什么是图像分类中合适的标签表示?
三个要点
✔️ 利用音频数据作为标签,提高图像分类任务的性能
✔️ 利用各种标签表示法进行实验和比较。
✔️ 证明高维和高熵标签表示法提高了稳健性和数据效率。
Beyond Categorical Label Representations for Image Classification
written by Boyuan Chen, Yu Li, Sunand Raghupathi, Hod Lipson
(Submitted on 6 Apr 2021)
Comments: Accepted to International Conference on Learning Representations (ICLR 2021).
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Computer Vision and Pattern Recognition (cs.CV)
code:
首先
在图像分类任务中,对输入图像进行类别预测。在这种情况下,作为教师数据的标签,其表现形式和格式对模型的性能有何影响?
在本文介绍的论文中,我们使用了包括音频数据在内的各种标签,并对标签表示如何影响模型性能进行了各种测试,为前面的问题提供了答案。
实验
实验设置
数据集
利用CIFAR-10/100数据集,我们尝试在图像分类中使用各种变体作为标签表示。
语音标签
以下程序用于生成语音标签。
- 英语语音由TTS(text-to-Speech)系统从对应类别的文本中生成。在这种情况下,所有的语音标签都是用相同的参数和API生成的。
- 每个音频文件以WAVE格式保存,采用16位脉冲码调制编码,并对两端的静音进行修整。
- 它转换为Mel谱图,采样率为22,050 Hz,频率为64 Mel,跳长为256。
- 我们将谱图变成一个N(输入图像维度的两倍)×N矩阵,其值从-80到0,并将其作为标签。
这个语音标签对应每个班级,每个班级一个。
更多标签
为了研究标签的哪些属性会影响到哪些,我们将使用下图所示的各种标签进行实验。
- Shuffled Speech:将语音谱图图像沿时间维度划分为64个部分,并重新排序。这个过程保留了原始语音标签的熵和维度。
- 恒定矩阵:使用一个维度,所有元素都有相同的值(零熵)。
- 高斯组合:将10个位置和方向均匀采样的高斯组合在一起。
- random/uniform-matrix:从均匀分布中随机抽取元素生成一个矩阵。它还使用维度较低的变体来研究维度的重要性。
- BERT嵌入:使用预训练的BERT模型的最后一个隐藏层的嵌入。
- GloVe嵌入:与BERT模型类似,我们使用来自预训练的GloVe模型的词嵌入。
下面是一个包括上述音频标签的标签可视化的例子。

・ 型号
我们在模型中使用了以下三种CNN。
分类模型(基线设置)由图像编码器$I_e$和类别(文本)解码器$I_{td}$组成,其中$I_e$为前文所述的CNN骨干,$I_{td}$为全耦合层。
在使用高维标签的模型中,图像编码器保持不变,而使用标签解码器$I_{ld}$代替。I_{ld}$由一个致密层和几个转置卷积层组成。
学习和评估
分类模型是通过交叉熵损失来训练的,当使用高维标签时,模型的训练是为了最小化以下方程(采用Huber损失)。
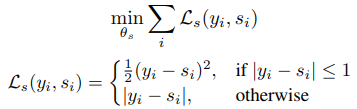
分类模型和一般的分类任务一样,如果以最高概率预测的类与目标类相同,则认为是正确的。高维标签有两种不同的测量形式。
- 选择最接近模型输出的地真标签(NN:最近的邻居)。
- 如果与真实标签的Huber损失(平滑L1损失)低于某个阈值(实验中为3.5),则认为预测正确。
实验结果
上述所有标签的分类准确率如下图所示。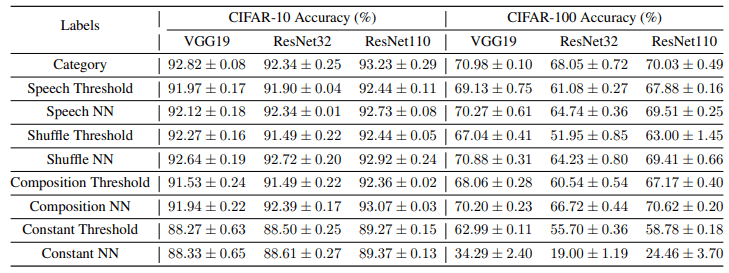
语音标签、洗牌语音标签和混合高斯标签表现出与传统分类标签相当的性能,而恒定矩阵标签则表现出轻微的性能下降。
学习曲线如下图所示,这也显示了使用恒定矩阵标签的训练难度。
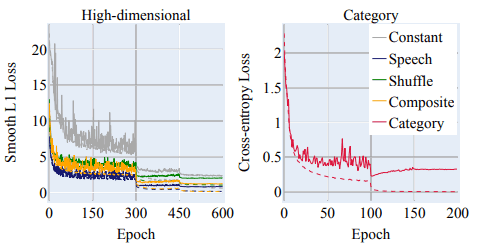
关于稳健性
为了评估模型的鲁棒性,我们使用FGSM和迭代方法进行对抗性攻击。在这种情况下,我们只对正确分类的图像进行攻击,以调查性能的保持情况。
结果(测试精度)如下图所示。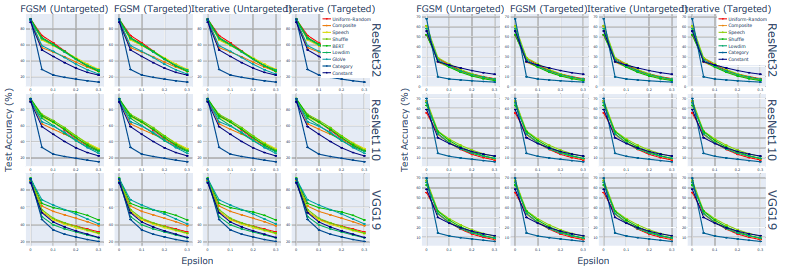
图中左侧为CIFAR-10的运行结果,右侧为CIFAR-100的运行结果。所有模型的准确率都会随着攻击强度的增加而降低(abscissa:Epsilon),但在所有情况下,语音/颤音语音/高斯标签的表现都明显优于传统类别标签。
统一随机矩阵(Uniform-Random/Lowdim)即使在低维情况下也表现出了优异的性能,而由常数矩阵组成的标签(Constant:紫色线)表现出了相对较低的性能。这表明,除了标签的高维度外,其他一些属性提高了模型的鲁棒性。
关于训练数据效率
对于CIFAR-10数据集,我们只使用1%、2%、4%、8%、10%和20%的训练数据进行训练。本案例中的测试精度如下。
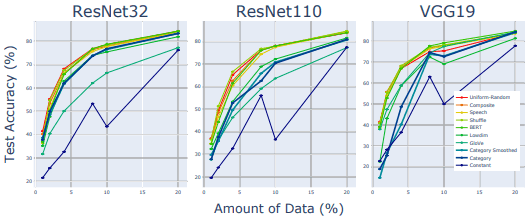
总体而言,结果与稳健性评价的结果相似。特别是常数矩阵标签的性能低于其他高维标签,说明除了高维度以外的一些特性影响了性能。
然而,低维均匀随机矩阵(Lowdim)的结果与鲁棒性评估不同,与高维矩阵相比,显示出较差的结果。
高维和高熵表征的有效性。
本文假设"高熵的高维标签表示"是标签表示的一种属性,这种属性对于有效的特征表示是有用的,可以提高标签的鲁棒性和数据效率。
对于这个假设,我们在下表中列出了各种标签表示的统计结果。
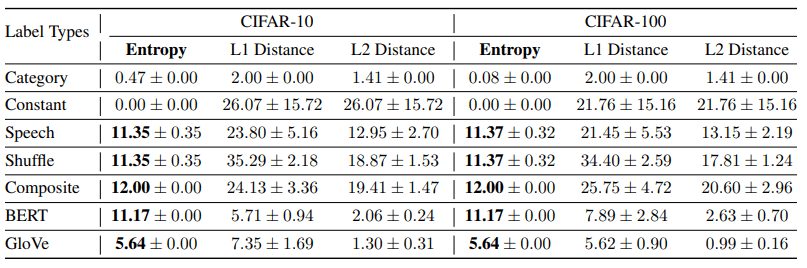
L1/L2距离显示不同标签对之间的距离。
在鲁棒性和数据效率方面表现出最佳效果的标签(如语音/杂音语音/混合高斯)的熵均高于常规类别标签和恒定矩阵标签,强化了前面的假设。
特征可视化
在CIFAR-10上训练的ResNet-110的情况下,使用t-SNE进行特征可视化的结果如下。
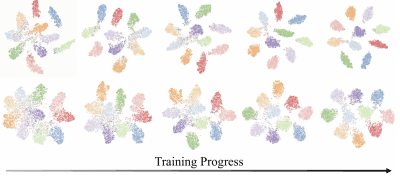
上行是使用语音标签时的结果,下行是使用类别标签时的结果。学习进度从左到右,分别完成10%、30%、50%、70%、100%的学习。
与类别标签相比,语音标签的特征表示显示,在训练的早期阶段形成了聚类,随着训练的进行,聚类的分离度越来越高。
摘要
在本文介绍的论文中,我们表明在图像分类任务中用高维和高熵矩阵(如音频谱图)替换类别标签,可以提供出色的鲁棒性和数据效率。
我们已经表明标签表征会影响模型的性能,这就导致了一个问题,即用于训练模型的类别标签是否真的有效。这是一项重要的研究,为标签表征的作用提供了一个新的视角。



与本文相关的类别


![Swin 变形金刚] 基于变形金刚的图像](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2024/swin_transformer-520x300.png)



