[材料信息学]CGCNN-转移学习模型在财产价值方面的数据缺陷
三个要点
✔️ 晶体图卷积神经网络(CGCNN)用于过渡学习(TL-CGCNN)。
✔️ 晶体图描述符只使用材料的晶体结构作为解释变量。
✔️ 用容易获得的属性的大数据进行预训练,可以准确预测难以获得的其他属性。
Transfer learning for materials informatics using crystal graph convolutional neural network
written by Joohwi Lee, Ryoji Asahi
(Submitted on 20 Jul 2020 (v1), last revised 29 Jan 2021 (this version, v4))
Comments: Published in Comp. Mater. Sci
Subjects: Materials Science (cond-mat.mtrl-sci); Computational Physics (physics.comp-ph)
code:
本文所使用的图片要么来自该文件,要么是参照该文件制作的。
如何处理因数据不足而导致预测业绩不佳的问题...
与计算机视觉和自然语言处理等领域不同,材料信息学(MI)领域往往有少量积累的数据。问题是,机器学习并不能提供足够的预测准确性。这是因为从实验中可以获得的数据量是有限的,而利用计算科学进行的模拟往往需要大量的资金来计算。
一个解决方案是转移学习,它最近在MI领域引起了很多关注。这个想法是,一个在有大数据的财产上预先训练过的模型,可以用来预测另一个财产。
描述符的选择
材料发现的另一个重要挑战是开发多功能的材料描述符,可以预测广泛的目标变量(属性值)。由于一种材料的物理特性在很大程度上取决于其晶体结构和组成元素,因此已经根据这些结构特性开发了许多描述符。例如库伦矩阵、SOAP(原子位置的平滑重叠)和R3DVS(互换三维体素空间)。
近年来,Xie和Grossman提出了CGCNN(晶体图谱卷积神经网络),它只需要材料的晶体结构就能完成分类和预测任务。使用CGCNN执行分类和预测任务所需的唯一信息是材料的晶体结构,从中可以构建一个晶体图结构,深度神经网络可以从中预测目标变量(属性值)。
当使用描述符来学习过渡时,重要的是能够以高精确度预测与预训练中使用的描述符不相关的属性。如果描述符没有捕捉到材料结构的基本特征,就不可能学习到广泛的特性的转变。
在这项研究中,我们研究了一个结合了CGCNN和转移学习(TL)的模型的性能。
建立模型
CGCNN
CGCNN包括一个从晶体结构创建图结构的部分,以及一个由嵌入层、卷积层、池化层和全连接层组成的深度CNN部分。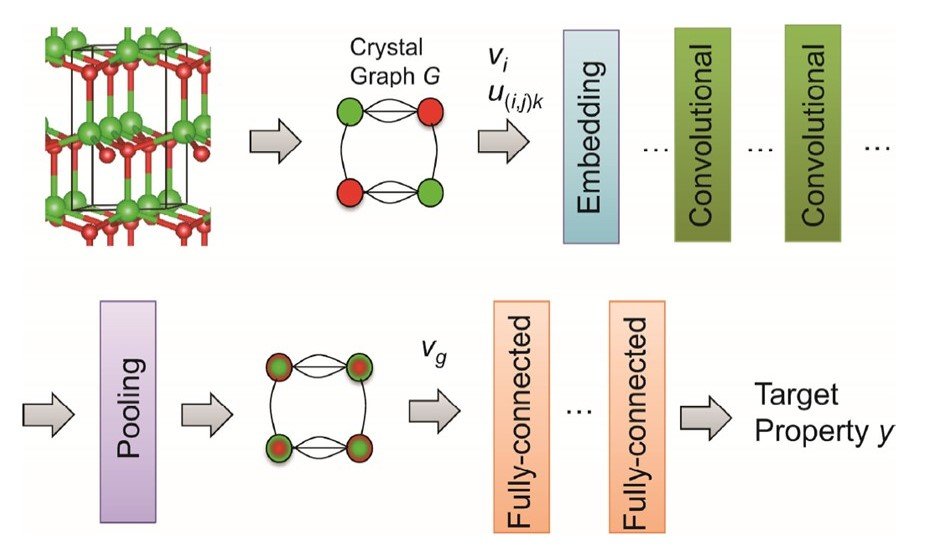
晶体图G被表示为一个离散的描述符,其中原子组、原子数和原子间的距离被表示为二进制数字。节点代表原子,边代表化学键,由晶体结构中的原子组、间接键、原子属性和键属性组成。这个离散的描述符随后在嵌入层中被转化为一个连续的描述符。然后,连续描述符被送入卷积层。
在第i+1个卷积层中,原子属性向量vi由以下方式表示
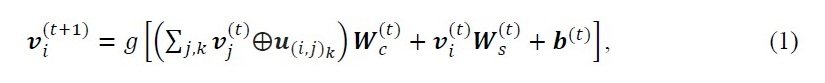
u(i,j)k 。键合属性的向量(第i个原子和第j个原子之间的第k个键)。Wc :卷积的权重矩阵,以及 Ws :自身的权重矩阵, b :第t层的偏置,g:软加函数,v和u之间的符号:v和u的串联
然而,上述公式有一个问题,即很难识别单个原子之间的相互作用,因为晶体结构中所有相邻原子的原子和键向量共享一个重量矩阵。因此,我们采用了标准的边缘门控技术。为此,我们使用概括了相邻原子之间特征的向量z(i,j)k来表示原子属性向量vi,如下所示

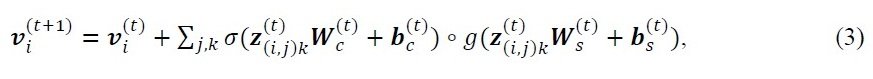
σ:西格玛函数,○:σ的逐元乘法。
Xie和Grossman报告说,这种方法的预测性能更好。然后,vi被送入一个汇集层。在这种情况下,使用平均集合法来获得得到晶体特征向量vg。

N是晶体图中的原子数
最后,vg被输入到全耦合层。我们现在训练系统使用非线性函数从vg中计算出目标变量(属性值)。
TL-CGCNN
在这项研究中,微调被作为一种方法来纳入通过预学习优化的参数。
顺便说一下,tanh标准化是为了使预训练任务和客观任务之间的客观变量(属性值)的标度一致。
关于数据集和训练
材料的晶体结构和相应的物理特性,如带隙能(Eg)和形成能(ΔEf),由材料项目数据库(MPD)提供,这是一个第一原理数据库。能源(ΔEf)数据。
(如果你有兴趣了解更多关于该研究的细节,请参考该论文)。)
结果和讨论
CGCNN和TL-CGCNN的比较
在下文中,该模型显示如下
例)500-NM-Eg:目标变量是带隙能(Eg),训练数据的数量是500,只使用非金属材料(NM)数据。
我们所处理的大多数材料都是无机的散装材料(不是纳米颗粒、薄膜等)。
下图显示了数据库中所有118286种物质的形成能(ΔEf)和带隙(Eg)的散点图。线性回归中的相关系数(rp)为-0.49,表明这些属性之间没有强烈的相关性。这些属性之间没有很强的关联性。
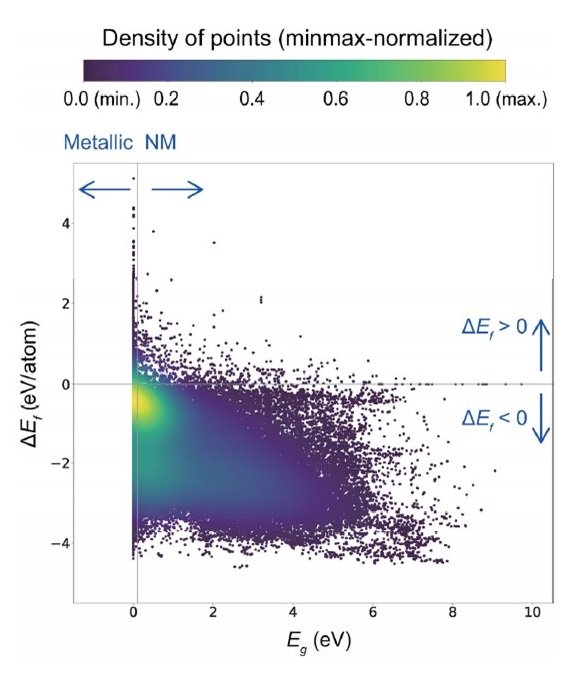
色标表示通过高斯核密度估计得到的相对密度。
下图显示了CGCNN中Eg和ΔEf各自预测任务的数据集大小和预测误差之间的相关性。
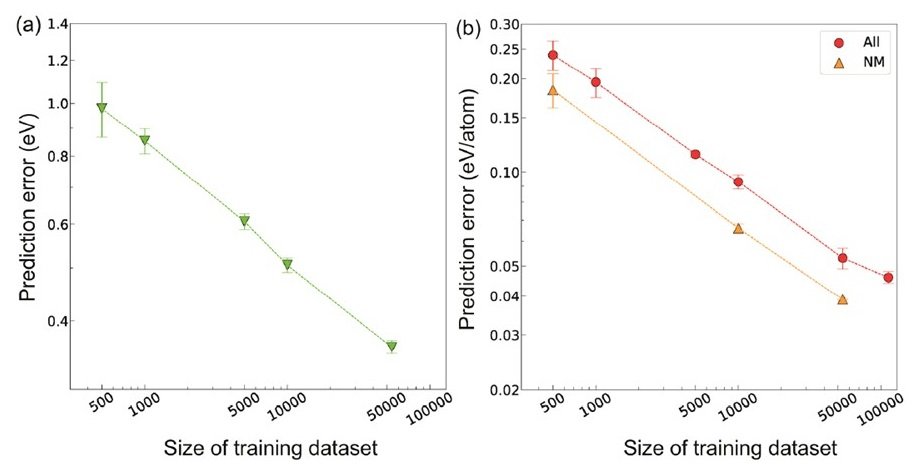
纵轴和横轴是log10轴。
随着数据集大小的增加,预测误差明显下降。发现在最大数据量时的预测误差值与与实验同时进行的第一原理计算(DFT计算)的数值误差相当。此外,由于组成元素和结合类型的不同,金属和非金属无机材料的晶体图预计会有很大不同。因此,我们将两类材料分开,只用非金属材料进行模型建立和预测,发现在相同的数据量条件下,两类材料分开后,预测误差明显降低。
在数据数量不足的情况下,接着是预测任务。下图比较了CGCNN和TL-CGCNN对非金属材料带隙(Eg)的预测性能。
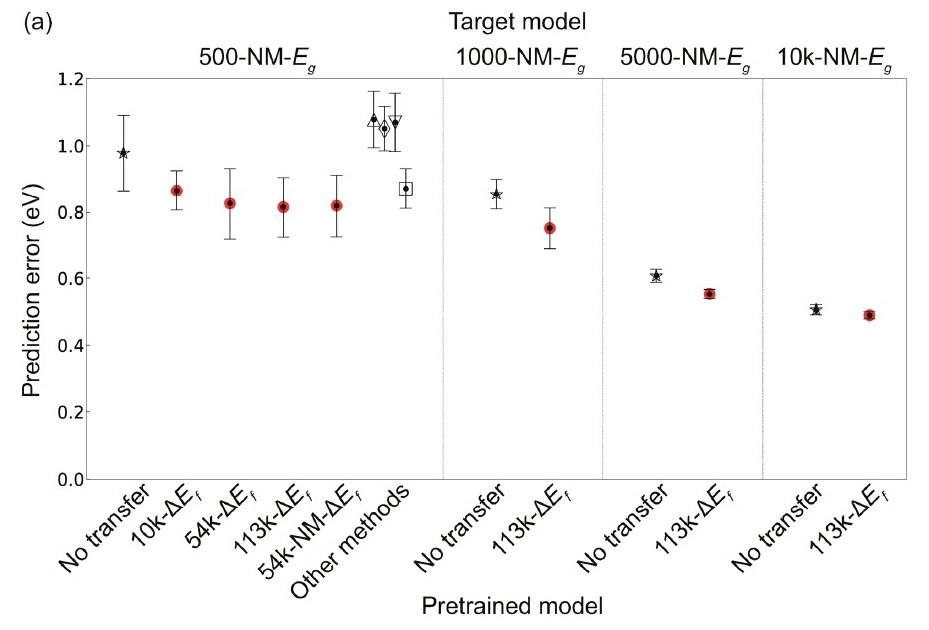
TL-CGCNN已经用每种大小的数据进行了预训练。△:pls, ▽:svr, ◇:lasso, ▢:rf
与仅有CGCNN的情况相比,应用过渡学习(TL)时的预测误差明显降低。对500-NM-Eg进行的1%显著性水平的相应t检验显示,用113k-ΔEf数据预训练的CGCNN和TL-CGCNN之间存在显著差异(113k-ΔEfTL-CGCNN),p = 6.9 × 10-5,证实了TL-CGCNN的预测性能有明显的提高。
下图(a)显示了CGCNN和TL-CGCNN在预测非金属材料的ΔEf方面的性能比较。
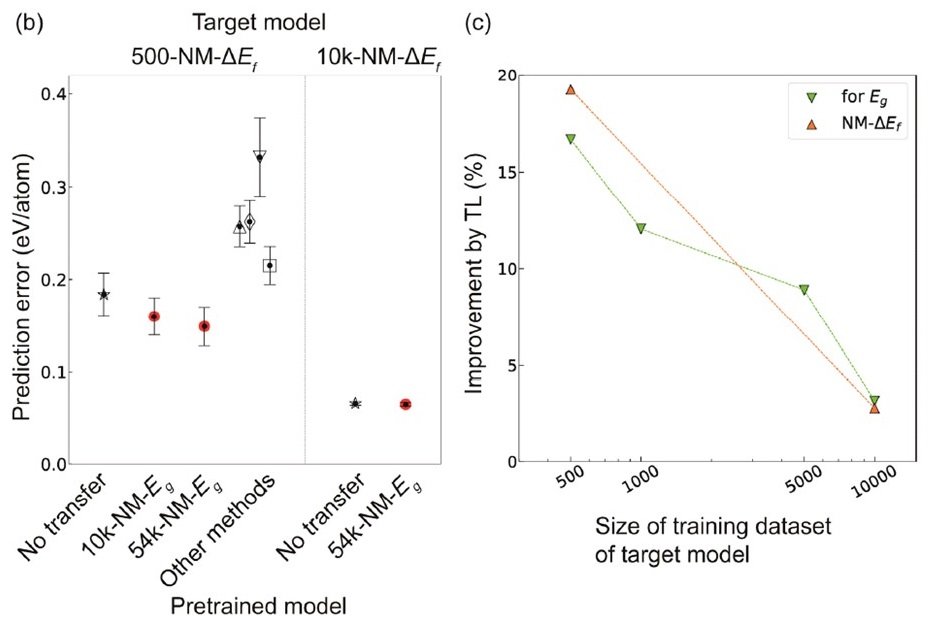
TL-CGCNN已经用每种大小的数据进行了预训练。△:PLS,▽:SVR,◇:LASSO,▢:RF,和
在TL-CGCNN中,只使用非金属材料数据进行预训练。在这里,使用TL-CGCNN也可以观察到预测误差的明显减少。
顺便提一下,在只用非金属物质数据进行预训练后,对含有金属物质的数据进行ΔEf预测时,没有发现明显的差异。这可能是由于金属材料和非金属材料的组成元素和结合状态非常不同,晶体图的结构也非常不同。换句话说,对于那些晶体图预计非常不同的材料类型,使用不同的模型可能更好。
上面的右图(c)显示了用于训练目标模型的数据量与使用TL时预测准确率的提高之间的关系。目标模型中的数据量越小,TL的功能就越强大。
使用TL-CGCNN来预测难以收集的财产数据
体积膨胀率(KVRH)、介电常数(εr)和准粒子带隙(GW-Eg)等物理性质的数值,通过计算科学获得的成本很高,与Eg等数据相比,积累的数据量非常小。用ΔEf和Eg进行预训练)来完成预测这些特性的任务,下面是对所得到的预测误差的比较。
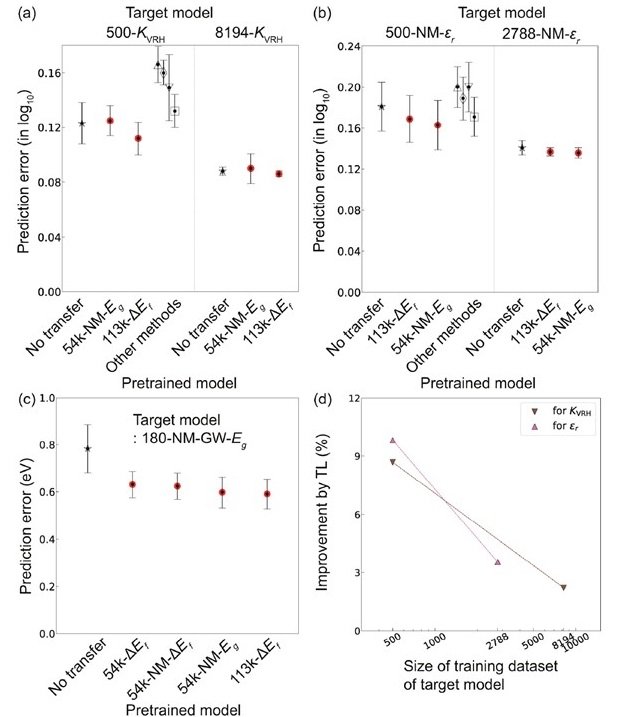
(a)体积膨胀(KVRH),(b)介电常数(εr)和(c)准粒子带隙(GW-Eg)的预测误差
对于所有的物理特性,TL-CGCNN显示出性能的改善。特别是,TL和CGCNN的联合使用提高了GW-EG对非金属材料的预测精度,最高可达24.5%。(看上图,看起来没有明显的差异,但由于纵轴是在对数10的尺度上,实际的差异要比看起来大得多)。 此外,目标模型的训练数据量越小,TL的改进率就越高。
顺便说一下,上述结果也显示了同一任务与知名模型PLS、SVR和RF的结果:与CGCNN的性能相比,只有RF在某些属性上优于CGCNN,即使只有500个数据点,但TL-CGCNN却没有。一个广泛使用的回归模型,如RF,在与目标变量强相关的描述符结合时表现良好,如本研究。然而,要选择一个对每个属性值都有效的描述符并不容易。
摘要
TL-CGCNN将晶体图描述符与过渡学习相结合,在只有少量数据的情况下,是一个强大而灵活的预测模型。晶体图描述符在过渡学习中表现良好,因为它们可以在大数据上进行预训练,以有效捕捉元素和晶体结构的特征。有了这些特点,TL-CGCNN模型有望在物理特性的数据收集方面发挥作用,而这是很难积累的。



与本文相关的类别
.jpg)



![[材料信息学]通过个体剩余学习成功地挖掘](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/June2021/individual_residual_learning-min-520x300.png)
