认识DialoGPT,一个来自微软的强大的聊天机器人
三个要点
✔️ 一个能产生类似人类对话的聊天机器人。
✔️ 使用了来自Reddit的约20亿字的大型对话数据集。
✔️ 在自动和人工评估方面都具有最先进的性能。
DialoGPT: Large-Scale Generative Pre-training for Conversational Response Generation
written by Yizhe Zhang, Siqi Sun, Michel Galley, Yen-Chun Chen, Chris Brockett, Xiang Gao, Jianfeng Gao, Jingjing Liu, Bill Dolan
(Submitted on 1 Nov 2019 (v1), last revised 2 May 2020 (this version, v3))
Comments: Accepted by ACL 2020 system demonstration.
Subjects: Computation and Language (cs.CL); Machine Learning (cs.LG)
code:
首先
自然语言处理(NLP)最令人兴奋的用例之一是聊天机器人。聊天机器人对客户服务任务已经很有用了。这些聊天机器人很简单,很容易被不熟悉的问题所迷惑。因此,它们需要根据公司及其运作情况进行设计,这可能是昂贵的。即使如此,也不能保证稳健性:在大型语料库(如GPT-2)上训练的转化器能够产生内容丰富、流畅的文本。这样一个大规模的语言模型可以用来看不见的问题可以用来创建更强大的聊天机器人,以回应

在本文中,我们扩展了GPT-2,以应对对话式神经反应系统的挑战。该模型被称为DialoGPT,并在从Reddit提取的大型对话会话语料库上进行了训练;DialoGPT在自动和人工评估上都取得了最先进的性能;DialoGPT产生的反应是多样化的,与查询相关的,该系统能够对各种查询做出反应,包括最常见的查询。
技术
Reddit数据集
为了训练这个模型,我们使用从Reddit上提取的讨论环节。这将是2005年至2017年的会议;Reddit以树的形式组织这些讨论会议。讨论主题和问题作为树的根部,每一个回复都形成树的一个新分支。从根到叶的每条路径都被视为一个训练实例。提取的数据经过严格的过滤,以去除攻击性词语、重复性词语和非常长/非常短的序列。因此,得到了147,116,725个对话实例和18亿字的数据。
模型
DialoGPT是以OpenAI的GPT-2为基础的,这个转化模型是由一堆被遮蔽的、多头的自我注意层组成的,在一个大型的网络文本语料库中进行训练。首先,所有的对话被串联成一个长的文本序列x1,x1.....xN,并在最后放上一个特殊的序列结束符。让源语句为S = x1,x2,。.xm,目标语句是T = xm+1,xm+2。.xN。条件概率P(T|S)由以下公式给出

聊天机器人模式往往会产生平淡无奇、不知所云和不相关的答案。为了解决这个问题,我们实现了一个最大的相互信息评分函数。P(Source|Response),它使用预先训练好的模型从反应中预测源句。通过最大化这种可能性,我们对平淡无奇或不知所云的回答进行惩罚。
实验和评估
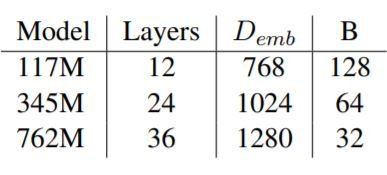
三个模型中的每一个都是以50,257的词汇量进行训练。小型和中型模型在5个历时中训练,大型模型在3个历时中训练。
我们在DSTC-7(Dialog System Technology Challenges-7 track)数据集上评估了我们的模型。DSTC-7中的对话与以目标为导向的互动不同,如订票或订座。我们还将该模型与PersonalityChat模型进行比较,后者是微软在生产中的认知服务。结果显示在下面的表格中。
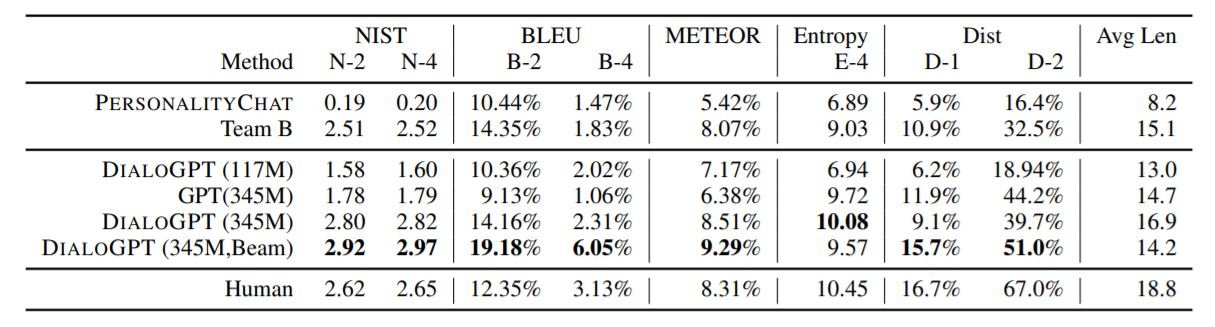
使用波束搜索(波束宽度为10)的345M参数的DialoGPT超过了其他模型。以下是我们的模型所产生的一些反应样本。


摘要
DialoGPT是一个强大的神经对话系统。由于它是用互联网(Reddit)上的信息进行训练的,所以尽管努力限制不道德的、攻击性的或有偏见的回应,它还是倾向于产生这样的回应。为研究人员提供了一个学习机会,以消除聊天机器人的这种有偏见和不道德的答案。DialoGPT的得分比人类好,但这并不表明DialoGPT的对话比人类好。它对人类对话的不确定性还不够强大。你可以通过这个链接自己尝试一下这个聊天工具。



与本文相关的类别






