
DualNet,一个用于两个子网络协调的新框架。
三个要点
✔️ 提出了一个DualNet,将两个平行的DCNN联系起来,学习相互补充的特征
✔️ 还提出了一个由迭代学习和联合微调组成的相应学习策略,以确保两个子网络的良好合作。
✔️ 基于CaffeNet、VGGNet、NIN和ResNet的DualNet在CIFAR-100、Stanford Dogs和UEC FOOD-100上进行了实验评估,都取得了比基线更高的准确度。
DualNet: Learn Complementary Features for Image Recognition
written by Saihui Hou, Xu Liu, Zilei Wang
Published in: 2017 IEEE International Conference on Computer Vision (ICCV)
code:


本文所使用的图片来自于论文,来自于介绍性的幻灯片,或者是在 参考了这些图片后制作的
介绍
近年来,人们对深度卷积神经网络(DCNN)进行了大量研究,它极大地提高了各种视觉任务的性能。
据认为,DCNN的成功主要与网络结构的深度和允许学习输入的分层表示的端到端学习方法有关。
因此,网络通常被设计得更深或更宽,以使DCNN的性能更好。
本文提出了一个框架,即DualNet,以便在图像识别中有效地学习更准确的表征,如图1所示。
DualNet将两个平行的DCNN联系起来,学习相互补充的特征,以便从图像中提取更丰富的特征。其目的是为了从图像中提取更丰富的特征。
具体来说,通过对齐Extractor构建了一个双宽网络,Extractor是一个端到端的DCNN,由Extractor(特征提取器)和Classfier(图像分类器)两个逻辑部分组成,它被用作DualNet的提取器。
这样做,可以为输入图像提取两个特征流,然后将其汇总形成一个统一的表示,并传递给融合分类器进行整体分类。
另一方面,在每个子网络的提取器后面增加了两个辅助分类器,以允许单独训练的特征被独立识别,并对这三个分类器进行加权,以施加互补的约束 。这正是双网的关键点。
本文还提出了一个新的框架 "DualNet",以及相应的学习策略,包括迭代学习和联合微调,以确保两个子网络的良好合作。
这种方法是实用的,没有太多的内存成本,与简单地将层宽翻倍的方法相比,可以在图像识别方面有显著的改进。
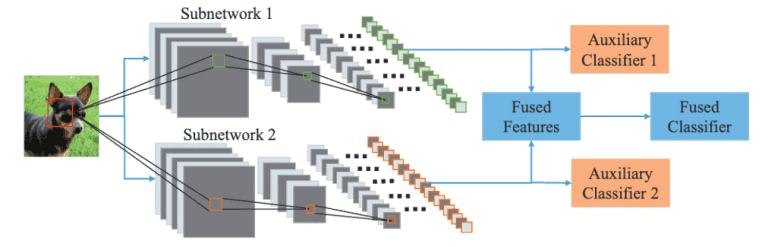 图1:DualNet概述图。
图1:DualNet概述图。
建议的方法
正如上一节所解释的,DualNet可以通过连接两个网络并从输入图像中学习互补的特征来描述。
通过在一个网络中学习另一个网络中所缺少的感兴趣的物体的细节,可以在融合后提取更丰富、更准确的图像表示用于识别。
特别是,在设计DualNet的过程中,遵循了以下原则。
- 与每个子网络中提取的特征相比,融合后的特征是最具辨别力的。
- 必须是一个通用的框架,能够与典型的DCNN(如VGGNet和ResNet)以及常见的数据集(如CIFAR-100)很好地配合。
- 该网络应在不减少小批量计算成本的情况下,尽可能提高训练和测试的效率,并与Tesla K40 GPU兼容(12GB内存限制)。
- 为了保证泛化能力和计算效率,只考虑简单的融合方法,如SUM、MAX和Concat,强调两个子网的协调和互补。
下面将更详细地描述每个DualNet架构和相应的学习方法。
双网
DualNet通过使用两个模型作为子网络来进行互补学习,但使用的模型可以是任何现有的模型,本文中使用了CaffeNet、VGGNet、NIN和ResNet。
图2显示了DualNet From CaffeNet(DNC)的示例架构。
为简单起见,在此将两个CaffeNets表示为S1和S2。特别是,端到端的CaffeNet在逻辑上被分割成两个功能部分,即提取器和分类器。
提取器和分类器之间的分割不是预先定义的,理论上可以在任何一层,但这里是在pool5中分割。池5。(有几个理由可以说明分裂的原因,但在此省略)。如果你有兴趣,请查看该文件)。
总的来说,DNC有一个对称的架构,S1Extractor和S2Extractor并行,它们产生的特征图被整合到融合分类器中。
此外,还增加了辅助的S1分类器和S2分类器,以使每个特征提取器产生的特征能够被独立识别。
然后通过对三个分类器的加权来施加互补的约束。
选择SUM作为融合方法是因为它的简单性,而且它继承了原始CaffeNet的最后一个全连接层(分类器)的参数,系数固定为{0.5,0.5}。
类似的方法被应用于16层的VGGNet、NIN和ResNet,分别 形成了DualNet From VGGNet(DNV)、DualNet From NIN(DNI)和DualNet From ResNet(DNR)。
在DNV中,S1提取器和S2提取器由VGGNet中pool5之前的层组成。
由于NIN和ResNet中没有全连接层,而且输入尺寸很小(32 x 32),最后一个卷积层(例如NIN中的cccp5)被用来平均两个子网络的特征图被平均化,最后的卷积层被用作预测3。
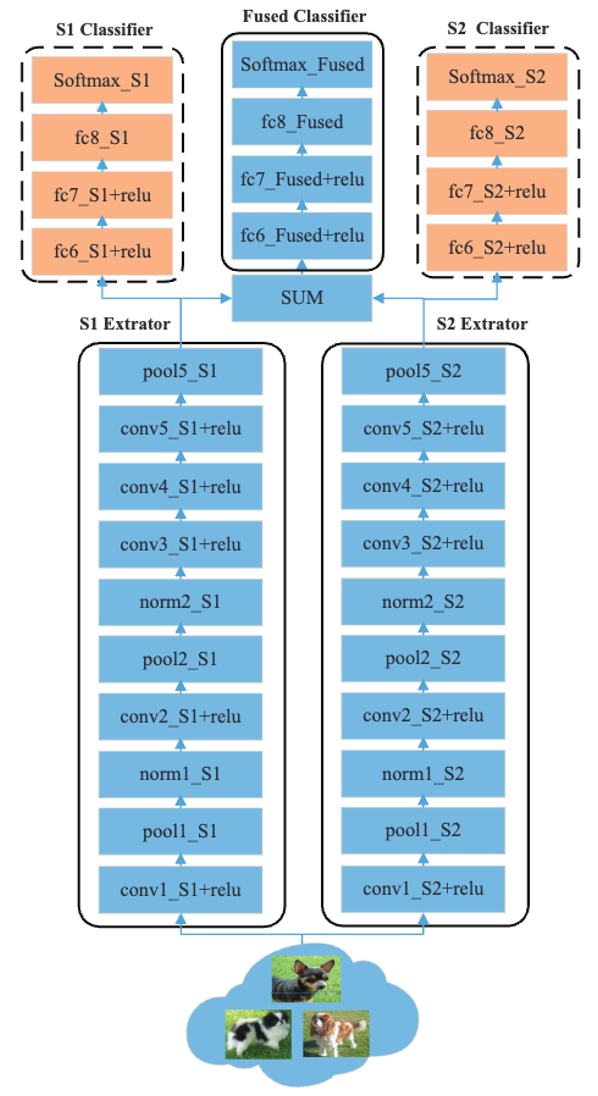
图2:DualNet From CaffeNet (DNC)的架构示例。
如何了解DNC
DNC学习包括两个主要部分:迭代训练(Iterative Training)和联合微调(Joint Finetuning),如图3所示。
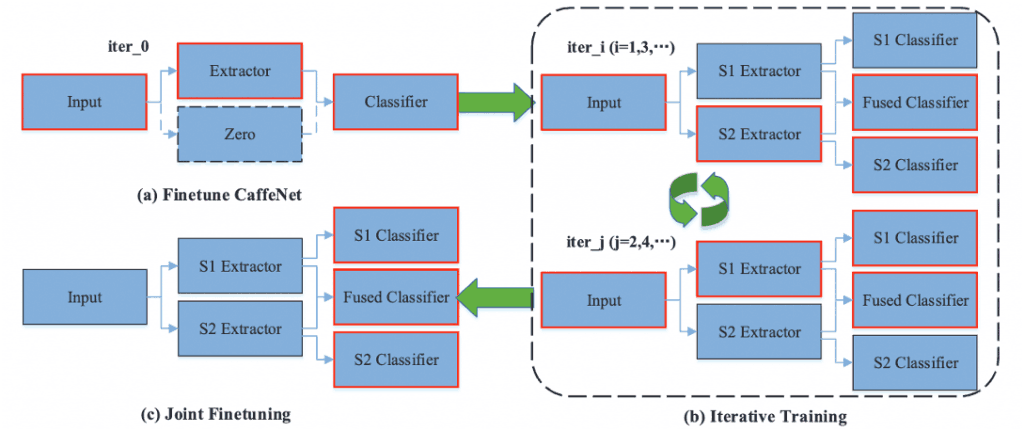 图3:DNC学习方法
图3:DNC学习方法
死记硬背
迭代学习是在S1提取器和S2提取器之间修复一个和微调另一个的迭代过程。
这种方法允许一个提取器在每次迭代时明确地学习与另一个提取器互补的特征,从而产生更具辨识力的融合特征。
以DNC为例,解释了迭代学习的具体方法。
首先,两个子网络之一的提取器和融合分类器(为简单起见,我们称它为S1)被训练(iter_0)。
这里,S1辅助分类器被省略了,因此没有被训练。
训练得到的参数被用作S1提取器和融合分类器的初始值,并从iter_1开始进行迭代训练。
(iter_i, i=1,3,...)现在,S2提取器、S2分类器和融合分类器被训练。
在训练期间,S1提取器的参数是固定的,不会更新。
具体来说,包括S2提取器、S2分类器和融合分类器在内的每个模块都根据定义为以下的损失函数进行优化。
$L_1=L_{text {Fused }}+lambda_{S2} L_{S2}$
其中$L_{text {Fused }}$和$L_{S2}$是由Softmax Fused和SoftmaxS2计算的交叉熵损失,损失权重$lambda_{S2}$为0.3。
第二个项是用于学习的正则化,$lambda_{S2}<1$是为了告知S2提取器,融合分类器在优化中更为重要。
此外,(iter_j,j=2,4,...)。),对S1提取器、S1分类器和融合分类器进行训练。
在训练期间,S2提取器的参数是固定的,不会更新。
具体来说,包括S1提取器、S1分类器和融合分类器在内的每个模块都根据定义为以下的损失函数进行优化。
$L_2=L_{text {Fused }}+lambda_{S 1}_{S 1}$
其中$L_{text {Fused }}$和$L_{S1}$是由Softmax Fused和SoftmaxS1计算的交叉熵损失,损失权重$lambda_{S1}$为0.3。
第二个项是用于学习的正则化,$lambda_{S1}<1$是为了通知S1提取器,融合分类器在优化中更为重要。
通过将融合分类器的输出与基础模型(如CaffeNet)进行比较,对这样训练出来的DualNet进行评估。
也可以通过结合三个分类器的预测来计算每个类别的概率。
$textit{score}={textit{score}_{text {Fused }}+lambda_{S 2}{textit{score}_{S 2}+lambda_{S 1}{textit{score}_{S 1}$
其中$textit{score}_{text {Fused}}$和 score S2 ,score S1指的是测试时融合分类器、S2分类器和S1分类器的输出,这个分数被用来评估识别。
联合微调
虽然DualNet中有三个分类器模块--S1分类器、S2分类器和融合分类器--但仅靠迭代学习,它们的能力并没有得到充分挖掘。
因此,本文提出了另一种集成方法来进一步提高DualNet的性能。
由于微调整个网络(如DNV)非常耗时,并且需要大量的GPU内存,因此三个分类器模块的最后一个全连接层(如DNC的fc8,DNI的ccp6)改为用以下损失函数联合微调。
$L_3=L_{text {Fused }+lambda_{S 2} L_{S 2}+lambda_{S 1} L_{S 1}$
其中$L_{text {Fused }}$,$L_{S1}$,$L_{S2}$分别是融合分类器、S2分类器和S1分类器输出的交叉熵,损失权重$lambda_{S1}$,$\\lambda_{S2}$被设定为0.3。
实验装置
在几个广泛使用的数据集上,如CIFAR-100、斯坦福狗等,DualNet From CaffeNet(DNC)、DualNet From VGGNet(DNV)、DualNetFrom NIN(DNI)、DualNet From在几个数据集上的ResNet(DNR)。
迭代学习的超参数与在特定数据集上微调标准深度模型的超参数相同,联合微调会使基础学习率降低10倍,增加几个迭代次数。
结果和讨论
图4显示了标准NIN和ResNet与所提出的DualNet From NIN(DNI)和DualNet From ResNet(DNR)方法在CIFAR100图像分类中的准确性 比较结果。
图4中的表格分别从顶部显示了以下结果。
这里,左右差异表示是否应用了数据扩展。
- 使用NIN和ResNet进行CIFAR100图像分类的结果。
- CIFAR100图像分类的结果,仅由使用迭代学习训练的融合分类器输出。
- 使用迭代学习训练的三个分类器的加权和综合输出的CIFAR100图像分类结果。
- 使用迭代学习和联合微调训练的三个分类器的加权综合输出的CIFAR100图像分类结果。
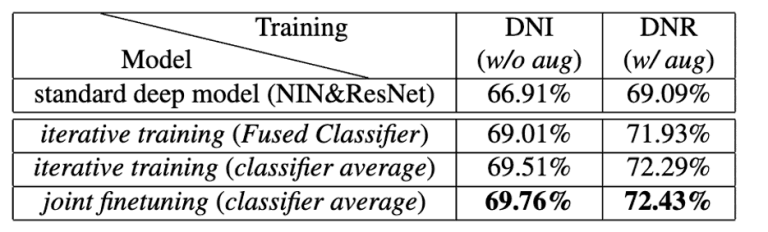 图4:拟议方法的评估结果1(CIFAR-100)。
图4:拟议方法的评估结果1(CIFAR-100)。
同样,在CIFAR100图像分类中,现有方法 与所提出的方法,即DualNet From NIN(DNI)和DualNet From ResNet(DNR)的准确性 比较结果见图5。
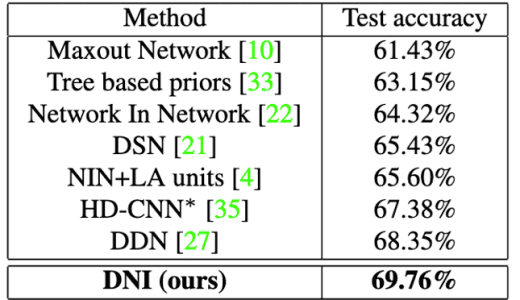 图5:拟议方法的评估结果2(CIFAR-100)。
图5:拟议方法的评估结果2(CIFAR-100)。
在这两个结果中,可以看出,所提出的方法显示了最佳的准确性。
联合微调的有效性在评价结果1中也得到了证实,因为除了迭代学习之外,使用联合微调也取得了最好的准确性。
图5显示了标准CaffeNet和VGGNet与所提方法DualNet From CaffeNet(DNC)在斯坦福狗和UEC FOOD-100图像分类中的准确性比较结果。
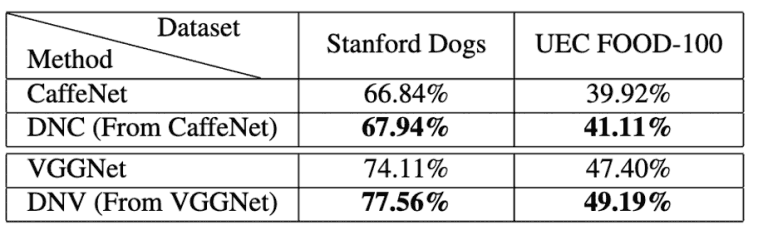 图6:拟议方法的评估结果3(斯坦福狗,UEC FOOD-100)。
图6:拟议方法的评估结果3(斯坦福狗,UEC FOOD-100)。
对于这两个数据集,所提出的方法DNC和DNV表现良好,取得了比CaffeNet和VGGNet更高的准确性。
摘要
本文提出了一个名为DualNet的通用框架,用于图像识别任务。
在这个框架中,两个平行的DCNN合作学习互补的特征,以建立一个更广泛的网络,并获得一个更具辨别力的表示。
还提出了一个相应的学习策略,包括迭代学习和联合微调,以确保两个子网络协调良好,从而充分利用这个新的框架--"双网"。
在实验中,基于CaffeNet、VGGNet、NIN和ResNet的DualNet在CIFAR-100、Stanford Dogs和UEC FOOD-100上进行了实验评估,都取得了比基线更高的准确性。
特别是,与以前的研究相比,CIFAR-100的准确性是最好的。



与本文相关的类别


![Swin 变形金刚] 基于变形金刚的图像](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2024/swin_transformer-520x300.png)



