使用遗传算法的基于块的CNN架构搜索方法。
三个要点
✔️ 设计CNN架构需要大量的领域知识和计算资源
✔️ 建议在节省计算资源的同时,对CNN架构进行基于块的自动探索
✔️ 在错误率和所需计算资源量方面,将所提方法探索的模型与人类手工设计的模型和最近的建筑自动搜索算法探索的模型进行比较。
A Self-Adaptive Mutation Neural Architecture Search Algorithm Based on Blocks
written by (Submitted on 21 July 2021)
Comments: IEEE Computational Intelligence Magazine.
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
CNN是人工智能领域的一个非常成功的模型。然而,他们的设计并不容易。这是因为CNN的架构对其性能有很大影响,但探索其架构需要大量的领域知识和计算资源。一种不需要领域知识就能探索神经网络结构的方法被称为神经结构搜索(NAS),它是近年来许多研究的主题。研究已成为近年来的一个主要议题。
在本文中,为了节省计算资源,架构以块为单位进行探讨,这在一定程度上将CNN的结构组合在一起。此外,大多数NAS方法使用强化学习进行搜索,但为了节省计算资源,采用了具有独特扭曲的遗传算法来进行搜索。
实验比较了三种类型的模型:由提出的方法探索的模型、由人类手工设计的模型和由最近的建筑自动探索算法探索的模型。在比较中,我们不是简单地比较错误率,而是比较探索模型所花费的计算资源和模型的大小(参数的数量)。
相关工作
本研究中使用了遗传算法。遗传算法的基本流程如下。
- 在当前一代中随机生成N个个体
- 评价函数,分别计算出当前一代中每个个体的适应程度(表现)。
- 以一定的概率执行以下三个动作之一,并将结果存储在下一代中
- 选择两个个体,并使其交叉受精
- 选择一个个体进行突变。
- 选择一个个体并按原样复制。
- 重复上述操作,直到下一代的个体数量为N。
- 当下一代单元的数量达到N时,下一代的所有内容都被转移到当前一代。
- 从第2代开始重复操作,进行最大数量的代数,并输出最后一代中具有最高适配度的个体作为解决方案。
这项研究采用了独特的突变方法和独特的交叉方法。
建议的方法(SaMuNet)。
下文将详细介绍本研究中提出的 "自适应突变网络(SaMuNet)"。
SaMuNet基本流程。
SaMuNet的基本流程类似于基本的遗传算法,如下所示。
- 在当前一代中随机生成N个个体
- 通过评价函数计算出适应程度。
- 在比赛选择中选择家长
- 通过杂交和突变产生子代
- 重复3~4,直到有N个孩子。
- 更新这一代的变异概率(自适应变异)。
- 让这一代人成为父母的一代。
- 重复2~7,直到最大的世代数。
- 解码最终解决方案并获得CNN
编码策略
在遗传算法中,每个个体由一个基因代表。将要搜索的目标转换为基因的操作称为编码,而编码的方法非常重要。
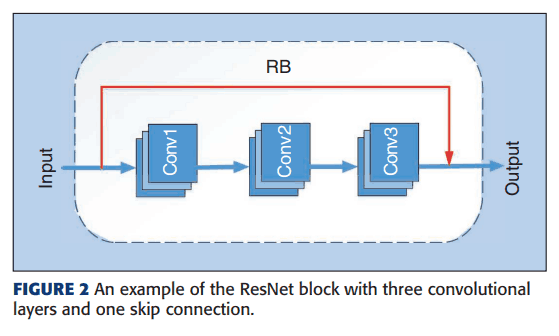
首先,为了表示CNN的结构,一些块被视为块。例如,一个ResNet块(RB)可能看起来像这样
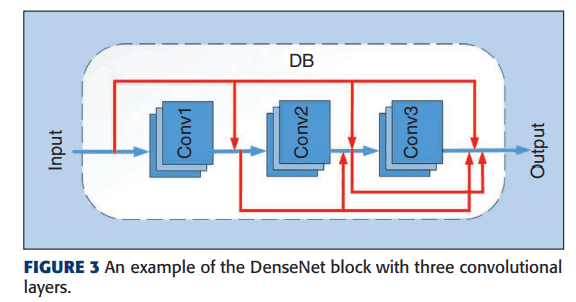
另一个例子是DenseNet块(DB);DB是一个块,它可以
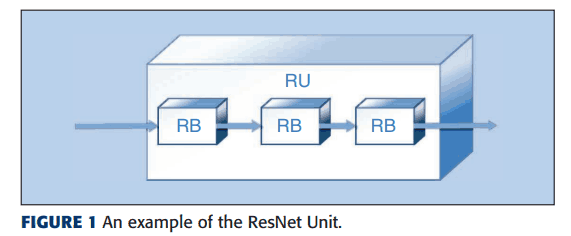
这些块的某种组合被称为单元,并被视为基本单元。其中一个单元,即RU,可以是
在本研究中,此类单元被用作代表CNN架构的基本单元。有三种类型的单位
- 资源网单元(RU)
- 密网单位(DU)
- 联营单位(PU)
资源网单元(RU)
ResNet块(RB)的数量是用随机数确定的。每个RB还包含至少一个3*3卷积核。如图1所示,这些RB被连接并组合在一起,称为ResNet单元。
密网单位(DU)
DenseNet区块(DBs)的数量是用随机数确定的。每个数据库还包含至少一个3*3卷积核。如图1所示,这些数据库被连接并组合在一起,被称为DenseNet单元;与ResNet单元的区别在于是否有跳转连接;RU有跳转连接,而DU没有。
联营单位(PU)
只包含一个类型的集合层,即平均集合层或最大集合层。
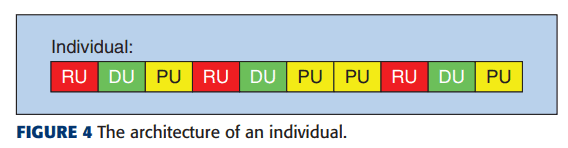
基因的例子
上述基本单元(单位)的序列被视为个体,遗传算法的执行方式如下。
第一代的初始化
上图所示的基因最初是用随机数初始化的。每个个体的长度由一个随机数决定,每个单元的位置也用另一个随机数决定。然而,禁止将PU放在第一位,因为如果个人从PU开始,他们会突然放弃输入中的许多信息。另外,如果PU不断地来,这时的输出大小将是1*1,所以为它们不断来的次数设置了一个阈值,以避免这种情况。
对每个人的评估方法
在提议的方法中,每个个体都被解码成一个CNN架构,在训练和验证数据上进行训练和测试。测试分数被用作个人的适应程度。
过境方法
建议的方法使用二进制策略来选择父母。在这种方法中,首先从种群中随机选择两个个体,然后选择具有最高适配度的个体作为父本进行交叉。为了增加每个人的灵活性,使用可变长度的编码来代替固定长度的编码。这意味着,CNN架构的深度是可变的。使用单点交叉法进行交叉,具体方法如下。
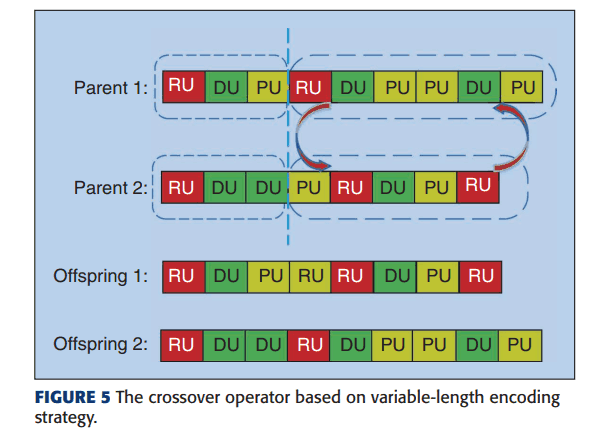
穿越后,调整输入通道的数量并改变单位编号。
突变的方法(自适应机制)
在所提出的方法中,在一般遗传算法的变异部分增加了一个装置。本节介绍了这些创新。
有三种类型的突变:加法、删除和替换,这三种中的任何一种都可以作为突变操作来执行。增加是指在个体的选定位置增加一个单元,删除是指在个体的指定位置删除一个单元,替换是指在个体的选定位置随机替换一个单元。
所提出的方法从这三种变异操作中选择一个好的,并执行它。具体来说,突变操作最初在三者中选择的概率相同,但每次突变后性能超过其父母的个体比例被用来改变下一代中突变操作的选择概率。概率的改变使表现优于父方的操作更有可能被选中。
选择下一代
在所提出的方法中,下一代的选择也是以一般的遗传算法来设计的。一般来说,在使用二分法策略时,将随机选择的两个个体对立起来,将表现较好的个体留给下一代。这种方法的问题在于,如果将表现较好的那一个与表现较差的那一个相比较,表现较好的那一个就不能留在下一代,或者将表现较差的那一个与表现较好的那一个相比较,表现较差的那一个就能留在下一代中。
为了解决这个问题,所提出的方法生成一个随机数,并将该数字的顶级适应个体留给下一代。然后用二分法确定剩余个体的下一代。这样一来,二分法的问题就解决了。
实验
本文使用分类错误率、参数数量(即模型的大小)和运行该算法所需的计算资源(GPU/天)来评估该算法的性能。
所提方法探索的模型的性能。
CIFAR 10和CIFAR 100中不同方法的比较如下。
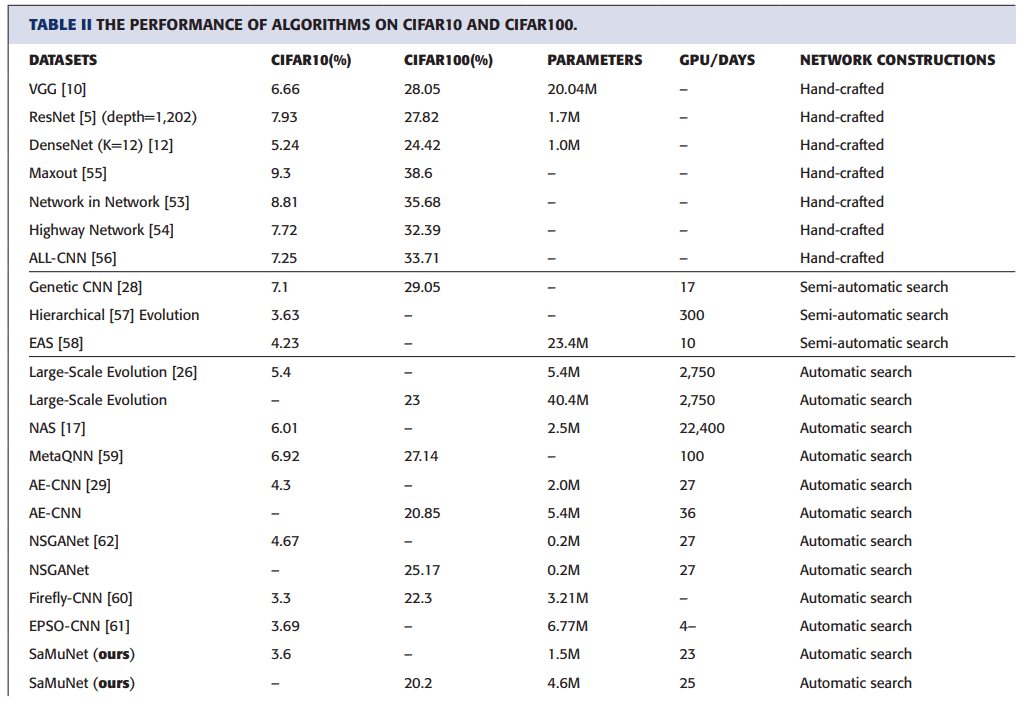
第2栏和第3栏显示了CIFAR 10和CIFAR 100的错误率,第4栏显示了最终的模型大小,第5栏显示了GPU/CIFAR的错误率。天,而第6栏显示了模型是如何构建的。
从表中可以看出,与ResNet和DenseNet等纯手工模型相比,SaMuNet在CIFAR10中的分类精度达到了第二低的错误率,略高于Firefly-CNN。此外,我们可以看到,模型的大小就比Firefly-CNN小得多;与其他自动搜索算法相比,GPU/天也更小。
建议的方法设计是否有效
在所提出的方法中,一般的遗传算法被修改,改变了变异选择方法和选择下一代的方法。这里介绍了该方法的验证结果。
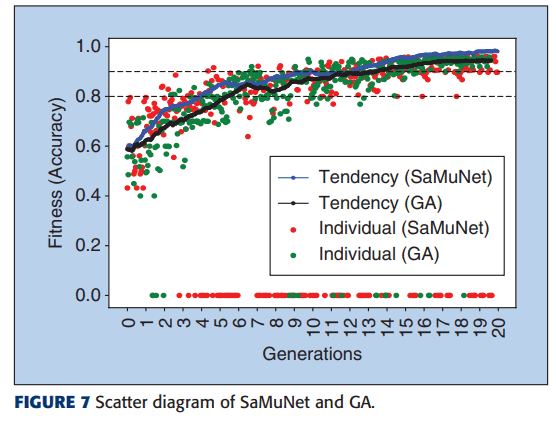
该图描绘了在使用一般的遗传算法(GA)和所提出的方法进行搜索时,搜索所得模型的准确性与生成的关系。图中显示,与一般的遗传算法相比,所提出的方法能够在同一代中探索出性能更高的模型。
摘要
在本文中,作者旨在减少NAS中所需要的计算资源,通过使用遗传算法,并通过使搜索空间以块为基础而变小,他们成功地搜索到了具有相对高分类精度的模型,同时实现了所需计算资源的减少。作者在最后表示,他们的目标是进一步减少计算资源,因此,看看他们将来能减少多少计算资源将是非常有趣的。



与本文相关的类别






