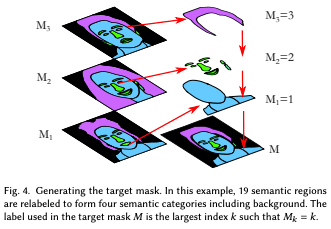
第一步是对参考图像进行分割。这将选择应该被复制到目标图像的区域。让$M_k=SEGMENT(Z_k)$表示参考图像$Z_k$的分割,$SEGMENT()$是一个分割网络,如BiSeNET。这一步的目标是形成一个与目标分割遮罩$M$相匹配的复合图像$Z^{blend}$,以便在$M=k$的位置将$Z^{blend}$的视觉特性从原始参考图像$Z_k$转移过来。这里,每个像素的目标掩码$M(x,y)$被设置为满足$M_k(x,y)=k$条件的$k$值。如果多个$k$满足条件,则选择较大的$k$。例如,头发的某些部分被皮肤自然覆盖。在这种情况下,皮肤和头发的标签都被应用,但由于头发标签的$k$较大,所以头发标签被应用而不是皮肤标签。
嵌入
在合成图像之前,我们必须首先将每个图像与目标掩码$M$对齐。这是一个重要的步骤,因为正如在 "介绍 "中提到的,眼睛和鼻子等部分并不是相互独立的,而是取决于整个头部的姿势。它由 "重建 "和 "对齐 "两部分组成,前者是为了找到潜伏代码$C^{rec}_k$来重建输入图像$Z_k$以对齐参考图像,后者是为了找到潜伏代码$C^{align}_k$以最小化生成图像和目标掩码之间的交叉熵。对齐 "来寻找使生成的图像和目标掩码之间的交叉熵最小的潜伏代码$C^{alignment}_k$。
重建重建
给出$Z_k$作为输入图像,我们找到$C^{rec}_k$,使$G(C^{rec}_k)$能够重建$Z_k$($G()$是一个发生器)。作为一种方法,在本文中我们使用II2S来推导$W^{rec}_k$,使用StyleGAN2的W+空间来初始化它。然而,W+空间不足以捕捉面部细节,如皱纹和痣;一种方法是噪声嵌入,它在重建方面几乎是完美的,但会导致过度拟合,在图像编辑和合成中出现伪影。图5显示了W+和FS空间之间的比较。

图5显示,在FS空间中捕捉到了更详细的信息。我们将发生器的样式块的输出作为空间相关的结构张量$F$来替换W+空间中的相应块。为了简单起见,我们在这里使用样式块8。我们将$F^{init}_k=G_8(w^{rec}_k)$作为初始结构张量,并用10个$w^{rec}_k$的块来初始化外观码$S^{init}_k$。然后我们推导出$C^{rec}_k$。
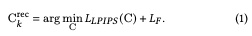
在这里。

统一性
每个输入图像$Z_k$由$C^{rec}_k$编码,它由一个张量$F^{rec}_k$和一个外观码$S^{rec}_k$组成。尽管$C^{rec}_k$捕捉了图像的外观,但它与更详细的部分,即目标分割并不一致。因此,我们推导出一个与目标分割相匹配并存在于$C^{align}_k$附近的潜伏代码$C^{rec}_k$,它显示了外观。 然而,直接优化$C^{align}_k$是困难的,因为$F^{rec}_k$在空间上是相关的。因此,我们首先将$F^{rec}_k$的细节转移到$F^{align}_k$。
使用屏蔽式风格损失来保留对齐的图像$G(w^{alignment})$和原始图像$Z_k$之间的风格。
克级矩阵
![]()
其中$gamma$是由VGG网络第l层的激活得到的矩阵。然后我们定义面具。
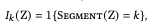
这里,$1\{\}$是一个指标函数,所以$I_k$是语义范畴$k$的一个指标。
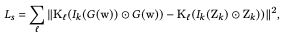
然后,风格损失由潜伏代码$w$生成的图像的克矩阵与目标图像$Z_k$之间的差异大小表示,并且只在每个图像的语义域$k$内进行评估。
$I_k(Z_k)\bigodot Z_k$是通过将语义区域$k$以外的像素设置为0来进行遮蔽的公式。循环损失如下。
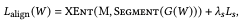
其中$XEnt()$是一个多类交叉熵函数。
将结构和外观从图像$Z_k$转移到$F_k$的下一个方程式是
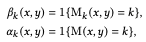
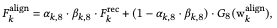
如果目标图像和参考图像的语义类别相同,它就复制$F^{rec}_k$。如果目标图像和参考图像的语义类别相同,则按原样复制$F^{rec}_k$,否则(结合其他图像的区域),使用$w^{align}_k$来生成区域。
结构混合
我们结合粗略的结构来组合图像。如以下公式所示,可以通过简单地组合每个结构张量来组合粗略的结构,但在外观代码方面需要更加谨慎。
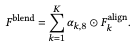
外观混合
本节的目标是推导出组合图像的外观代码$S^{blend}$。为此,我们介绍了以前研究中使用的LPIPS距离函数。
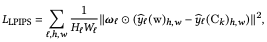
$hat{y}_l$是convnet(VGG)的$l$层的激活,$W_l,H_l$是指通道维度的归一化张量,$omega$是每个通道的权重。在被掩盖的情况下,我们有以下情况。
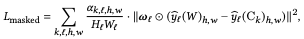
通过学习得出满足下式的$S^{blend}$,就可以得到正的权重$u_k$(所有$u_k$加起来为1)。
实验
实验设置
- 模型
- 米其根(MichiGAN)
- 骆家辉
- 我们的。
- 数据集
- https://arxiv.org/abs/2012.09036
- 一套120张高分辨率的图片
实验结果
用户研究
我们使用亚马逊的Mechanical Turk进行了用户评估(396名用户)。我们向他们展示了拟议方法和现有方法的两幅图像,并问他们哪种方法的图像质量更高、伪影更少。95%的人回答说拟议方法对LOHO更好,96%的人回答说拟议方法对MichiGAN更好。
重建重建质量
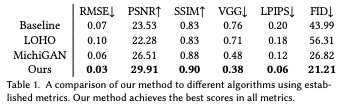
我们通过各种指数评估了图像的质量,所提出的方法在所有指数中都是最好的。
生成的图像
我们在提议的方法中提出了各种组合图像。
我们不仅成功地结合了头发(图6),而且还转移了眼睛和眉毛等面部特征(图7)。


寿命限制
所提出的方法不能修复几何变形,如图10中所示的脸上的薄发丝。这些问题可能需要较少的规范化,并将成为未来研究的主题。

摘要
在本文中,我们提出Barbershop是一个新的基于GAN的图像编辑框架。它允许用户通过操作分割掩码和复制不同图像的内容来处理图像。所提方法的主要特点是,首先,我们提出了一个新的潜势空间,结合了结构张量,而不仅仅是常用的W+空间。结构张量使我们能更多地从空间上识别潜伏的代码,并更好地捕捉到人脸的细节。其次,对齐嵌入允许我们嵌入与输入图像相似的图像,并修改图像以适应新的分割掩码。最后,我们能够将在新的潜伏空间中编码的多个图像结合起来,产生一个高质量的图像。



与本文相关的类别






