在语言数据集中有很多重复的句子!
三个要点
✔️ 当前数据集中的训练和测试数据存在重复。
✔️ 模型将记住重复的数据,因为它是
✔️ 删除重复的数据也会改善模型。
Deduplicating Training Data Makes Language Models Bette
written by Katherine Lee, Daphne Ippolito, Andrew Nystrom, Chiyuan Zhang, Douglas Eck, Chris Callison-Burch, Nicholas Carlini
(Submitted on 14 Jul 2021)
Comments: Published on arxiv.
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG)
code:

本文所使用的图片要么来自论文件,要么是参照论文件制作的。
简介
在过去几年中,语言学数据集变得越来越大,但有人指出,这些数据集的质量很低,因为它们没有经过人工审查。一些普通的语言数据集被发现包含许多重复的例子和长的重复字符串。
天真的重复数据删除很容易,但在大规模执行完全重复数据删除在计算上很困难,需要先进的技术。(对于像我们正在讨论的数据集,已经进行了某种形式的天真重复数据删除)。
在目前的数据集中,训练数据和测试数据存在重叠,这可能导致训练模型的准确性被高估。人们还观察到,训练模型记住并输出了在数据集中经常出现的句子。
本研究提出了两种检测和删除重复数据的方法,并调查了常用语言数据集(C4、Wiki-40B、LM1B)的重复内容。
建议的方法
寻找重复句子的最简单方法是对所有的句子对进行字符串匹配,但由于其计算复杂性,不建议这样做。因此,提出了两种互补的方法。
我们首先使用后缀数组从数据集中删除重复的子串,因为这些子串在多个例子中逐字出现。
接下来我们使用MinHash。这是一种高效的算法,用于估计语料库中所有实例对之间的n-gram相似性,如果n-grams与其他实例重叠太多,则从数据集中删除整个实例。
确切地说是
由于人类语言的多样性,相同的信息在多个文件中很少有相同的表达,除非一个表达方式是从另一个中复制出来的,或者两者都来自一个共同的来源。这种重复可以通过寻找完整的子串匹配来消除。这种方法被称为ExactSubstr。
后缀数组允许有效计算子串查询,并允许在线性时间内识别重叠的训练实例。它已被广泛用于自然语言处理任务中,如高效的TF-IDF计算和文档聚类。
为了找到所有重复的字符串,你需要从头到尾线性地扫描SUFFIX ARRAY,寻找序列。具有共同前缀的字符串,其长度超过阈值的,将被记录。该算法可以并行运行,这意味着数据集可以得到有效处理。在这种情况下,我们将50个标记作为匹配子字符串的阈值。
近似于Dup
这个方法被称为NearDup,执行近似的重复删除,以处理非常常见的模板部分相同的情况,特别是在网络文档中。
MinHash是一种近似的匹配算法,广泛用于大规模的重复清除任务。如果一个文件的n-grams的jaccard系数足够大,那么这两个文件就有可能是紧密匹配的;如果两个文件被认为是匹配的,那么它们之间就会产生一条边并被绘制成图。通过这种方式,我们建立了一个类似文件的集群。
由ExactSubstr和NearDup检测到的重复百分比。
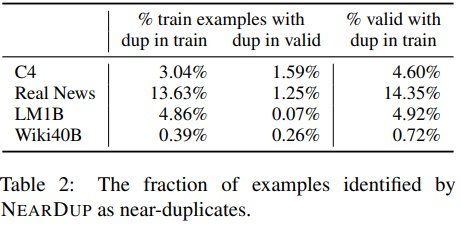
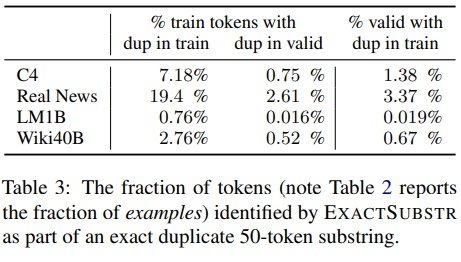
平均而言,使用ExactSubstr时比使用NearDup时删除的内容更多。LM1B是个例外,ExactSubstr删除的数据量是NearDup的八分之一。经调查,发现这是因为LM1B文件要短得多。
少于50个标记的句子不被ExactSubstr认为是匹配的,即使整个序列都是匹配的;NearDup和ExactSubstr都可能删除相同的内容。 NearDup从C4中删除的训练数据中,有77%的内容是匹配的在NearDup从C4中删除的77%的训练数据中,有一个长度为50或以上的匹配,被ExactSubstr检测到。
RealNews和C4的创建者在建立数据集时明确地试图去除重复的内容,但他们的方法不足以捕捉互联网上发现的微妙的重复字符串类型。
在C4和Wiki-40B中,很多被认定为接近重复的文本可能是自动生成的。除了地方、公司、产品和日期等名词外,其他的文字都是一样的。由于这些例子往往每次只相差几个字,依靠全字符串匹配的重复删除策略将无法识别匹配。
就RealNews和LM1B而言,这两个网站都来自于新闻网站,我们发现有很多重复,因为同样的新闻以稍微不同的格式出现在几个新闻网站上。
对模型学习的影响
XL模型有15亿个参数,分别在C4-Original、C4-NearDup和C4-ExactSubstr数据上训练;对于几乎没有重叠的数据,如C4验证集,所有模型的复杂度相同。
然而,在重复数据上训练的模型的复杂度明显高于在原始数据上训练的模型:ExactSubstr产生的困惑度差异比NearDup更大。这种趋势对于XL尺寸的模型也是如此。
这可能表明,ExactSubstr导致模型在训练集上的过拟合程度最低,但请注意,这两种方法都使用单独的阈值,不同的阈值选择可能改变结果。
重复的删除并不影响,在某些情况下还能提高模型的复杂性,尽管由于数据集较小,训练的速度更快。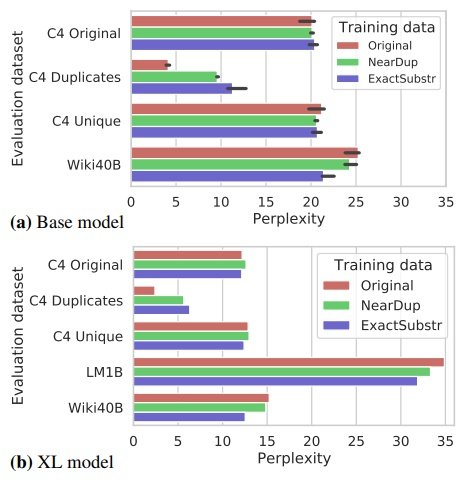
文本生成
数据重复具有使训练模型偏向某些类型的例子的效果。这增加了生成的句子从训练数据中复制的可能性。
首先,我们评估了模型生成没有提示序列的文本时的内存趋势:生成100000个例子,最大长度为512个符号。
使用XL-Original,超过1%的生成标记被包含在记忆的子序列中。这比XL-ExactSubstr或XL-NearDup的记忆量大10倍。
摘要
虽然我们只关注了英语,但我们相信其他语言也存在类似的问题。最近的研究还集中在有问题的数据集可能产生的潜在危害上。然而,这项研究的重点是典型数据集中重复内容的数量,重复删除对训练模型复杂性的影响,以及重复删除导致的训练模型存储内容的减少。它并不关注被删除或被存储的数据的性质,因为去重。
记忆是未来工作的一个重要课题,因为它可能对隐私产生严重影响。重复删除也无助于删除不应使用的受隐私保护的数据,如密码或医疗记录。
尽管模型记住的许多句子被认为是无害的,但我们没有系统地评估其风险,因为这超出了本研究的范围。
到目前为止,我们只发现了重复删除的好处,没有调查任何负面影响。有些语言任务需要明确的记忆,例如检索文件或回答书中的问题。
记忆是语言模型的一个理想或不理想的属性,既取决于被记忆的文本的性质,也取决于应用。开发根据应用情况记忆和遗忘特定文本的技术是一项有前途的未来研究。



与本文相关的类别






