什么时候,为什么,以及哪些预训练的GANs是有用的?
三个要点
✔️ 调查预训练的GANs的成功率
✔️ 解释生成器和判别器在预训练的GAN中的作用
✔️ 建议的最佳源数据集选择政策
When, Why, and Which Pretrained GANs Are Useful?
written by Timofey Grigoryev, Andrey Voynov, Artem Babenko
(Submitted on 17 Feb 2022 (v1), last revised 10 Mar 2022 (this version, v2))
Comments: ICLR 2022
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片来自于论文,来自于介绍性的幻灯片,或者是在参考了这些图片后制作的。
介绍
最近的研究表明,在不同的数据集上对预先训练好的GAN进行微调(尤其是在数据数量较少的情况下),比从头开始训练的结果更好。
那么,什么时候、为什么以及哪些预训练的GANs表现更好呢?
本文分析了上述问题的各个方面,如使用预学习GAN如何影响生成的图像,生成器和鉴别器的初始化起什么作用,以及为所需任务选择哪种预学习GAN。将提出研究报告。
GAN微调的分析
首先,我们分析了为什么GAN微调与从头开始学习相比显示出更高的效果。
直观预测了GAN微调成功的原因
首先,考虑用新数据对预先训练好的生成器和鉴别器$G,D$的分布$p_{target}$进行微调的情况。
本文预测预先学习的$G,D$分别扮演以下角色,并通过实验证明这一预测将是正确的。
- 发电机的初始化负责(负责)市场数据的模式覆盖。
- 鉴别器的初始化是负责初始梯度场的。
如果基于这种期望,通过使用预训练的$G,D$成功的原因可以表达如下。
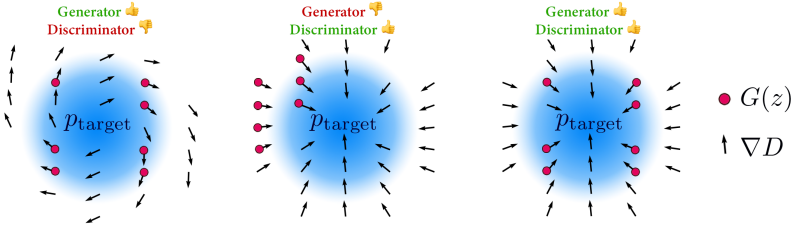
图的左边显示了当使用适当的生成器和不适当的鉴别器时发生的情况的图像。
在这种情况下,生成器产生了一个多样化的初始样本,但由于鉴别器给出的梯度并不理想,所以学习效果并不理想。在图的中间,显示了具有不适当的发生器和适当的鉴别器的情况的图像。
在这种情况下,判别器给出的梯度很好,但生成器生成的初始样本分布不充分,这将使最终生成的模式范围出现偏差。而如图右侧所示,如果生成器和鉴别器都足够用,就可以认为新的任务可以适当转移到新的任务。
在接下来的章节中,我们将用合成数据进行实验,以检查这一预测是否有效。
用合成数据进行的实验
在实验中,考虑下图中呈现的综合数据。

图中左起第一条显示了两个源数据(Source-I, Source-II)和目标数据(Target)。
第二张和第三张图分别显示了在Source-I和Source-II上生成预训练发电机的例子。
这两个预训练的生成器和用目标数据从头开始训练生成器的结果分别显示在图4、5和6中(图中的数字是目标分布和生成的数据Wasserstein-1)。
如图所示,与从头开始的情况相比,使用合适的预训练生成器生成不同的数据,已被证明能产生更好的结果。(相反,使用偏向于生成的例子的生成器也被发现导致了比从头开始的情况更糟糕的结果)。
它进一步研究了预训练的生成器和判别器的选择如何影响微调后的结果。
这里,预训练的生成器的质量由召回率来衡量,预训练的判别器的质量由地面真相梯度和判别器梯度的相似度来衡量。
然后对不同的预训练的生成器和鉴别器对的目标数据(与前面实验中的设置相同)进行微调,并测量目标数据分布和生成器分布之间的Wasserstein-1距离。这个程序使我们能够研究预训练的生成器和判别器的质量与它们的最终性能之间的关系。结果包括。
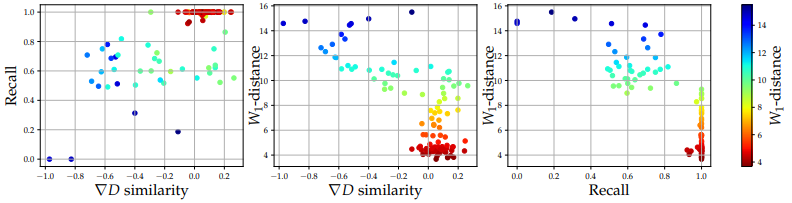
在图的左边,画出了所选生成器和判别器的召回率和∇D相似度。
图的中间和右边分别显示了判别器(∇D相似度)和生成器(召回率)的质量与生成结果(W1-距离)的质量之间的关系。
从结果中可以看出,生成器和鉴别器的质量与微调后的生成质量有显著的负相关(Pearson相关系数为:Recall为-0.84,∇D相似度为-0.73)。
实验表明,预训练的生成器和判别器的召回率和∇D相似度与微调后的GAN的质量相关联。然而,应该注意的是,这并不证明有因果关系。
实验装置
StyleGAN2的预研究
该实验将研究StyleGAN2架构。
数据集
用于预训练和目标定位的数据集如下
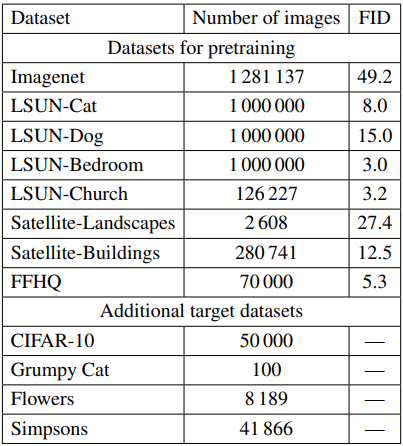
预训练是在预训练数据集下的表格中包括的八个数据集上进行的,而微调是在额外的目标数据集上进行的。图像分辨率为256x256,模型使用官方的PyTorch实现StyleGAN2-ADA。表中的FID表示预训练模型在每个数据集上的FID得分,越小越好。
研究前的设置
对于预训练的模型,我们首先在ImageNet中创建了一个在5000万张图像上训练的模型,然后在其余每个数据集的2500万张图像上进行训练,形成七个检查点。
在目标数据集上进行训练设置
对于目标数据集的训练,使用StyleGAN2-ADA实施的默认转移训练设置,每个数据集有25M的图像。
评价指标
用来评估模型性能的指标是
实验结果
实验结果如下,其中F、P、R和C分别代表FID、精度、召回率和收敛率。
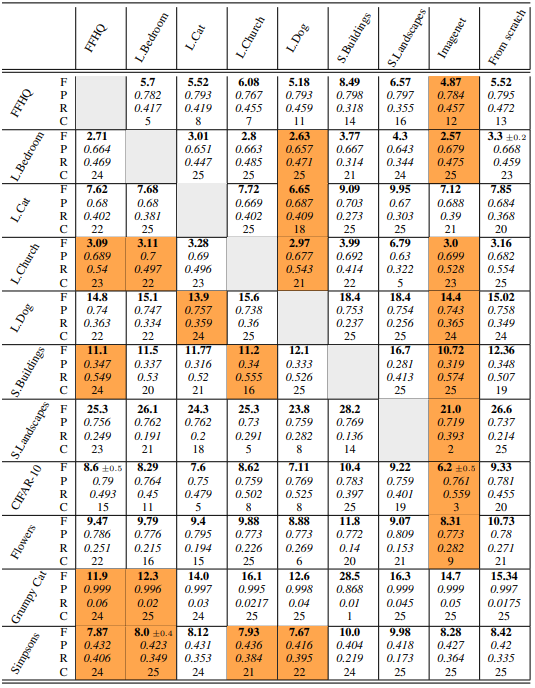
该表显示如下。
- 对于FID,在不同的源数据(ImageNet、LSUN Dog)上预训练的检查点在所有数据集上的表现都优于从头训练(From scratch)。
- 与从头开始学习相比,预学习大大加快了优化的速度。
- 源检查点的选择对微调模型的召回值有很大影响。例如,如果目标是百花数据集,就会出现10%以上的变化。
每个目标的召回率和精确度的标准偏差显示如下,表明召回率的变化仍然很大。
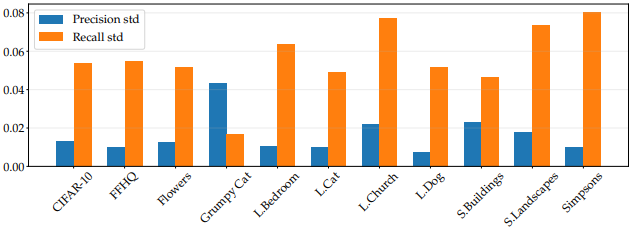
总的来说,尽管模型的FID得分很低(49.2),但在ImageNet上预训练的模型被认为是微调的良好检查点。
这个结果与以前的研究相反,但这可能是由于使用的模型不同(WGAN-GP)。
用额外的实验进行分析。
・预训练以提高真实数据的模式覆盖率
本文的期望是,发电机的初始化与市场数据的模式覆盖有关。这里的其他实验研究了预训练模型的选择对生成图像的模式有多大影响。
具体来说,对于在由102个类别组成的Flowers数据集上微调的模型所产生的图像,分类器会检查每个类别中存在多少图像。结果如下。
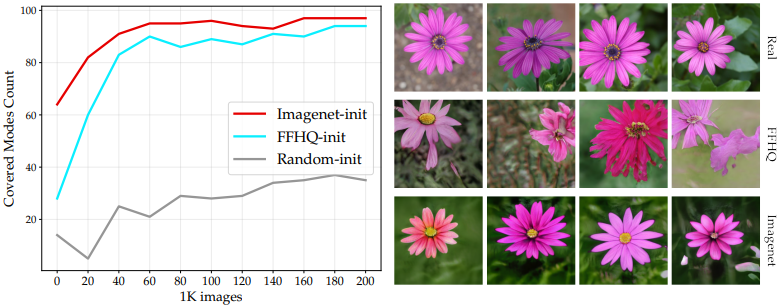
在该图中,对于每个检查点(ImageNet、FFHQ和Random),产生了10,000张图像,并绘制了包含10个或更多样本的类的数量(横轴是模型中的训练图像总数)。
如图所示,在ImageNet上用不同的源数据预训练的模型涵盖了更多的模式。
・如何选择适当的预习检查点
最后,提出了一个简短的政策,即对于一个特定的目标数据集,应该选择哪些预训练的检查点。
具体来说,它考虑通过测量源数据集和目标数据集的分布的相似性来选择最佳模型。这里,FID、KID、精确度和召回率是针对两种不同的情况进行测量的:(1)仅仅使用源数据集和目标数据集中的图像,以及(2)使用预训练模型的生成实例和目标数据集中的图像。
确定是否可以通过每个指标的数值来确定最佳来源数据集的结果如下。
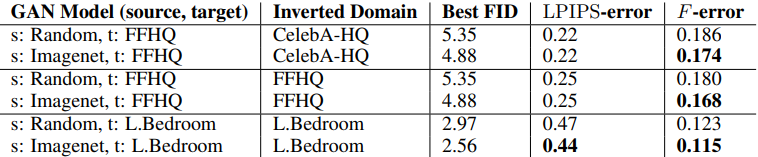
该表显示了无法预测最佳检查点的数据集的数量,数字越小说明指标越好。
总的来说,我们发现,使用除精确率以外的指标(尤其是召回率),有可能在(1)和(2)两种设置中大致确定最佳的源数据集。
摘要
这篇文章介绍了一篇调查预训练的GAN模型的成功的论文。
该论文提出了各种发现,包括使用适当的预训练的GANs可以提高对生成图像的模式的覆盖率,并且为了获得最佳性能,应该同时使用预训练的生成器和判别器。研究还发现,源数据集和目标数据集之间的召回值可以指导选择一个合适的源数据集。



与本文相关的类别






