ReLabel,一种使用本地标签的多重标记对ImageNet进行重新标记的方法!
三个要点
✔️建议的ReLabel,一种在ImageNet中进行多类重新标记的方法
✔️还提出了LabelPooling,一种对多类标签进行判别性学习的方法。
✔️ReLabel在ImageNet的基准测试、转移学习和多标签识别等任务上效果良好。
Re-labeling ImageNet: from Single to Multi-Labels, from Global to Localized Labels
written by Sangdoo Yun, Seong Joon Oh, Byeongho Heo, Dongyoon Han, Junsuk Choe, Sanghyuk Chun
(Submitted on 13 Jan 2021)
Comments: 15 pages, 10 figures, tech report
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
首先
图像网ImageNet是一个非常有用的数据集,用于计算机视觉中的许多任务,并且有大量的类。然而,当你尝试在实践中使用ImageNet时,你会发现ImageNet图像包含多个类别,而且很多类别非常混乱(例如狗的类型)。因此,在用ImageNet进行训练时,其他类可能会被输出或识别为类似的类。出于这个原因,最近的研究试图在ImageNet上进行多重标签(Lucas等人, Vaishaal等人),并提出了多重标签的评估方法。此外, 他们还发现,他们的方法在多标签数据集的辨别任务中的表现低于人类的表现(Qizhe等人, Huga等人)。
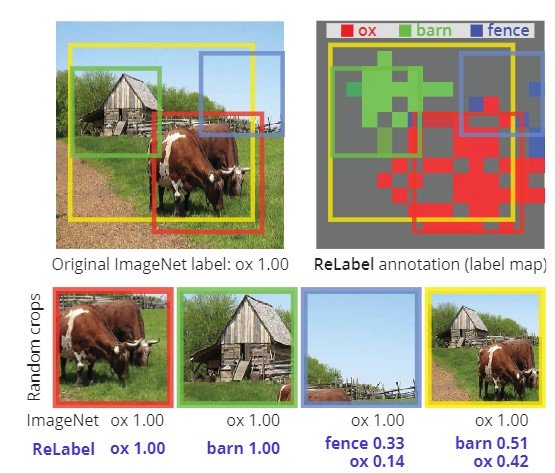
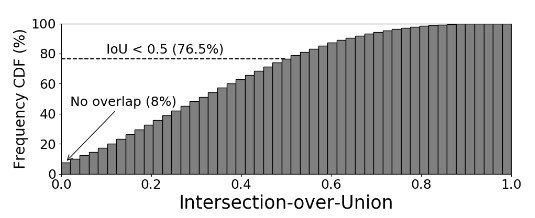
对有多个对象的数据只分配一个标签的问题不仅影响评估,也影响训练,给数据集增加了噪音。特别是,随机裁剪可用于填充,如图1所示,它可能包括被裁剪图像中的不同物体,或者随机裁剪可用于裁剪没有物体的区域,甚至只有一个物体。实验表明,使用ImageNet训练集,在使用随机裁剪时,8%的图像没有被正确裁剪,只有23.5%的图像有正确的方框和大于50%的IoU(图2)。
因此,对于多重标记,要进行新的标记。由于对128万个ImageNet样本进行人工标注需要花费大量的时间,他们在这项工作中提出了ReLabel作为一种重新标注的方法,它能够对多个标签和局部标签进行像素化标注。在下文中,他们描述了使用ReLabel和LabelPooling的标签,它通过汇集每个随机作物样本的标签分数,输出多个标签的正确答案数据。
建议的方法:重新标记
作者提出了一种重新标记的方法,"ReLabel",为ImageNet训练集输出像素级的正确标签。有两种类型的目标标签图。
- 多类标签
- 本地标签
标签图是基于在额外数据上训练的SoTA图像判别器,为了训练具有局部多标签的图像判别模型,他们提出了一个学习框架"LabelPooling"来创建标签图。在下文中,他们将逐一解释。
对图像网进行重新标记
首先,为了获得正确的标签,由于人工标注的成本巨大,他们使用一个巨大的数据集,如JFT-300M和InstagramNet-1B,名为super-ImageNet,来训练一个图像判别器,然后他们使用ImageNet通过微调,他们创建了一个可以预测ImageNet类别的学习模型。
这里值得一提的是,ImageNet被训练为输出单一标签(使用softmax交叉熵损失),但当图像中存在多个类别时,它也会预测多个标签。原因是交叉熵损失被用作判别器的损失函数,正确的类别和图像被作为输入,此外,还有其他标签存在。然后,为了与其他标签区分开来,交叉熵损失如下。
begin{equation}-\frac{1}{2}(\Sigma_k y^0_k \log p_k(x) + \Sigma_k y^1_k \log p_k(x)) = - \Sigma_k \frac{y^0_k + y^1_k}{2} \log p_k(x) }end{方程}
其中$y^c$是索引为$c$的单热向量,而$p(x)$代表图像$x$的预测向量。
为了使这种交叉熵损失最小化,当$p=q$为$-Sigma_k q_k log p_k$时,也就是用$p(x)=(\frac{1}{2}, \frac{1}{2})$进行预测。其中,$q$是标签(1或0),$p$是要标记的预测向量。这使得一个具有单标签交叉熵损失的模型在数据集中存在多标签噪声的情况下可以输出多个标签。
此外,他们可以用这个判别器来获得局部标签。通过取消常规判别器中的全局平均池化层,并在1 x 1卷积层中加入一个线性层,判别器作为一个完全耦合的网络(Bolei等人, Jonathan等人),模型的输出是$f(x) \ in \mathbf{R}^{WxHxC}$,输出的$f(x)$被用作标签图注解$L\in `mathbf{R}^{WxHxC}$。详细数字如下。
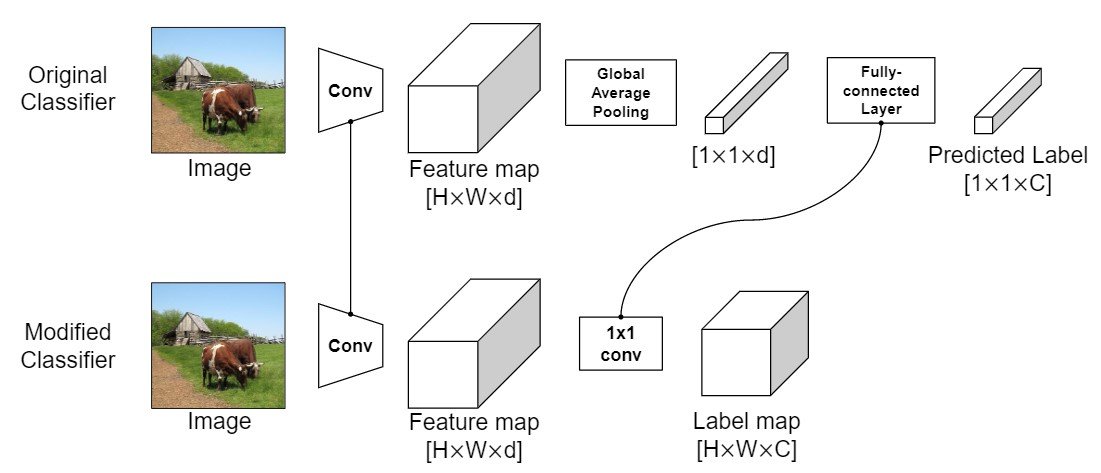
该鉴别器输出的标签图如下所示。图中显示的是top-2类别的热图。
学习多标签的图像鉴别器
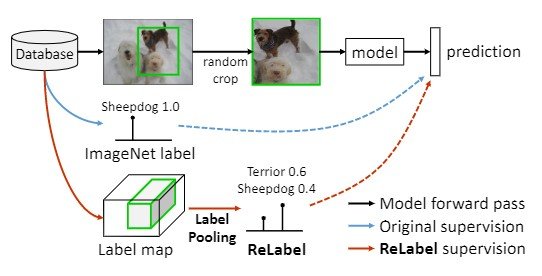
作为一种用多个标签$L\in\mathbf{R}^{WxHxC}$学习的方法,本研究提出了LabelPooling;LabelPooling通过考虑局部正确数据来支持多个数据(图3)。
在一个典型的ImageNet训练设置中,每张图片都有一个标签用于随机裁剪图片。另一方面,LabelPooling使用预先定义的标签图,对随机裁剪对应的区域进行区域池化。ROIAlign区域集合法)全球平均集合法和softmax被用来预测多个标签。伪装代码如下。

实验和结果
他们对所提出的局部多标签标签进行了实验,并在各种任务上用它进行学习。为了比较多种网络结构和评价指标,他们在ImageNet上使用ReLabel进行图像识别。然后,他们通过对用ReLabel训练的模型在图像检测、实例分割和图像识别任务上进行迁移学习来评估性能,并进一步证明ReLabel在COCO数据集的多标签识别任务上产生了良好的准确性。所有实验都是在下面的NAVER Amart机器学习(NSML)平台上使用PyTorch进行的。
图像网络中的图像识别
ImageNet-1K基准测试是用来评估ReLabel的。该数据集包含128万个训练集,5万个评估图像和1000个类别。对于数据填充,他们使用随机剪裁、翻转和颜色抖动。他们从0.1的学习率开始,用SGD训练了300个epochs。批量大小为1024,重量衰减率为0.0001。
标记方法的比较
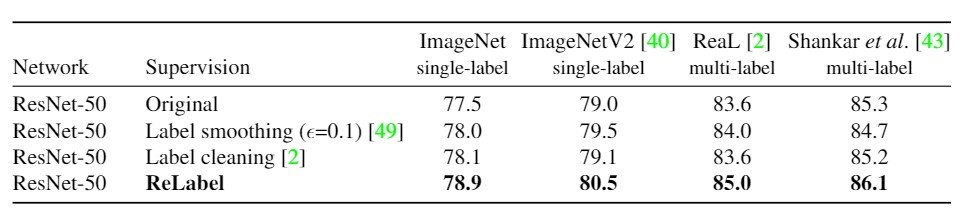
作为第一个实验,他们将标签平滑法与其他标签方法进行比较:标签平滑法对前面的类使用小权重$(1-epsilon)$,对后面的类使用$epsilon$。标签清洗是一种方法,如果教师判别器的预测与正确答案数据的注释不同,则将数据从训练样本中删除。在这项研究中,他们使用了标签清理后的精炼数据集,并在ResNet-50上实验了ReLabel。 结果显示在表3中,他们在ImageNet和ImageNetV2的评估数据集上确定了单一标签的准确性。另外,为了找到多标签的准确性,这里他们使用ReaL和Shankar数据集进行比较。
评价方法是$frac{1}{N}\Sigma^N_{n=1} 1 (argmax f(x_n) \in y_n)$其中$1(\cdot )$是指标函数,$argmax f(x_n)$是模型$f$的top-1预测值。$N$是班级的数量。图像$x_n$的正确数据由$y_n$表示。该表显示,ReLabel在所有指标上都是最准确的,只有ReLabel在多标签基准上明显更准确。
各种网络结构的比较
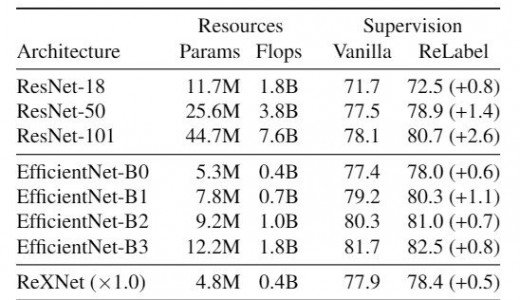

ReLabel是一个通用结构,可以用于使用不同学习方法的各种网络。在此,他们用ResNet-18、ResNet-101、EfficientNet-{B0、B1、B2、B3}和ReXNet进行了实验。如上表所示,他们观察到使用ReLabel的所有网络的准确性都有所提高。
在他们之前的工作中,通过对CutMix算法的剪裁图像使用ReLabel,他们也实现了ImageNet top-1的准确率SoTA。
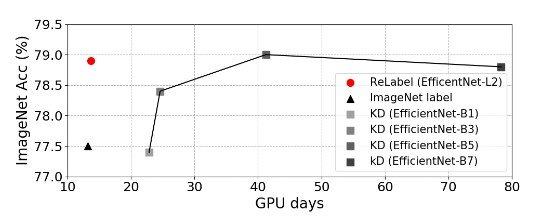
此外,他们比较了知识提炼(KD)和ReLabel,以评估学习时间成本。然而,他们发现,学习EfficientNet的时间至少是ReLabel的三倍。
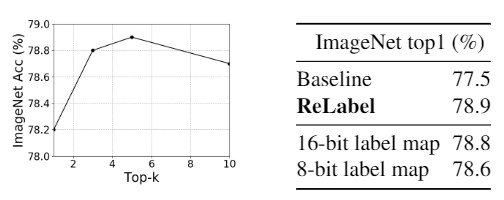
接下来,他们研究了在使用ReLabel训练时内存存储和性能之间的权衡。通常情况下,ReLabel在top-k(k=5)的情况下实验效率很高,但他们发现随着使用数据数量的增加,内存不堪重负,准确率也随之下降。此外,他们发现,在对标签图进行量化时,16位量化比8位量化更准确。
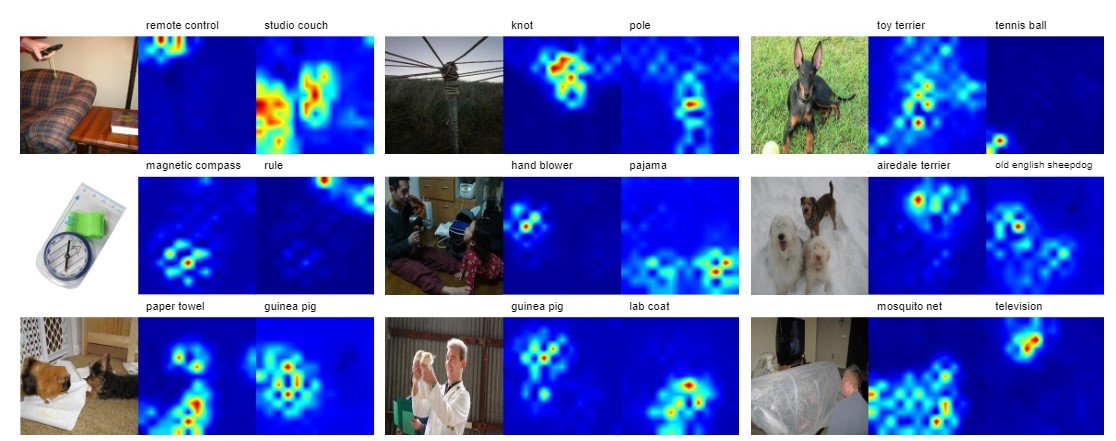
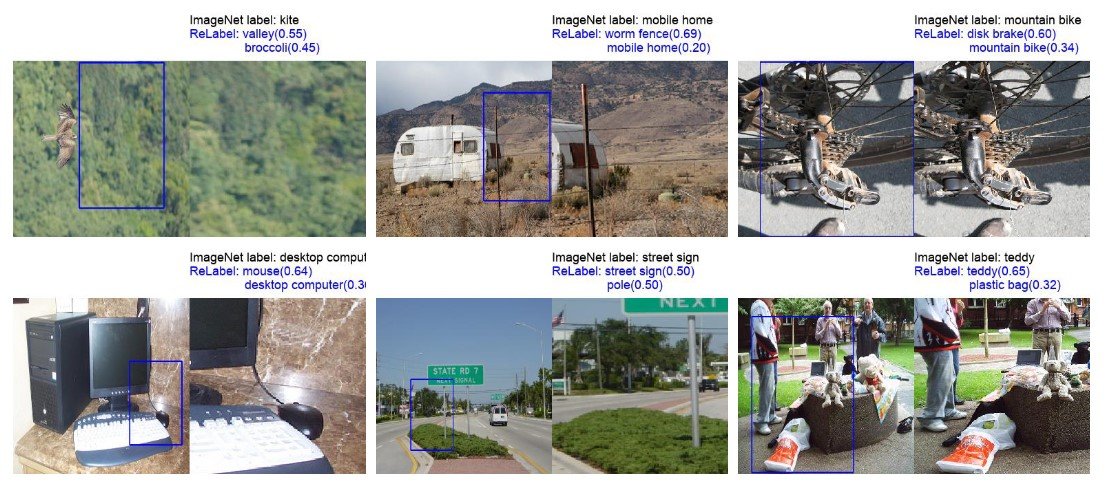
使用ReLabel的输出图像结果如下。
转移学习
作为一个标准的基准,ImageNet被广泛用作预训练的模型。在这里,他们用ReLabel在ImageNet上进行了转移学习的实验,使用COCO数据集进行五个细粒度的辨别任务、物体检测和实例分割任务。

他们在几个数据集上进行了辨别任务的实验,结果如上表所示,他们可以看到,用ReLabel训练时,每个数据集的性能都更好。在训练期间,他们使用SGD进行了5000次迭代,并使用网格搜索进行超参数调整。
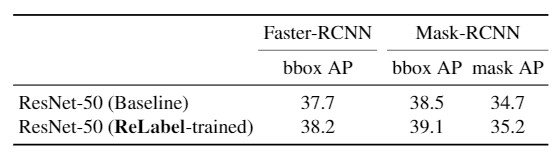
此外,他们可以看到,Faster-RCNN和Mask-RCNN在物体检测和实例分割任务中都提高了0.5 pp和平均精度。
多重标签识别
由于随机裁剪灌水对学习多个标签是有效的,他们测试在ReLabel和LabelPooling中增加本地信息是否能使学习多个标签更加有效。为了实验,他们使用了COCO数据集和人类注释的数据。他们还研究了使用机器学习创建的标签图神谕的效果。然后,他们根据根据随机作物坐标创建的标签图,使用LabelPooling训练了一个多标签判别器。224 x 224和448 x 448的输入图像被用来输入ResNet-50和ResNet-101网络,二进制采用了交叉熵损失。
结果显示如下。
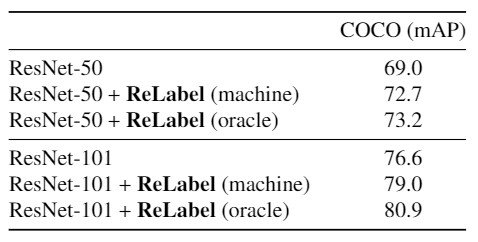
该表显示,使用ReLabel和机器学习创建的标签图,ResNet-50的mAP为+3.7pp,ResNet-101为+2.4pp,而使用oracle标签图,ResNet-50的mAP为+4.2pp,ResNet-101为+2.4pp。在ResNet-101上的4.3pp。这使他们能够提高ReLabel在学习位置明智的多标签识别方面的性能。
摘要
ImageNet数据集,在图像识别方面很突出,标签噪声很可怕,而且有多个类别的对象,而它是一个单一的标签基准。因此,在以前的研究中,对多个标签进行了注释,但由于注释成本巨大,成本需求不高,其结果是在训练时有时会出现多个对象被裁剪,甚至随机的图像裁剪也经常被识别为不同的对象。因此,在本研究中,他们提出了针对ImageNet训练集的ReLabel,它可以将单标签训练转换为多标签训练。他们还提出了LabelPooling,它在最后一个池化层之前使用像素化的多标签预测,以便用更强大的图像识别模型和额外的图像数据生成多个标签。结果,他们在ResNet-50上取得了78.9%的识别准确率,在ImageNet上使用CutMix正则化取得了80.2%的准确性。此外,他们发现,在过渡学习和多种基准上,性能得到了提高。预计它将在未来被应用于各种数据集。



与本文相关的类别


![Swin 变形金刚] 基于变形金刚的图像](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2024/swin_transformer-520x300.png)



