
我们能相信分类器的输出概率吗?"AdaFocal "是一个用于提高校准性能的损失函数。
三个要点
✔️ 提出了 AdaFocal,以自适应地调整 Focal Loss 的超参数 γ
✔️ 实现了较高的校准性能,同时与现有方法相比保持了相当的分类性能
✔️ 证实了在分布外检测任务中的有效性
AdaFocal: Calibration-aware Adaptive Focal Loss
written by Arindam Ghosh, Thomas Schaaf, Matthew R. Gormley
(Submitted on 21 Nov 2022 (v1), last revised 16 Jun 2023 (this version, v2))
Comments: Published in NeurIPS 2022.
Subjects: Machine Learning (cs.LG); Computer Vision and Pattern Recognition (cs.CV)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
分类问题涉及估计数据属于哪个类别,是机器学习的典型任务之一。例如,一个可能的问题是确定图像中的东西是狗还是猫。对于这个问题,机器学习模型会计算出该物体是狗的概率和是猫的概率,并判定概率较高的物体就是图像中的物体。对于各种分类问题,机器学习模型的分类性能已超过 90%。
但是,分类中使用的概率正确吗?
例如,如果您收集的样本被判定为 "90% 是狗",那么您真的会得到其中 10% 不是狗的结果吗?近年来,人们一直在研究校准问题,即分类器的输出概率与正确概率的匹配问题,而 Focal Loss 是改进校准的一种方法。本文提出了 Focal Loss 的改进版Ada Focal,以进一步改进校准。
校准评估方法。
本节介绍校准问题中的评估指标。
由于数据集有限,无法确定准确的校准误差(校准误差)。因此,校准误差的估计值被用于评估。估计误差的方法有很多种,但本节将介绍预期校准误差 (ECE) ,这也是本文使用的主要方法。
![]()
ECE 是通过计算每个样本组概率接近的校准误差并求和得到的,其中M是样本组数[1],N是总(评估)数据数。
Bi表示第 i 个样本组所包含的数据集;ECEEM对所有样本组进行划分,使其具有相同的个体数量(EM:Equal Mass),如下式所示。
![]()
Ai代表样本组 Bi中正确答案的百分比。
![]()
Ci代表样本组 Bi的平均概率。
![]()
病灶损失
本节介绍 Focal Loss,拟议的方法(AdaFocal)就是基于 Focal Loss 提出的。
概述。
焦点损失(Focal Loss)最初是为了提高分类器性能而提出的,其方法是减少交叉熵损失(Cross Entropy Loss)中易于分类的样本(简单样本)的训练权重,并允许对难以分类的样本(困难样本)进行强化训练。焦点损失可以表示为
![]()
该公式由交叉熵损失(-logp)乘以(1-p)γ得出。 p 越接近 1(易样本),(1-p)γ的值就越小,这意味着硬样本的相对权重可以增加。等于交叉熵损失。
校准特性
随后,焦距损失也被证明可以改进校准。其原因可以用以下关系来解释
![]()
从上式可以看出,降低 Focal Loss 会减少 KL Divergence,增加预测向量 p 的熵。这被认为可以防止模型过于自信,做出错误的预测,从而改进校准。
挑战
Focal Loss 的难点在于如何确定超参数 γ。
下图比较了 ResNet50 在 CIFER-10 上进行交叉熵损失(CE:γ=0)、γ=3、4、5(FL-3/4/5)的焦点损失和样本相关焦点损失(FLSD-53)[2]训练时的标定精度。)[2],比较用以下方法训练时的定标精度。(a)显示了 ECEEM(上述校准评估指标之一)的总体评估结果;(b)显示了低预测概率(Bin-0)、中预测概率(Bin-7)和高预测概率(Bin-14)样本组的校准误差的逐次变化。Bin-0、Bin-7、Bin-14、Bin-14、Bin-7、Bin-14。
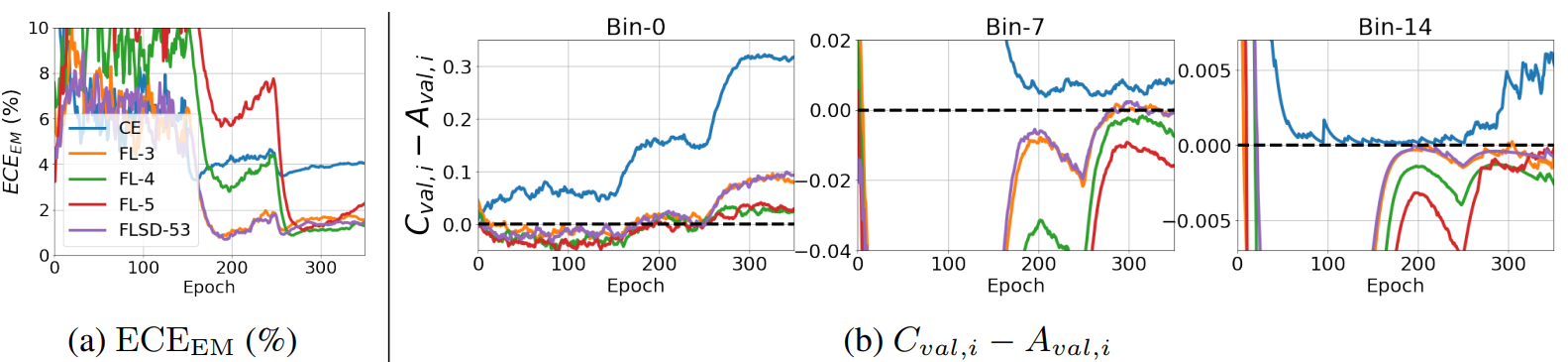
比较固定的 γ(CE、FL-3/4/5),(a) 中的图表显示,总体而言,γ = 4 时的校准效果最好。然而,(b) 显示,γ = 4 并非最佳,这取决于预测概率的大小 (Bin-7)。换句话说,在校准中很难定义一个合适的 γ。
FLSD-53 根据预测概率的大小改变 γ,在 Bin-0、7 和 14 的所有情况下也没有给出最佳结果。
从这些结果可以看出,有必要以更合适的方式为每一级预测概率定义 γ。
建议方法
AdaFocal 可在焦距损失和反向焦距损失之间切换,上文已对焦距损失进行了解释,但反向焦距损失不在其中。在继续解释 AdaFocal 之前,我们将解释反焦距损失。
反向病灶损耗
上文已经解释过,"焦点损失"(Focal Loss)的作用是降低简单样本的权重,防止模型过于自信而做出错误的预测。相反,如果模型缺乏自信呢?
本文建议使用反焦点损失来解决模型缺乏信心的问题,其表达式如下
![]()
Focal Loss 中的 (1-p) 项在 Inverse Focal Loss 中被改为 (1+p)。这与 "焦点损失 "相反,会给简单样本带来较大的梯度,从而使模型被训练得过于自信。
AdaFocal 适当使用 Focal Loss 和 Inverse Focal Loss 来指导学习过程,使模型输出的概率恰到好处,既不会过于自信,也不会信心不足。
AdaFocal -如何更新伽玛。
本节将介绍如何在 AdaFocal 中调整超参数 γ,这是 Focal Loss 的一个问题;AdaFocal 中更新 γ 的公式如下。
![]()
AdaFocal会根据验证数据中观察到的校准误差(Eval, b = Cval, b - Aval,b)调整 γ。λ是一个超参数,决定每次更新(历元)调整 γ的程度。λ是一个超参数,决定了每次更新(历时)对γ的调整程度[3]。
更新后的γ 公式是根据下面的想法设计的。
- Cval,b - Aval, b > 0 (Cval,b> Aval,b):
由于模型的输出概率往往会超过实际正确答案的百分比,因此模型的训练方式是抑制对模型的过度信任。因此,应增加 γ,以降低简单样本的权重。 - Cval,b - Aval,b < 0 (Cval,b< Aval,b):
由于模型的输出概率往往低于实际正确答案的百分比,模型被训练得过于自信。因此,应降低 γ,以增加简单样本的权重。
另外,γt 也可以扩展表示如下。![]()
从这个等式可以看出,随着历时(t)的增加,γt 的值有爆炸的趋势。因此,需要为 γt设置上限(γmax)和下限(γmin),以防止爆炸[4]。
AdaFocal -在焦距损失和反焦距损失之间切换。
随着 γ 的减小,小于硬样本重量的易样本重量逐渐增加(相对增加),当 γ 减至零时(交叉熵损失),两者的重量相同。如果我们考虑到 γ 进一步减小的情况,那么相对于硬样本的权重,易样本的权重自然会增加。因此,当 γ 变为负值时,我们将切换到反焦距损耗。换句话说,当 γ> 0 时,使用参数 γ 的 Focal Loss;当 γ < 0 时,使用参数|γ|的 Inverse Focal Loss。
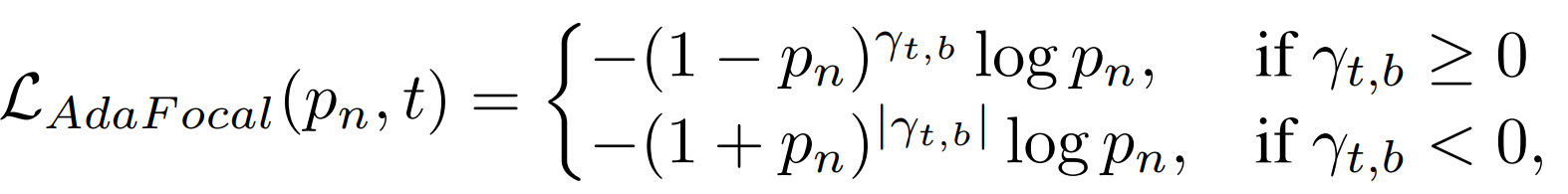
然而,在实际训练中,当 |γ| 低于阈值 Sth时,即使 γ 的正值或负值没有变化,焦点损失和反焦点损失也会切换[5]。
AdaFocal - 摘要。
迄今为止所描述的 AdaFocal 算法可概括如下。
试验
验证分类问题中的校准性能。
在图像分类(CiFAR-10、CiFAR-100、Tiny-ImageNet 和 ImageNet)和文本分类任务(20 个新闻组数据集)上评估了所提方法的性能。图像分类任务使用的是 ResNet50、ResNet100、Wide-ResNet-26-10 和 DenseNet-121,文本分类任务使用的是 CNN 和 BERT。除了交叉熵损失(CE)和上述样本开发焦点损失(FLSD-53)作为基线外,其他校准学习方法包括 MMCE、Brier 损失和标签平滑(LS-0.05),并与 AdaFocal 进行了比较。此外,还对有无温度缩放进行了比较。
在 ECEEM中对每种方法的评估结果如下表所示。
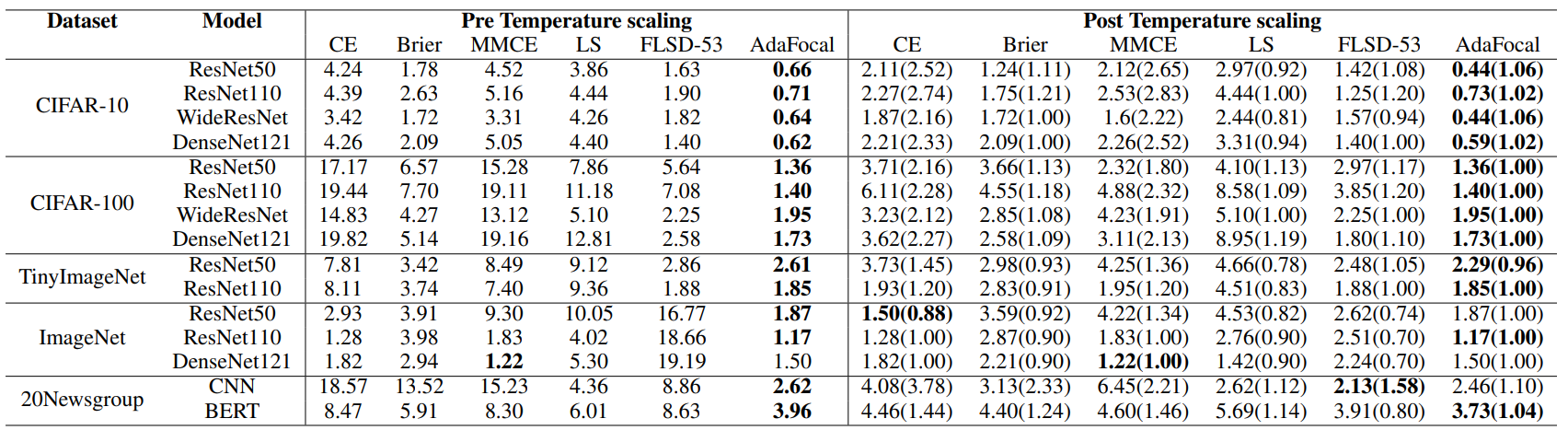
可以看出,AdaFocal 在大多数数据集、模型和实验设置上都表现最佳。
下图直观显示了分类错误率和 ECEEM在每个纪元的变化情况。
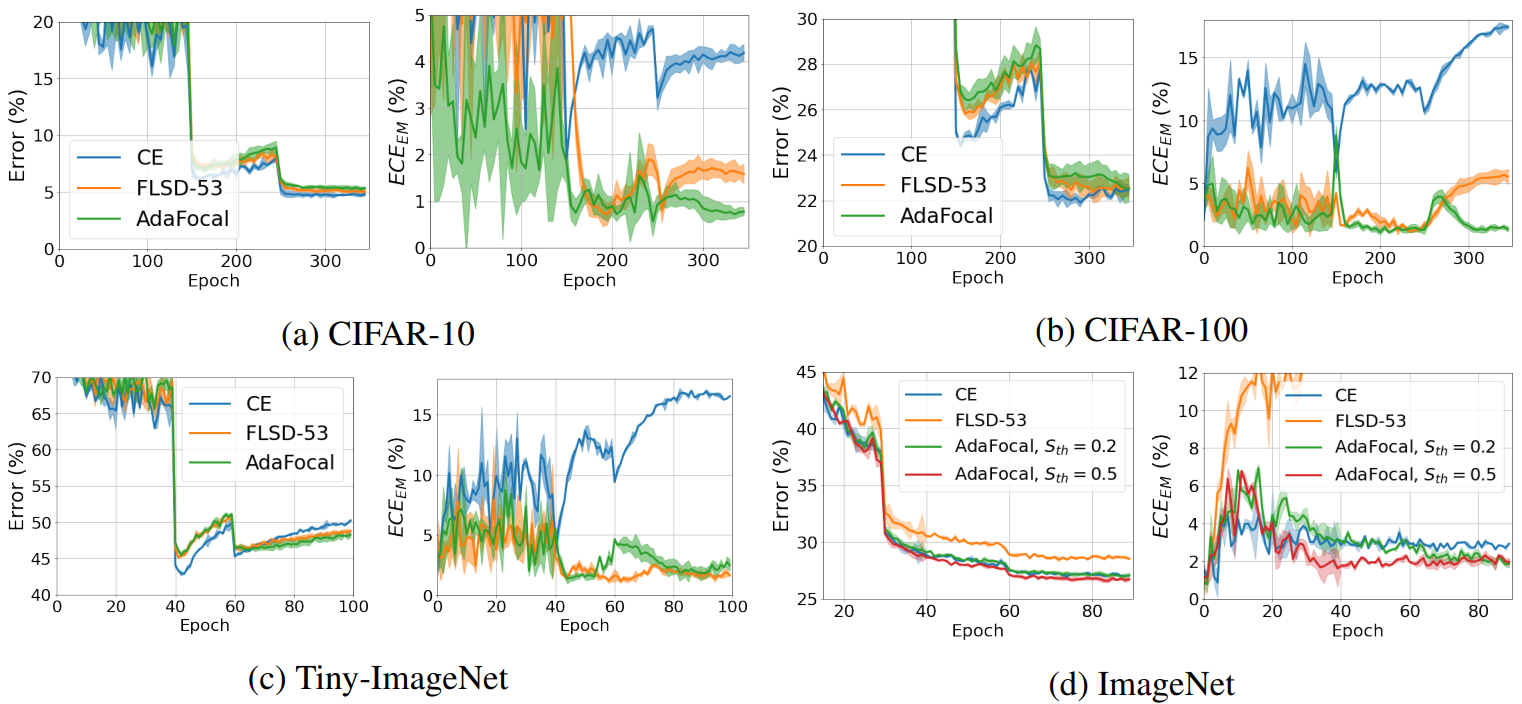
这些图表显示,AdaFocal 可实现较低的校准误差,同时保持与其他方法相当的分类性能。
配送外检测任务(配送外检测)
本文还在分布外 (OOD) 检测任务[6]中验证了 AdaFocal:在 SVHN 和 CIFAR-10 加上高斯噪声的数据集上,使用 ResNet-110 和 WideResNet。ResNet-110 和 WideResNet 在包含 SVHN 和 CIFAR-10 加上高斯噪声的数据集上。对比方法为 Focal Loss (γ=3) 和 FLSD-53。对这些方法进行了无温度和有温度测试。
下图显示了 ROC 曲线的结果。
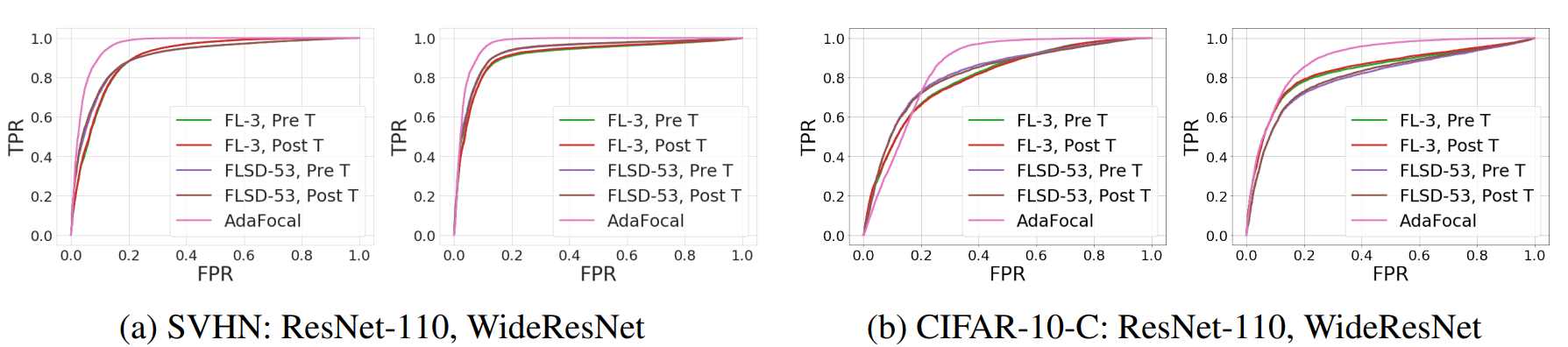
在 ROC 曲线中,面积越大表示性能越好。这些曲线图显示,AdaFocal 的性能最好。因此,可以说 AdaFocal 在 OOD 检测任务中非常有用。
摘要
AdaFocal 是 Focal Loss 的改进版本。
在分类任务中,AdaFocal 的分类性能与现有方法不相上下,同时在许多情况下改进了校准。
它在 OOD 检测任务中也很有效。
从这些结果中可以看出,AdaFocal 对提高人工智能的可解释性和可靠性很有帮助。
补贴
[1] 本文中,M = 15。
[2]FLSD允许γ根据模型对正确答案标签的预测概率而改变。本文中,当模型的预测概率介于 0 和 0.2 之间时,γ = 5;当预测概率介于 0.2 和 1 之间时,γ = 3。
[3] 本文使用 λ=1 是因为发现当 λ=1 时准确率更高。
[4] 本文中,γmin=-2 γmax=20。
[5] 本文中,Sth=0.2。
[6] OOD 检测任务是检测未包含在训练数据中的输入数据的任务。
以下链接提供了有关该主题的更多信息。
以下链接提供了有关该主题的更多详细信息。



与本文相关的类别

