敌意数据扩展+混战,更强悍!
三个要点
✔️通过对抗性数据扩展和混合来提高模型的稳健性
✔️建立一个评估稳健性的协议
✔️在保持模型准确性的同时提高模型的稳健性
Better Robustness by More Coverage: Adversarial Training with Mixup Augmentation for Robust Fine-tuning
written by Chenglei Si, Zhengyan Zhang, Fanchao Qi, Zhiyuan Liu, Yasheng Wang, Qun Liu, Maosong Sun
(Submitted on 31 Dec 2020 (v1), last revised 6 Jun 2021 (this version, v3))
Comments: Accepted by ACL 2021.
Subjects: Computation and Language (cs.CL)
code:
研究概要
被称为BERT或RoBERTa。预训练的语言模型 (称为BERT和RoBERTa的预训练语言模型),据说容易受到对抗性攻击。 对于这些预训练过的语言模型,有可能在一个句子中,输入句子中的一些词被同义词取代(对抗性的例子)将输入句子中的一些词用同义词("对抗性例子")替换到模型中,这就是对抗性攻击。已被发现。为了防止这种攻击并使为了防止这种攻击并使模型更加稳健,有一种对抗性训练,它也使用对抗性例子来训练模型。
然而,输入句子的数量是无限的,而且可以创建对抗性例子来增加训练数据,但是对抗性例子的数量是不充分的,也不是详尽的。因此,作者还使用了一种叫做Mixup的方法,在数据之间进行线性插值,扩展训练数据。
相关研究
对抗性的数据增强
我们可以通过为训练数据创建对抗性例子来扩大训练数据的数量。有各种方法来创建对抗性例子,但在本文中,我们使用PWWS和TextFooler。(PWWS是一种根据某种评价函数决定在句子中替换哪些词的方法,并逐一用同义词替换单词,直到分类模型无法预测为止)。
混合数据增强
将两个标记数据$(\mathbf{x}_i, \mathbf{y}_i)$ , $(\mathbf{x}_j, \mathbf{y}_j)$和β分布$\lambda\sim{Beta(\alpha,\alpha)}$混在一起,从$\lambda \in得到[0 ,1]$,并按比例混合数据。
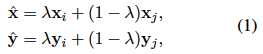
由于输入的句子(文本)不能加在一起,在本文中,$\mathbf{x}_i,\mathbf{x}_j$代表模型(BERT, RoBERTa)第{7,9,12}层的输出向量。(Chen et al.,2020)
我们还将只混合[CLS]标记的方法命名为SMix,将混合所有标记的方法命名为TMix。 此外,$\mathbf{y}_i,\mathbf{y}_j$是分类任务的标签一热向量。
建议的方法
我们使用相关工作中提到的 对抗性数据增强和混合性数据增强 来进行数据增强和微调,以提高模型的稳健性。
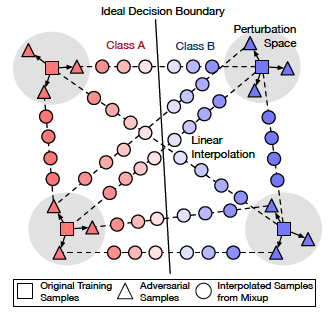
如该图所示,有三种类型的混合数据:(原始训练数据,原始训练数据),(原始训练数据,对抗性数据)和(对抗性数据,对抗性数据)。
另外,损失函数为以下公式。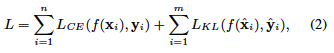 $(\mathbf{x}_i, \mathbf{y}_i)$代表原始训练数据和创建的对抗数据,并计算正确答案数据$\mathbf{y}_i$和预测值$f(\mathbf{x}_i)$的交叉熵。 另外,$(\hat{\mathbf{x}}_i, \hat{\mathbf{y}}_i)$是由混杂创建的数据,以及正确答案标签$\hat{\mathbf{y}}_i$和由混杂创建的预测值$f(\hat{\mathbf{x}}_i)$的KL。 我们计算发散并与上一节相加,得到损失函数。
$(\mathbf{x}_i, \mathbf{y}_i)$代表原始训练数据和创建的对抗数据,并计算正确答案数据$\mathbf{y}_i$和预测值$f(\mathbf{x}_i)$的交叉熵。 另外,$(\hat{\mathbf{x}}_i, \hat{\mathbf{y}}_i)$是由混杂创建的数据,以及正确答案标签$\hat{\mathbf{y}}_i$和由混杂创建的预测值$f(\hat{\mathbf{x}}_i)$的KL。 我们计算发散并与上一节相加,得到损失函数。
评价方法
在本文中,我们设置了两种评估方法来评估对对抗性攻击的鲁棒性。
- SAE(静态攻击评估
- TAE(目标攻击评估)
1.SAE:我们为原始模型(受害者模型)创建对抗性数据,并使用这些创建的数据来评估对新模型的准确性。
2.TAE:在创建一个模型后,我们为该模型创建对抗性数据作为受害者模型,并利用该对抗性数据评估受害者模型的准确性。换句话说,由于我们为每个模型创建了对抗性数据,并用模型自己的对抗性数据进行评估,所以这是一种更难提高准确性的评估方法。
实验与分析
数据集
在我们的实验中,我们使用了以下三个数据集。
- 二元分类:情感分析
- SST-2
- IMDB
- 4类分类:新闻主题分类
- AGNews
实验结果1
现在让我们看看实验的结果。首先,让我们看看对于一般的微调模型,这两种评价方法(SAE和TAE)有多大的偏差。
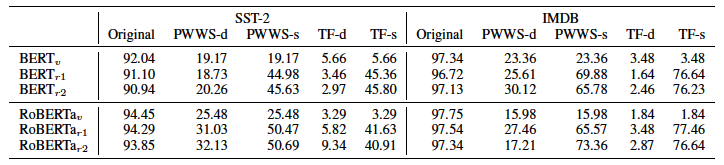 BERT$v$作为受害者模型,而仅通过改变随机种子的微调模型是BERT$r1$, BERT$r2$和RoBERTa的情况一样。评估中使用了三个测试数据:原始测试数据、由PWWS创建的数据和由TextFooler(TF)创建的数据。(原始测试数据被用来创建使用PWWS和TF的数据)。
BERT$v$作为受害者模型,而仅通过改变随机种子的微调模型是BERT$r1$, BERT$r2$和RoBERTa的情况一样。评估中使用了三个测试数据:原始测试数据、由PWWS创建的数据和由TextFooler(TF)创建的数据。(原始测试数据被用来创建使用PWWS和TF的数据)。
对于每个由PWWS和TF创建的数据,包括SAE(PWWS-s,TF-s)和TAE(PWWS-d,TF-d)的准确度结果。
从这个结果中,我们可以看出,只有通过改变随机种子的微调,才能提高SAE的准确性。另一方面,可以确认的是,只有通过微调,TAE的精确度才会低。因此,在实验结果2中,我们将看到只有TAE的结果,这是更困难的评价方法。
实验结果 2
以下是SST-2和IMDB的结果。(AGNews将在后面介绍)
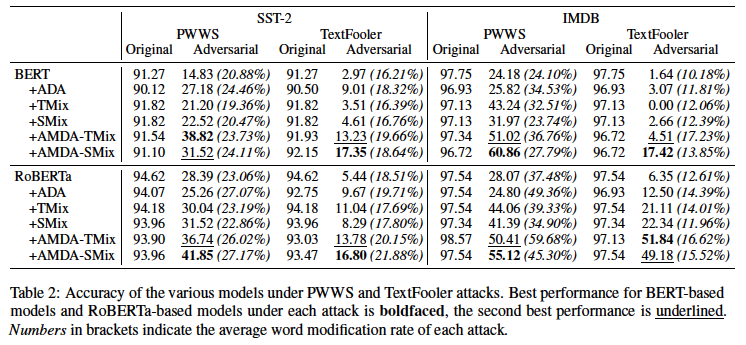
首先,我们总结一下实验设置。(更多细节,请参考相关研究和拟议方法)。
- ADA:使用PWWS、TextFooler,用对抗性数据加强训练数据
- TMix:在混合过程中混合所有代币
- SMix: 在混合过程中只混合[CLS]令牌
- AMDA-TMix:在AMDA中使用TMix,建议的方法是
- AMDA-SMix:在AMDA中使用SMix,所提出的方法
RoBERTa的结果表明,即使只使用Mixup(TMix,SMix),鲁棒性也得到了改善。在这两项任务中,所提出的方法的鲁棒性都比基线有所提高,这表明对抗性数据扩展(ADA)和Mixup相互补充,有助于提高鲁棒性。
结果还表明,在使用对抗性数据增强(ADA)时,对原始测试数据的准确性有所下降,但所提出的方法与对抗性数据扩增(ADA)相比。一些结果表明,针对原始测试数据的准确性也得到了提高。
结果表中括号内的数字是创建对抗性数据时每个数据的平均单词替换率。在所提出的方法中,这个较高的比率可以解释为意味着对抗性数据的产生更加困难,所提出的方法的稳健性得到了改善。
以下是AGNews的结果。
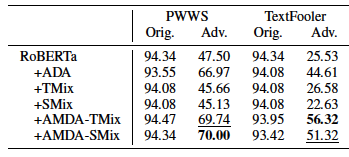 这里的结果与SST-2和IMDB的结果相似。
这里的结果与SST-2和IMDB的结果相似。
摘要
在本文中,我们提出了一种使用对抗性数据扩展和Mixup的微调方法。我们还设置了两种评估方法来检查对对抗性数据的鲁棒性。我们使用TAE评估了所提出的方法,这是其中最难的评估方法,并显示了所提出的方法的稳健性。
特别是,本文中评价方法的设置对那些做类似研究的人来说是一个有用的指标,以竞争准确性。



与本文相关的类别






