从关注到基于GAN的方法的图像标题生成技术的总结。
三个要点
✔️ 关于图像标题生成的调查文件
✔️ 介绍技术、数据集、基准和衡量标准
✔️ 基于GAN的模型取得了最高分。
A Thorough Review on Recent Deep Learning Methodologies for Image Captioning
written by Ahmed Elhagry, Karima Kadaoui
(Submitted on 28 Jul 2021)
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
图片说明包括如图像的自动索引。各种用途。人工注释的成本很高。因此,对自动生成字幕的技术的需求越来越大。在这一领域已经做了很多研究,并发表了调查论文,但都没有涵盖近年来的一些关键模式。我们提出这篇论文,以强调最近发表的一些最相关的论文,比较其模型的性能,并解释其工作原理。今天,注意力的使用是图像说明中最重要的技术之一:自从引入Transformer后,许多任务,如机器翻译和语言建模,都由于Transformer而取得了显著的性能提升。这同样适用于图像标题的生成,它被用于各种模型中,正如本文所介绍的。另一项引起研究人员关注的技术是深度强化学习。它已被证明特别适用于不寻常的图像,如 "森林中的床"。
技术
更新
今天,大多数使用视觉注意力的常用技术是自上而下的(从宏观到微观)。在这些模型中,每个时间步骤都会给出一个部分完成的标题以获得背景。然而,在关注图像的哪些区域方面存在问题。通过确保将重点放在突出的、容易识别的物体上,就有可能生成人类创造的标题。
鉴于这些问题,我们在此提出了一个名为 "向上-向下 "的模型,它将视觉上的自下而上的方法与特定任务的上下文方法结合起来。前者提供关于突出物体区域的建议,而后者则利用背景来计算对它们的注意力分布。因此,它可以将注意力引向输入图像中的重要对象。
本节介绍Up-down的实现。自下而上的部分使用Faster R-CNN物体检测模型,该模型由边界框包围,用Resnet-101初始化并在视觉基因组数据集上进行预训练。自上而下的部分使用视觉注意力LSTM和语言注意力LSTM。注意力LSTM得到前一个语言LSTM的输出,在时间t-1产生的词和平均汇集的图像特征,并决定哪个重点关注的区域。然后,它使用截至该点所产生的字幕计算输出词的条件分布,产生一个关于字幕的分布。
奥斯卡
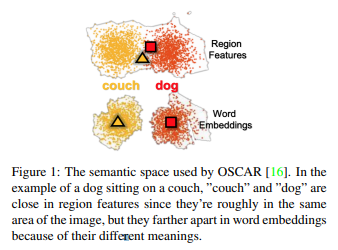
视觉-语言预训练(VLP)被广泛用于学习跨模式(图像-语言)表征。然而,VLP有两个问题:由于每个图像中的重叠区域而导致的识别困难,以及单词和其相应的图像区域之间的错位。这里提出了OSCAR,通过使用对象标签作为 "锚点 "来解决这些问题。它使用三个输入:图像区域的特征、对象标签和单词序列(字幕)。这样,如果一个人的信息不完整或有噪音,就可以由其他人来补充。
介绍了OSCAR的实现,其中OSCAR使用Faster R-CNN来检测物体标签,并获得两个
- 语言学语义空间包括标签和标题标记,视觉语义空间包括图像区域(图1)。
- 图像模式包括图像特征和标签,语言模式包括标题标记。
薇薇安
由于nocaps挑战只允许MS COCO作为生成图像标题的数据集,因此VLP方法并不适用。因此,这里设计了VIVO(VIsual VOcabulary pre-training)。这是一个标签和图像区域的联合嵌入空间,并定义了一个 "视觉词汇表",其中语义相近的对象(如手风琴和乐器)的向量位于相近位置(图2)。
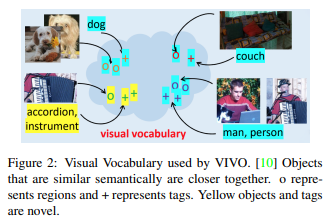
在对词汇进行预训练后,该模型使用MS COCO数据集对图像-标题对进行微调;VIVO和其他VLP模型的一个区别是,VIVO对图像-标签对进行预训练,在微调完成之前不使用标题数据集。VIVO在微调之前不使用标题数据集。标签比标题更有可能自动生成,从而减少注释的成本。此外,它们非常有用,因为有大量的标签可以使用。
本节介绍VIVO的实现。一个多层变换器将标签和它们相应的图像区域对齐。然后使用线性层和softmax。在预训练中,一个向上向下的物体检测模型被用来从输入图像中提取图像区域,这些区域与一组图像-标签对一起被输入到转化器中。该模型对其他被掩盖的标签和图像区域进行预测。正如前面介绍的那样,微调需要三个输入--图像区域、标签和标题--并了解到一些标题标记被掩盖,该模型对它们进行预测。
元学习
强化学习的缺点之一是奖励函数的过度拟合,代理找到了使其分数最大化的方法,而没有产生更高质量的字幕。例如,在使用CIDEr优化时,太短的标题会受到惩罚。因此,当短的标题生成时,多余的短语被添加以使其变长,导致不自然的句子结尾,如 "一个小女孩抱着一只猫在一个"。在这里,引入了元学习,它可以优化和适应几个不同的任务。通过这种方法,该模型同时执行奖励函数的优化(强化学习的任务)和监督学习的两个方向。这导致了类似人类的句子的标题。
本节介绍了Meta Learning的实现。它采用了上面所开辟的向上向下的架构。这次模型优化的任务是强化学习任务和监督学习的最大似然估计任务。该模型采取两个梯度,并更新参数θ。θ由一个称为 "元更新 "的自我更新方法更新。通过这种方式,可以学习参数θ来优化两个任务。
基于GAN的条件性模型。
相对于Meta Learning中存在的过度拟合奖励函数的问题,该方法使用一个判别器来确定产生的标题是由人类还是机器(模型)产生的。原来的论文没有给这个方法起名字,所以我们称之为IC-GAN(Image Captioning GAN)。
介绍了实施情况。我们实验了两种类型的判别器架构:一种是带有全耦合层和sigmoid函数的CNN,另一种是带有全耦合层和softmax函数的RNN(LSTM)。我们还分别用四个CNN和RNN的合集进行实验。在我们的方法中,我们把直到字幕生成的过程看作是一个生成器。有几个架构的发生器已经进行了实验,但我们重点关注使用Up-down架构获得的结果。在所有情况下,生成器和判别器都需要在微调前进行预训练。
估值指数
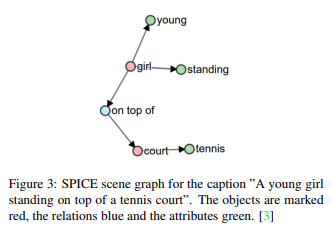
一些评价指标被用来比较生成的字幕和教师数据。常用的有CIDEr、SPICE、BLEU和METEOR。CIDEr是一个图像分类指标,使用TF-IDF衡量与人类的一致程度;SPICE是一个基于图形的场景图的语义表示(图3),它是基于一个新颖的语义概念的字幕。这是一个基于新语义概念的字幕评价指数。
基准
nocaps使用微软的COCO Caption数据集,但也使用OpenImages对象检测数据集,以引入前者中未见的新对象。15100张图片和166100个标题;OSCAR和VIVO已经在nocaps验证集上进行了评估。Karpathy拆分被用来评估Meta Learning和IC-GAN。最后,在这两个基准上对Up-down进行了评估。
结果。
MS COCO Karpathy拆分基准
该方法和相应的评价指标见表1。
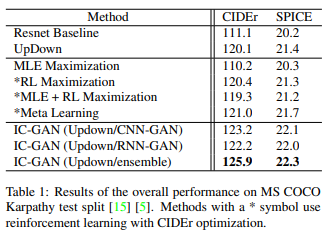
作为UpDown方法的比较基线模型,在Resnet上的实验表明,UpDown在CIDEr和SPICE上都提高了性能。结果显示,增加自下而上的注意力对图像标题生成任务有积极影响。通过最大似然估计、强化学习和简单地将MLE和强化学习的梯度相加的情况来比较带有元学习的模型,两个指标的指数都是最高的。与没有元学习的UpDown方法相比,它的表现也略好。另一方面,对于所有三个模型,IC-GAN的表现明显优于其他方法。请注意,CNN-GAN的得分比RNN-GAN好,但RNN-GAN需要的训练时间更少。IC-Gan还避免了传统强化学习方法中出现的单词重叠和逻辑断裂,如 "一群人站在时钟上面",并产生了更像人类的标题。
nocaps 基准
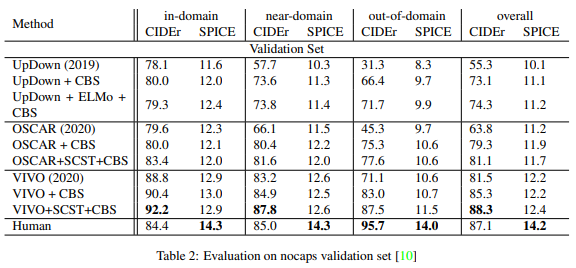
与UpDown方法相比,OSCAR在域内、近域和域外的所有子集上都有优越的表现。此外,加入受限波束搜索(CBS)和自我关键顺序训练(SCST)后,性能得到了极大的提高。这在域外特别明显。然而,是VIVO的表现比OSCAR好:VIVO+SCST+CBS在域内和近域的表现优于人类字幕,CIDEr的得分更高。
摘要
目前在图像标题生成方面的研究主要集中在深度学习方面。这是因为这项任务结合了计算机视觉和自然语言处理,非常复杂,所以需要能够处理这种复杂程度的'动力'技术。本文介绍的注意力,也在与深度强化学习和对抗性学习一起被积极研究,而Faster R-CNN是与LSTM一起的流行架构,特别是UpDown模型在最近的论文中被用作基础技术。
本文介绍了最先进的方法和它们的实现。在提出的UpDown、OSCAR、VIVO、Meta Learning和基于GAN的方法中,基于GAN的方法表现最好,UpDown影响最大,OSCAR和VIVO被认为更有用。
参考文本奉献精神
*只有关于本文所述技术的论文。
[1] P. Anderson, X. He, C. Buehler, D. Teney, M. Johnson,S. Gould, and L. Zhang. Bottom-up and top-down attention for image captioning and VQA. CoRR, abs/1707.07998,2017.
[2]X. Li, X. Yin, C. Li, P. Zhang, X. Hu, L. Zhang, L. Wang, H. Hu, L. Dong, F. Wei, et al. Oscar: Object-semanticsaligned pre-training for vision-language tasks. In EuropeanConference on Computer Vision, pages 121–137. Springer,2020.
[3]H. Agrawal, K. Desai, Y. Wang, X. Chen, R. Jain, M.Johnson, D. Batra, D. Parikh, S. Lee, and P. Anderson. nocaps: novel object captioning at scale. CoRR, abs/1812.08658,2018.
[4]X. Hu, X. Yin, K. Lin, L. Wang, L. Zhang, J. Gao, and Z. Liu.Vivo: Visual vocabulary pre-training for novel object captioning, 2021.
[5]N. Li, Z. Chen, and S. Liu. Meta learning for image captioning. Proceedings of the AAAI Conference on ArtificialIntelligence, 33:8626–8633, 2019.
[6]C. Chen, S. Mu, W. Xiao, Z. Ye, L. Wu, and Q. Ju. Improving image captioning with conditional generative adversarialnets. Proceedings of the AAAI Conference on Artificial Intelligence, 33:8142–8150, 2019.



与本文相关的类别


