帧插值×MAML:基于MAML的帧插值模型的元学习。
3个要点
✔️应用MAML框架进行帧插值,快速响应新场景
✔️提出新的MAML发现,改变Innerloop和Outerloop的数据分布。
✔️在各种帧插值模型中,以较轻的计算工作量,比基线提高了PSNR值。
Scene-Adaptive Video Frame Interpolation via Meta-Learning
written by Myungsub Choi, Janghoon Choi, Sungyong Baik, Tae Hyun Kim, Kyoung Mu Lee
(Submitted on 2 Apr 2020)
Comments: Accepted to CVPR2020.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:
首先
帧插值是一种使图像看起来平滑的技术。通过在帧间插值,可以使波浪形的图像变得平滑。在实际应用中,计算机由上一图像和下一图像柔和地创建一个连续的中间图像。在将低帧视频转换为高帧视频时,基本以帧插值为核心。这样的帧插值是历史悠久的CV领域之一,但现在普遍采用CNN计算中间图像。在NVIDIA研究人员发布的SuperSloMo出现之前,通常是将两张图像输入模型,输出一张中间图像。然而,自从SuperSloMo出现后,输出多个任意中间图像的模型被开发出来。
然而,现有的高精度帧插值模型非常庞大,在训练新的任务数据时需要额外的计算时间。此外,微调等解决这一问题的方法研究得不多。
在"Scene-Adaptive Video Frame Interpolation via Meta-Learning"中,提出了一种帧插值模型的元学习方法。在本文中,作者提出了一种帧插值模型的元学习方法,将最近在元学习界备受关注的MAML框架应用于帧插值。本文将对本文进行详细讨论。(注意,本文中的图片取自MAML的MAML论文。所有其他图片均来自SAVFI文件)
关于MAML
MAML(Model-Agnostic Meta-Learning)是一种独立于模型的元学习技术。具体来说,MAML是一种由内循环和外循环组成的参数更新技术,使模型适应新的任务。之后,实际的参数更新是由外循环来完成的。
内环
假设一个模型是$f_\theta$($\theta$是一个学习参数),$T_{i}$是一个新的学习任务。让$\alpha$是学习率。然后每项任务的内环计算公式如下并通过更新每个任务的梯度参数,得出$\theta'_{i}$。这不仅可以通过更新一次,也可以通过更新任意次数来实现。
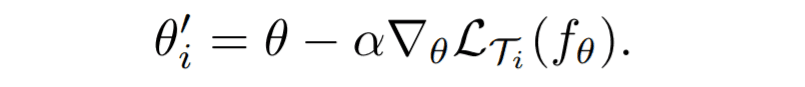
外环
然后,在Outer循环中,对于在Inner循环中已经更新了任意次数的模型,在Outer循环中对每个任务的梯度进行汇总和更新。如果$\beta$是外环的学习率,那么它的定义如下。
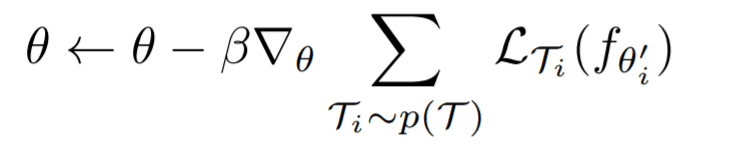
对于损失,我们取内环中每个任务更新的损失,但更新本身使用的是内环更新前的$\theta$,而不是$\theta'_i$。这是MAML的基本思想,但具体的数学细节请参考MAML论文。上述MAML表明,它可以应用于独立于模型的各种任务。
架构
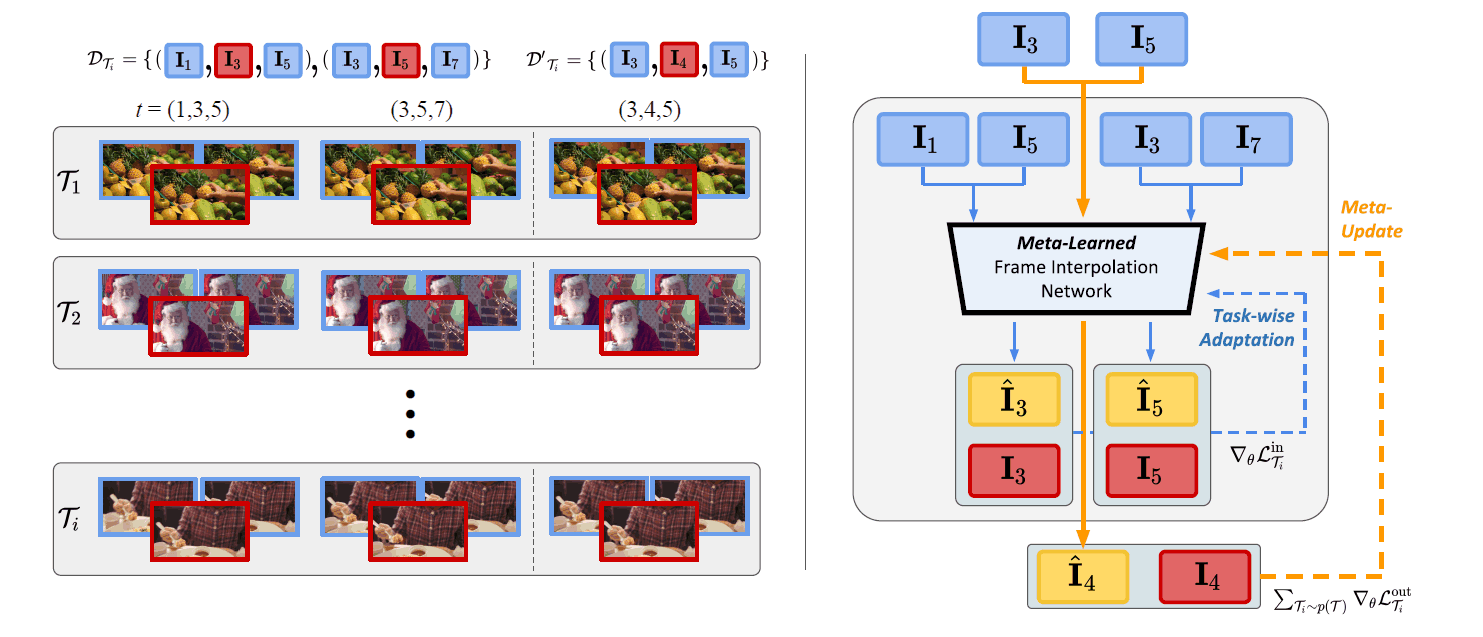
在SAVFI论文中,我们将MAML框架应用于帧插值。具体框架如上图所示。新任务的视频被定义为$T_i$。从每个视频中采样的帧县定义为$D_{T_{i}}I$, $D'_{T_{i}}I$。分别是。前者是更新内循环的数据,后者是更新外循环的数据。在原文中,与传统MAML的区别如下所示。
Note that, the biggest difference from our algorithm from the original MAML is that the distributions for the taskwise training and test set, $D_{T_{i}}$ and $D_{T_{i}}$, are not the same. Namely, $D_{T_{i}}$ have a broader spectrum of motion and includes $D_{T_{i}}$ , since the time gap between the frame triplets are twice as large.
("Scene-Adaptive Video Frame Interpolation via Meta-Learning", p6)
换句话说,内循环和外循环中对不同帧间隔的数据的处理是一个尚未探索的领域。
MAML x Frame Interpolation
在框架的右图中,详细描述了更新过程的流程。首先,在内部循环中将$D_{T_{i}}I$输入到帧插值模型$f_{\theta}$中,就可以得到以下插值图像$\hat{I}_{3}$。$\hat{I}_{5}$。元的生成方式如下:然后,内循环计算每个任务的插值图像和GT之间的损失。
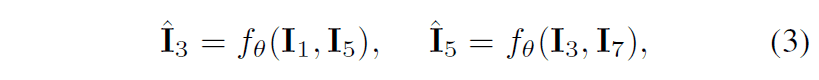
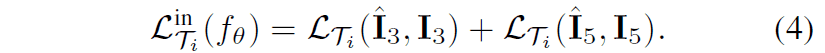
在上述Innerloop中更新模型后,与传统的MAML一样,计算在Innerloop中更新的模型在Outerloop中的每个任务的损失。此外,外环中用于评估的视频是帧间隔接近的视频外环中用于评估的视频是$D'_{T_{i}}I$,帧间隔很近。
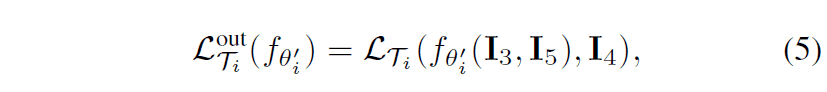
下图是根据以上两种内损和外损编写的伪代码。可以看到,上述损失应用于MAML框架,参数更新。

实验结果
本文以DVF、SuperSloMo、SepConv和DAIN四种模型为基线,进行元学习的实验。作为元学习的训练数据,使用了VimeoSeptuplet的track-split。评估时,采用VimeoSeptuplet和Middlebury-others、HD的测试分。此外,像SuperSLoMo这样具有任意插值次数的模型,为了将其放入框架中,也用一种插值方式进行测试。具体来说,进行以下三个实验。
- 用Meta学习法对现有的框架插值模型进行量化结果分析。
- 每个数据集的帧插值的定性结果。
- 对InnerLoop的梯度更新和学习率的消融结果。
用Meta学习法对现有的框架插值模型进行量化结果分析。
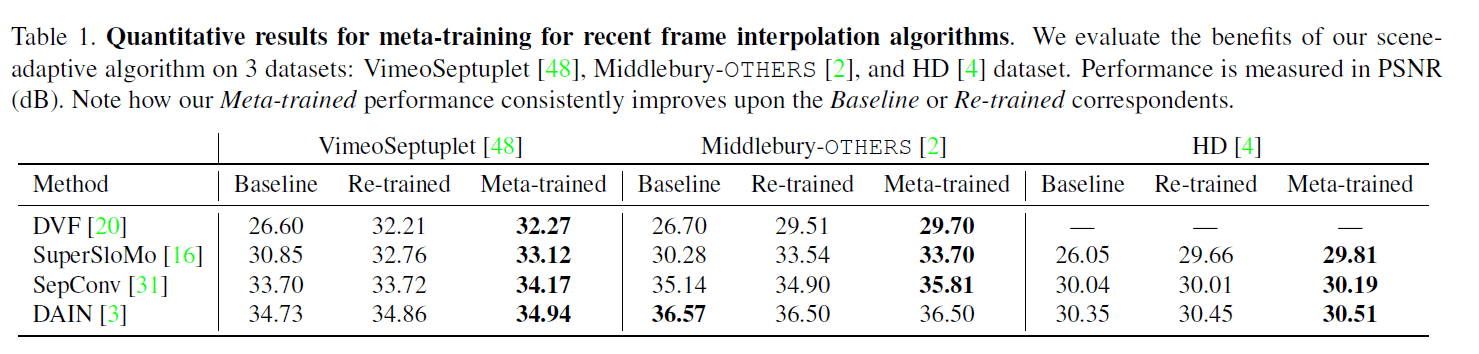
表中的分数是图像之间的PSNR,数值越高一般意味着图像之间的距离越近。重新训练只是使用VimeoSeptuplet的train-split进行微调的结果。从加粗的区域来看,我们可以看到每个模型的性能与VimeoSeptuplet的测试分拆相比都有所提高。也可以证实,Metalearning对其他数据集上的大部分模型都是有效的。
每个数据集的帧插值的定性结果。

定性结果如下图所示。每行的插值结果通过Meta学习插值后的图像比其他行更清晰,更接近于Ground Truth。尤其是SepConv的效果非常显著,可以确认是减少了模糊。关于SepConv的更多信息,请参见关于高清数据集的其他详细结果结果还表明可以证实,插值图像的清晰度得到了提高。原因是,在该文件中SepConv的这可能是由于SepConv没有光流经转换机制。
对InnerLoop的梯度更新和学习率的消融结果。
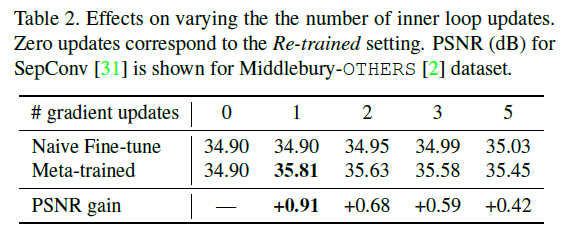
这是对元学习Innerloop的消融,有多次更新,即单次更新的PSNR得分最高。这与传统的MAML的结果不同,文中提到Inner loop的多次更新有可能使每个任务过度学习,而且学习可能变得更加复杂。
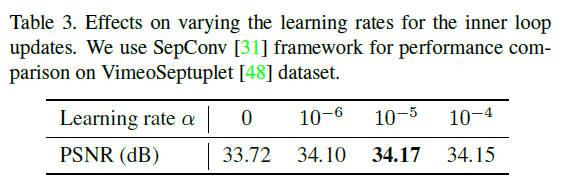
这是改变Innerloop的学习率时的结果。我们可以确认,通过启发式调整学习率到最佳值,就像上面的更新次数一样,既不能太高,也不能太低,就能获得最好的精度。
摘要
在本文中,我们看了一篇将框架插值任务应用到MAML框架中的文章,不仅展示了MAML的通用性,而且通过使用预先训练好的模型和任务中抽样数据的性质,探索了MAML的新可能性。文章作者认为,使用预先训练的模型和任务中抽样数据的性质导致了对MAML新可能性的探索。在传统的插值模型中,人们往往只关注应该计算什么样的流量,并从中推导出什么样的网络,但本文的出现给人的感觉是给框架插值领域带来了新的观点。



与本文相关的类别

