
使用图形和SMILES表示的逆向合成分析模型GTA。
三个要点
✔️目前最流行的反向合成任务的深度学习模型是基于序列到序列(seq2seq)和图神经网络(GNN),本文提出了图截断注意力(GTA),它将它们结合起来
✔️GTA将化学品表示为两种表征,一种是图形表征,一种是字符串表征,并使用这两种表征,用一种新颖的图截断注意方法进行逆向合成。
✔️该模型在USPTO-50k基准和USPTO-full数据集中取得了最先进的结果。
GTA: Graph Truncated Attention for Retrosynthesis
written by Seo, S.-W., Song, Y. Y., Yang, J. Y., Bae, S., Lee, H., Shin, J., Hwang, S. J., & Yang, E.
(Submitted on 18 May 2021)
Comments: AAAi2021
Subjects: Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍。
逆向合成(Retrosynthesis)是指通过寻找逆向反应途径,预测将被合成为特定产品分子的一组反应物分子的任务。这是有机化学中一项特别重要的任务,因为寻找合成途径和发现新化合物一样困难。自从逆向合成的概念出现以来,化学家们试图在逆向合成分析中使用计算机,以快速有效的方式寻找候选反应物。
近年来,由于深度学习在各种化学任务中的成功以及大型数据集的可用性,开始出现了利用深度学习以数据驱动的方式解决逆合成问题的研究。这种基于深度学习的方法有可能在没有人类干预或先前的知识或专长的情况下解决任务,并且可以成为一种时间和成本效益高的方法。最近基于深度学习的逆向合成方法可以分为基于模板的和无模板的。这里的模板是指一套描述反应物如何利用逐个原子的映射信息转化为产物的规则。自然,将模板转化为模型需要专业知识,这就是为什么今天最先进的基于模板的模型比无模板的模型显示出更高的性能。然而,不包括在提取的模板中的反应很少被基于模板的模型所预测,因此缺乏普遍性。另一个缺点是模板的实验验证需要大量的时间,例如7万个模板需要15年。无模板模型,直接从数据中学习,其优点是能够在提取的模板之外进行泛化,并且没有模板验证的问题。最早提出的无模板模型使用的是seq2seq模型,它从给定产品的字符串表示中预测出反应物的字符串表示;Seq2seq模型,如双向LSTM、多头自我关注和Transformer等。变压器等被用作Seq2seq模型。它仍在通过纳入学习率调度和增加潜在变量而得到改进。最近使用图表示的无模板模型被称为图到图(G2Gs),虽然G2Gs为美国专利商标局50k数据集报告了最先进的性能,但它仍然需要一些与基于模板的模型相同的程序,例如需要化学家标记的原子映射。与这些模型不同的是,GTA模型首次关注了图形和字符串表示法之间的二重性,并在没有向Transformer模型添加任何参数的情况下进行了反合成分析。
写在表面上的文字(如信封上的地址)
此后,$P$是生成的分子,$R$是反应的分子,$G(m)$是分子$m$的图形表示,$S(m)$是分子$m$的SMILES表示。 SMILES代表简化分子输入行系统,以字母序列表示分子。它被广泛用于分子特性预测、分子设计和反应预测。 例如,从呋喃和乙烯合成苯的反应如下图所示。
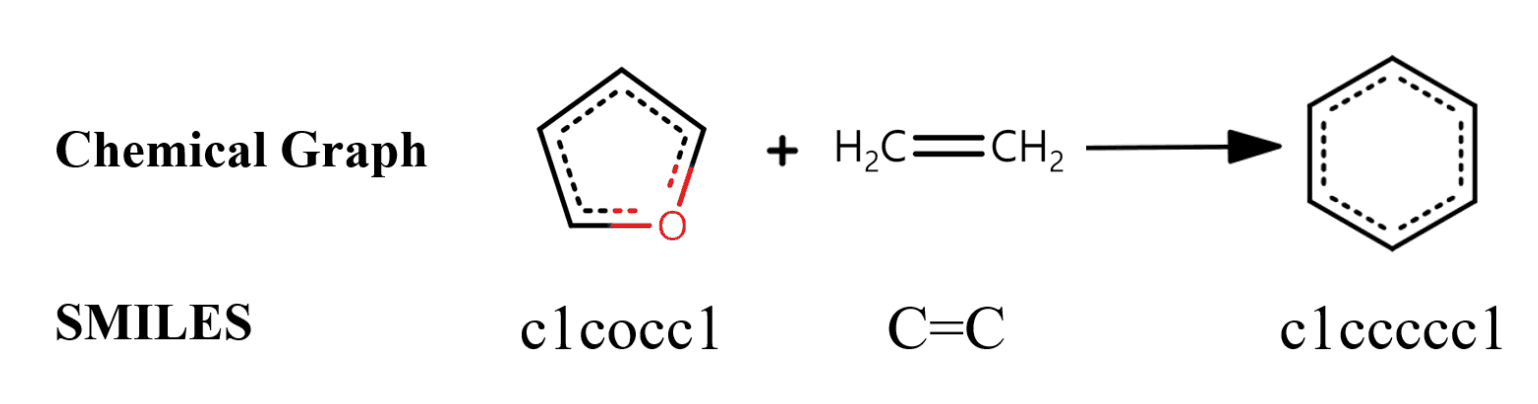
转换器
目前,Transformer是解决许多自然语言处理任务的事实,如机器翻译,因为该架构可以通过自我注意来学习标记的长距离依赖关系。在逆向合成任务中,分子转化器完成了将一组反应物$left\{R_1, R_2, \dots\right\}$转化为SMILES表示上的产物$P$的任务。转化器可表示为以下表达方式.
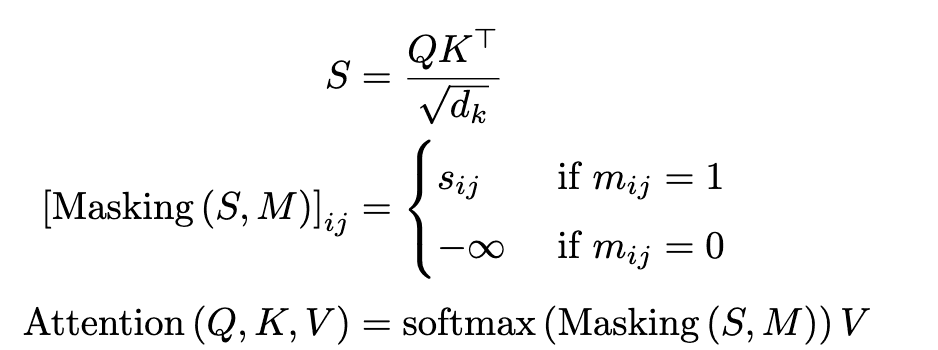
然而,$Q\in\inmathbb{R}^{T_m\times d_k}$、$K\in\inmathbb{R}^{T_m\times d_k}$和$V\in\inmathbb{R}^{T_m\times d_v}$是要学习的参数,$S=\left(s_{ij}\)右)$是得分矩阵,$M=\left(m_{ij}\right)\in\left\{0, 1right\}^{T_m\times T_m}$是掩码矩阵。屏蔽矩阵$M$是为每个注意力模块的目的而定制的。
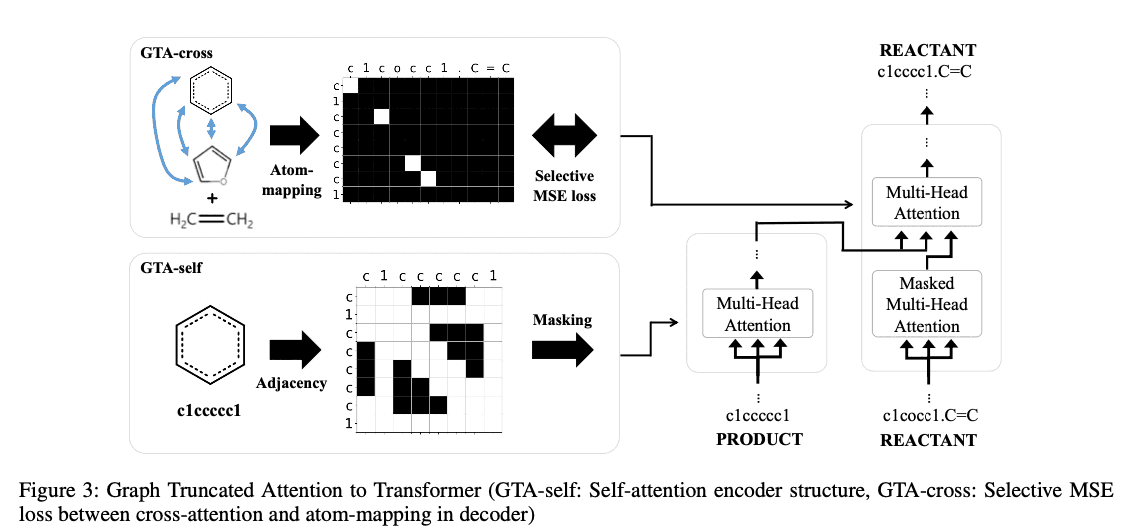
图形截断的注意力
GTA的目的是在Transformer的自我注意和交叉注意层中包括有关图结构的信息。受最近在预学习语言模型中使用掩码的成功启发,我们使用从图信息中生成的掩码来计算注意力机制;在GAT中,我们考虑两个掩码,一个在自我注意力层,一个在交叉注意力层。
图形截断的自我注意(GTA-self)。
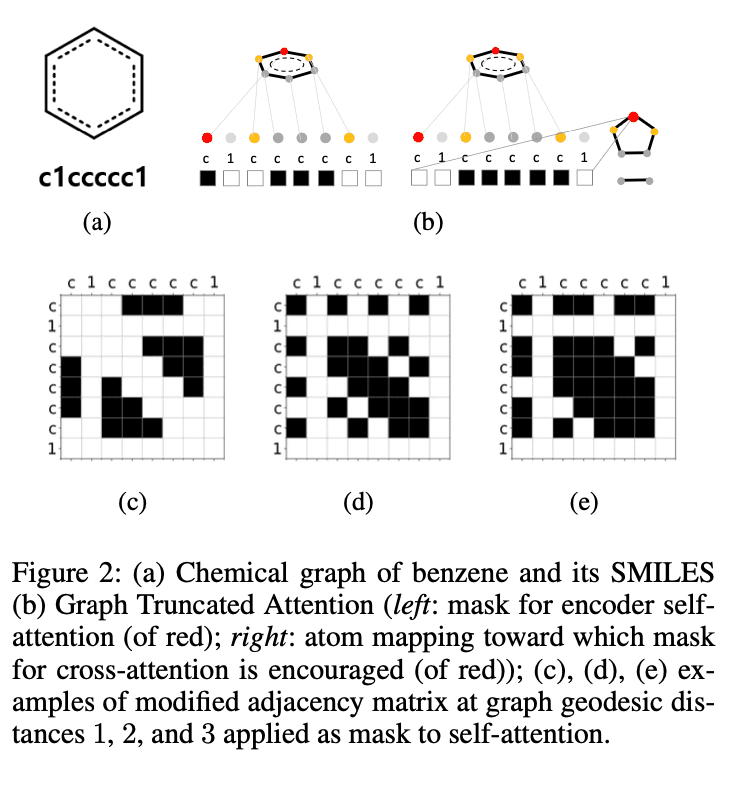
如果分子图上原子$i$和$j$之间的距离是$d$(或者原子$i$和$j$是$d$的跳邻),那么$m_{ij} = 1$。 D$是一个超参数,实验中使用了$D=1,2,3,4$。如果距离矩阵为$D=left(d_{ij}\right)$,那么对应于第h$个头的掩码为
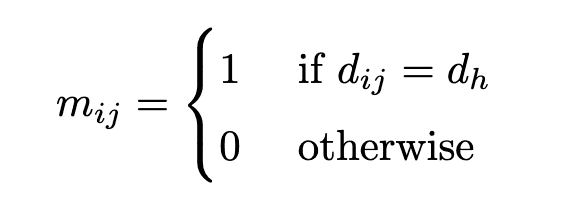
当所有的头都有$d_h=1$时,这与图形注意力网络(GAT)相同。当所有头部都有$d_h=1$时,与图形注意网络(GAT)中的情况相同。在我们的实验中,我们设置$d_h=\left(h\text{ mode }4\right)+1$使用头部索引$h$。作为一个例子,图2中(b)的左边显示了苯的红色原子的$d_h=1$的掩模。
图形截断的交叉注意力(GTA-交叉)。
反应不是一个完全分解分子以制造全新产品的过程,而且产品和反应物分子通常有一个相当共同的结构。因此,考虑交叉注意力层是一个自然的想法。然而,如何在产品和反应物之间映射原子并不容易,是化学领域一个活跃的研究课题。为了简单起见,本研究采用了标准Rkit中实现的FMCS算法:根据FMCS算法得到的产物和反应物分子之间的(部分)原子映射,掩码$M=left(m_{ij}\right)\in\left\{0,1\right\t_R}^{T_R}times T_P}$。
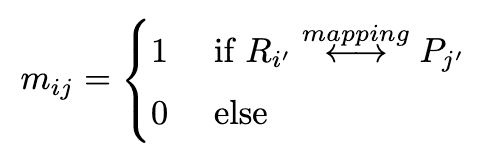
定义。其中$i'$是图形$G(m)$的顶点索引,对应于$S(m)$的第i$个标记,$R_{i'}$是图形$G(R)$的顶点,$P_{j'}$是图形$G(P)$的顶点。 如图3所示,交叉的如果相应的原子被原子映射所匹配,注意的掩码为1,否则为0。在这里,由上述方程产生的掩码很难找到映射,无论是在不完整的原子映射方面,还是在推理过程中生成序列时产生不完整的SMILES方面都是如此。因此,以下损失函数被用来逐步学习完整的原子映射。
$$mathcal{L}_{text {attn }==sum/left[left(M_{text {cross }}-A_{text {cross }}\right)^{2} odot M_{text {cross }}\right]$$
其中$M_{text {cross }$是上面定义的掩码矩阵,$A_{text {cross }$是交叉注意力矩阵。
损失函数
最后,总的GTA损失是$mathcal{L}_{text{total}=\mathcal{L}_{text{ce}}+alpha\mathcal{L}_{text{attn}}$,尽管似乎没有GTA-self的损失项。GTA-self的影响是隐含的,因为GTA-self产生的自我关注通过模型输出对交叉熵损失$mathcal{L}_{text\{ce}}$有贡献。在实验中,$alpha$被设定为1.0$。
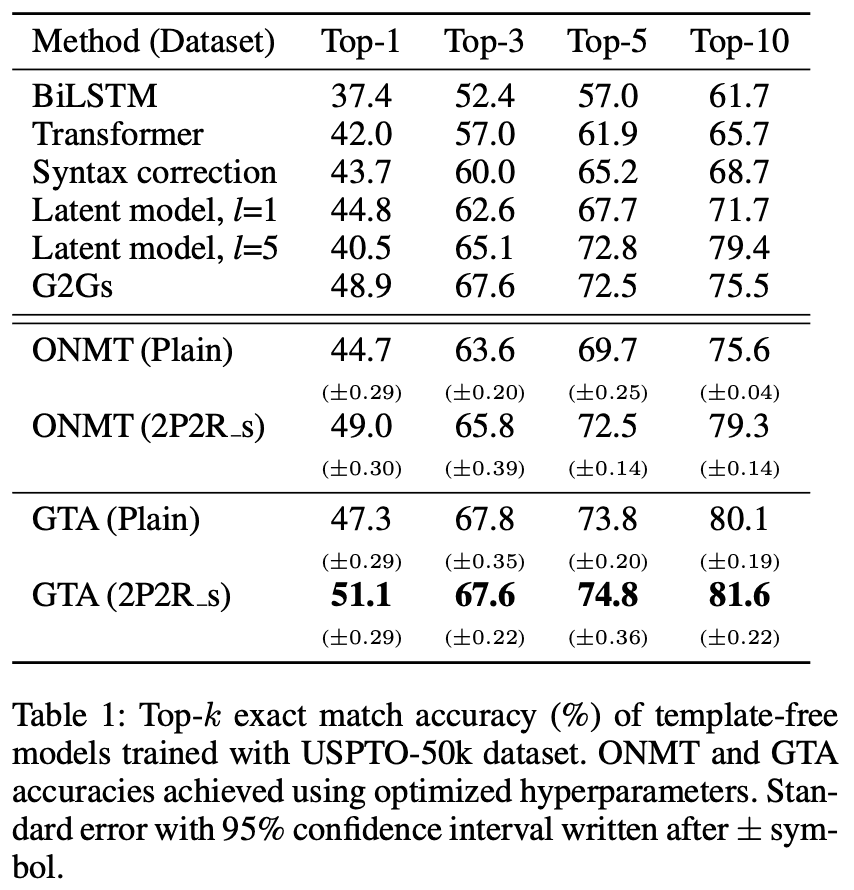
实验结果
实验是利用USPTO-50k和USPTO-full进行的,它们是化学反应的开放数据集。
表1与现有的无模板模型进行了比较,表2与现有的基于模板的模型进行了比较。这些数值是Top-k完全匹配的准确性(%),$pm$符号后面是95%的置信区间宽度。通过改变反应物顺序和起始原子进行数据扩展训练的情况写为2P2R_s。
该表显示,在UPSTO-50k数据集中,GTA在无模板模型中首次超过了50%的Tok-1准确率,在USPTO-full数据集中,GTA的Top-1和Top-10准确率分别超过了5.7 %和6.3 %。.
摘要
在这项研究中,提出了一种方法,通过结合分子特征作为SMILES和图形表示来解决逆向合成分析。结果显示,与无模板和基于模板的模型都有良好的比较。
本文证明了现有的Transformer模型可以通过加入一个考虑到图结构的掩码来提高性能。非常有趣的是,在没有任何额外参数的情况下,获得了最先进的结果,因为掩码被简单地纳入了。



与本文相关的类别


![[材料信息学]CGCNN-转移学习模型在](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/September2021/物性値のデータ不足に対応3-min-520x300.png)

![[材料信息学]通过个体剩余学习成功地挖掘](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/June2021/individual_residual_learning-min-520x300.png)
