人工智能治疗难治性疾病!使用强化学习来建议帕金森病的药物管理!
三个要点
✔️ 随着病情的发展,帕金森病的许多因素发生变化,导致药物管理的决策困难。
✔️ 提出了一个模型,利用强化学习并考虑到个人特点,将PD的运动症状降到最低。
✔️ 根据这一评估结果,预计引入RL将导致开发出能够加强帕金森病管理的模型。
Computational medication regimen for Parkinson’s disease using reinforcement learning
written by Yejin Kim, Jessika Suescun, Mya C. Schiess, Xiaoqian Jiang
(Submitted on 129 Apr 2021)
Comments: nature
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
背景
人工智能能否开发出比专家更有效的治疗策略?
在这项研究中,我们使用强化学习(RL)来研究帕金森病(PD)这种难治的疾病。- 提出了一个学习模型,旨在最大限度地减少运动症状在
PD是一种迅速增加的神经退行性疾病类型,患者人数和经济成本持续上升。虽然用多巴胺替代物进行姑息治疗是治疗的主流,但随着疾病的发展,许多因素发生变化,使得药物治疗变得困难。此外,虽然已经提出了治疗指南,但干预措施需要考虑个体特征,决策时需要考虑大量的因素--在实际的临床实践中,治疗应该从小剂量的单药开始,根据病人的反应和病情,可能需要调整剂量和增加辅助治疗。以下是研究结果的摘要。这一过程需要考虑到PD的运动症状,并确定适当的药物组合以改善生活质量;这些决定需要考虑到许多因素并具有灵活性--例如根据患者的病情进行适应性改变。人类辅助决策是困难的。这项研究的目的是利用RL得出稳健和最佳的药物组合,考虑到每个PD的个体特征--病理生理学。
什么是帕金森病 - 帕金森病:PD?
首先,简要介绍一下帕金森病--帕金森病:PD--是本研究的分析对象。
帕金森病--PD--是一种神经退行性疾病--一种指定的不治之症--近年来迅速增加,是由大脑中的异常导致身体运动受损引起的。主要症状是运动障碍--震颤:颤抖,动作缓慢,肌肉僵硬:肌肉僵硬,姿势保持障碍:容易摔倒,等等。非运动症状还可能包括:便秘;尿频;出汗;容易疲劳--疲倦;嗅觉减退;直立性低血压--头晕;感觉不舒服。-抑郁症 -;失去兴趣和动力 预计到2040年全世界将有1750万人受PD影响,自1990年以来患病率增加了74.3%,在美国每年的经济负担估计为520亿美元。药物治疗是PD的主要治疗策略--随着多巴胺神经元的减少,治疗会取代减少的多巴胺并缓解症状;而包括药物治疗在内的药物管理则取决于各种因素,包括个体因素,如疾病的发展。决策的难度是一个挑战,因为
研究目标
这项研究旨在利用强化学习--强化学习(RL)--来实现最佳的治疗策略,以最大限度地减少PD的运动症状。
如上所述,PD需要一个考虑到个人因素的治疗政策,这是一个复杂和巨大的交织因素,使得人类在某些方面难以做出决策。因此,本研究旨在利用RL得出一个考虑到个体特征的最佳治疗政策。2 当考虑在临床实践中使用RL模型时,可以考虑两个问题--可解释性和稳健性:模型对现场医生的指导是否清晰各项研究的推导政策的一致性--稳健性--和可解释性--的重要性。因此,本研究旨在通过利用决策树回归的可解释性和集合学习的稳健性来提高临床实用性。
技术
本章对所提出的方法进行了概述。所提出的方法使用帕金森病进展标志物倡议--PPMI--数据库,这是一个纵向观察的帕金森病患者队列,并基于马尔可夫模型。决策过程:使用MDP-环境构建和迭代学习来得出临床相关条件和最佳药物组合。八种药物组合--多巴胺受体激动剂左旋多巴和其他PD药物--被用作代理选择,统一帕金森病评分表-基于UPDRS-III的分数作为奖励和惩罚。
数据集
本节提供了一个数据集的概述,该数据集被用于提出的方法。
该研究利用PPMI作为后向队列研究;PPMI是2010年启动的观察性研究,包括Hoehn和Yahr阶段、UPDRS III和其他临床评估以及药物治疗--左旋多巴、多巴胺激动剂和其他PD药物。- 正在收集。该分析包括431名早期PD患者,随访55.5个月,共5077次;没有UPDRS III评分或用药记录的患者被排除。大多数病例还接受了左旋多巴、多巴胺激动剂和其他PD药物--MAO-B抑制剂、COMT抑制剂、金刚烷胺和抗胆碱能药物的联合治疗。计算了III期总分的百分比变化。
马尔科夫决策过程的使用 - 马尔科夫决策过程:MDP-。
本章介绍了MDP在所提方法中的应用,。
药物管理包括三个部分--目前的医疗状况、药物选择和UPDRS III总分--临床医生根据目前的医疗状况决定药物的组合--这种组合影响运动症状和并可被解释为改变当前医疗状况的。该模型的目的是根据这些组合选择最佳的药物治疗,并使UPDRS III的总分最小化。
在这项研究中,治疗方法是用马尔科夫决策过程--马尔科夫决策过程:MDP--来模拟的,在这个过程中,代理人选择行动来使估计的奖励最大化。-代理人探索大量的行为,并选择最合适的行为,使累积奖励最大化。每个元素的配置如下:。
(1) 状态𝑠:当前访问时的疾病状态行动
(2) 行为𝑎:治疗药物左旋多巴和其他PD药物的8种组合
(3) 奖励/惩罚 𝑟(𝑠,𝑎,𝑠'):病人对药物治疗的反应:具体而言,UPDRS III的累积分数和行为处于𝑎的药品数量乘以一个加权常数𝑐。
在制定方案时,利用了决策树回归,并利用几个因素--PD亚型、Hoehn和Yahr分期、发病时的年龄、UPDRS III总分和变化率等--来定义疾病状态。这些状态之间的过渡概率是通过计算在PPMI轨迹中观察到的每个过渡并除以过渡总数来计算的。在学习方面,利用了TD学习来建立RL模型。
关于治疗政策的合奏。
本章介绍了集合学习,它提高了处理政策的稳健性--或称鲁棒性。
RL提出的集合方法被用来提高治疗政策的稳健性--跨研究的一致性。程序如下:将数据集分为80%的训练和20%的测试;从RL和临床医生的训练中得出治疗策略,并,.在测试集上评估这些估计的奖励--或惩罚--;对训练和测试随机重新取样500次,计算估计奖励的分布(见下文)。然后,在500次引导后,通过多数投票选出最佳治疗策略。
结果。
在本节中,描述了针对RL模型得出的处理策略的评估结果。
首先,使用多变量回归模型,临床终点--疾病状态--和药物--作用--被用来确定UPDRS III得分--惩罚--的对预测的统计意义(见下表)。

然后用具有统计学意义的变量和决策树回归模型对UPDRS III总分进行回归,得出相关的病情。疾病状态为运动性僵硬、震颤为主和混合型,相应的分数为21、4和3。在本研究中,疾病状态是由UPDRS III总分和变化--以前和现在的分数之间的差异值--以及年龄来定义的。其他变量--如认知评分和Hoehn和Yahr阶段--没有被用来定义病情,因为它们在统计学上有意义,而在决策树回归中的意义却很低。
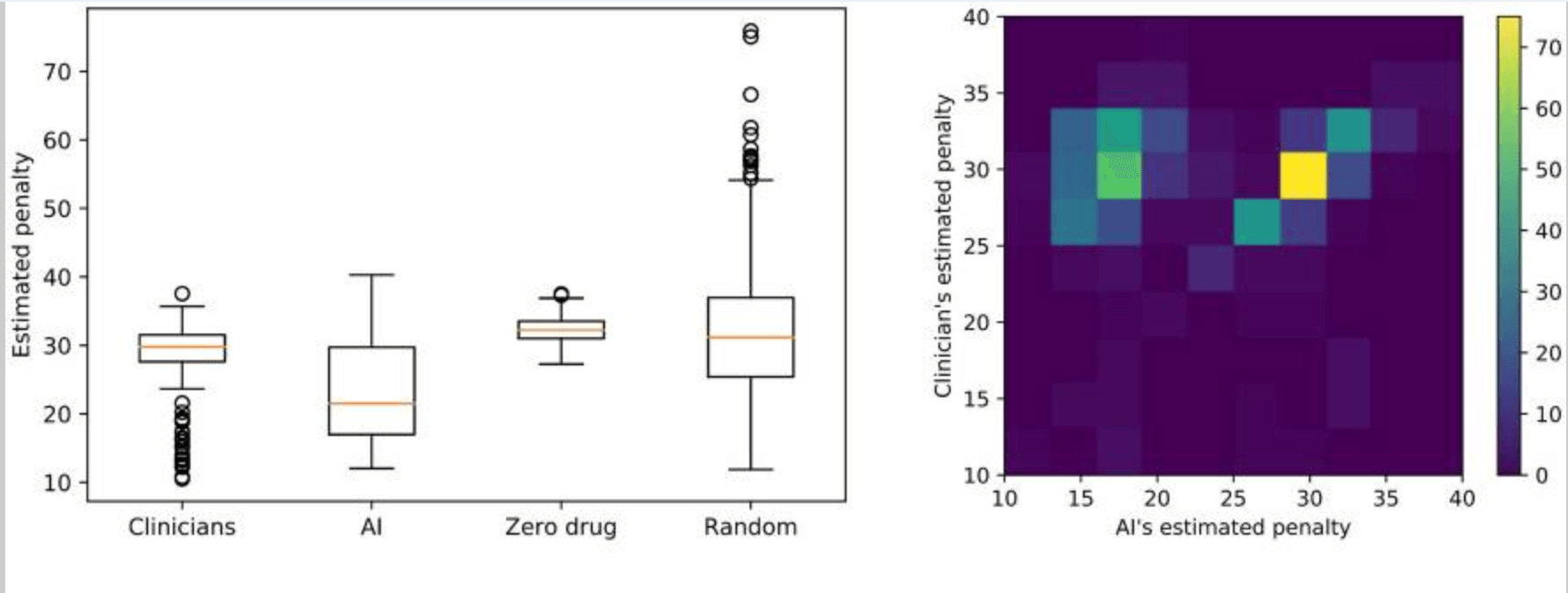
RL模型从疾病状态中得出了使惩罚中值最小化的最佳行为--UPDRS累积得分(见下图)。
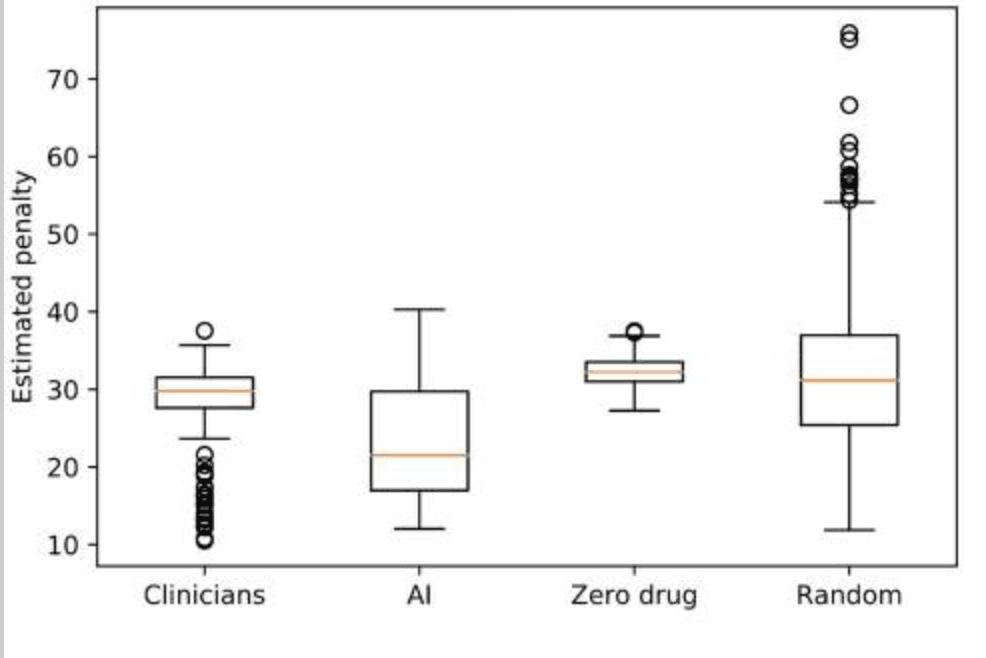
临床医生的惩罚值中位数为29.8,人工智能为21.5,范围和变数如下:临床医生:最小=10.5,最大=37.6,变数=16.1;RL:最小=12.0,最大=40.3,变数=47.4。 这些结果表明,拟议的药物治疗模式该政策不稳定,但处罚较低--运动症状较少;而临床医生的用药政策比较稳定,但处罚较高--运动症状较多。其结果是。当使用相同的训练/测试集比较RL和临床医生的罚分分布时,RL的罚分较小或与临床医生的罚分相似。此外,从临床医生和提议的模型中得出的用药政策取得的惩罚明显低于零或随机政策--t值=-16.7,p值=1e-55:临床医生与零药物,t值=-6.2,p值=1e-10:临床医生与随机药物
此外,虽然临床医生的治疗政策和RL的建议行动(见下文)基本上是相同的政策,但RL模型一起提出了具体的病理变化--在28种情况中的16种,RL提出了与临床医生相同的行动,在12种情况中则不同:例如,在在条件1中,是运动性僵硬PD的早期阶段,UPDRS III累积评分为9-11分,临床医生开出多巴胺激动剂,而RL模型则建议暂停用药。在条件9--一种较轻的刚性运动性PD--UPDRS III总分20-24分,年龄<65岁,临床医生开出左旋多巴和多巴胺激动剂,而AI模型建议只服用多巴胺激动剂。
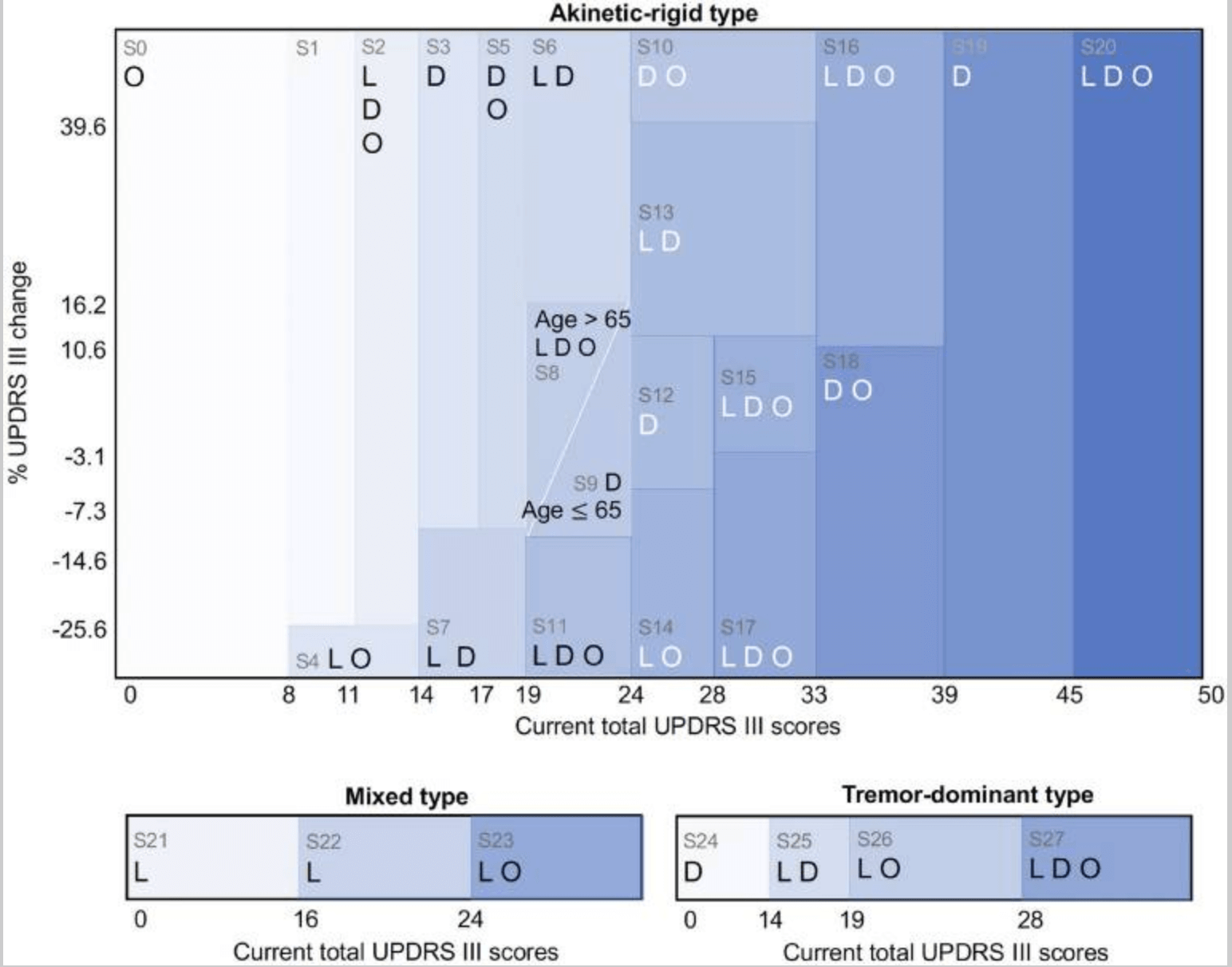
考虑
这项研究利用RL建立了一个模型,用于推导出针对PD疾病运动症状的稳健的最佳药物组合。在建立该模型时,一个PD患者的观察性纵向队列--PPMI--被用来通过迭代马尔可夫决策过程为每个条件提出最佳药物组合。作为衍生组合的结果,拟议的模型输出的药物疗法与临床医生的性能相当,并达到比临床医生更低的运动症状严重程度得分水平;而临床医生的治疗策略比拟议的模型更一致。建议的模式是基于临床医生的治疗计划,但提出了几个变化,这导致了减少严重程度的差异。
所提议的模型的优点之一是它可以在门诊环境中使用:它利用了严重程度的符号,并且易于解释。此外,通过使用PD亚型作为初始节点,病理定义是基于临床医生的经验;因此,本研究中定义的病理很可能具有临床可解释性。
另一方面,也设想了一些挑战,包括:拟议模型的一致性差;UPDRS分数不一致。虽然提议的模型显示出更高的性能--较低的UPDRS分数--但它导致估计的惩罚有更大的变异性--在不同的试验中不如临床医生的用药指南一致。这些被认为是由于在行为空间的试错探索--每个条件下的药物组合。解决方案包括提高集合学习的准确性--随机森林、梯度提升--以及通过将RL与医生的治疗计划相结合来实现互补。在某些情况下,UPDRS的负变化率显示与正常的疾病进展不一致;可能的原因包括所分析的数据集的队列规模小和UPDRS III评分的不一致。作为一种解决方案,目前正在考虑采用这种分数以外的方法来评估运动功能。



与本文相关的类别
![[DrHouse]利用传感器信息和专业知](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/February2025/drhouse-520x300.png)
![[SA-FedLoRA] 降低联合学习通](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/October2024/sa-fedlora-520x300.png)


![[SpliceBERT]使用生物物种遗传](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/July2024/splicebert-520x300.png)
![[IGModel]提高基于 GNN+At](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/July2024/igmodel-520x300.png)