对生成的文本中类似人类和有趣的方面进行精确建模:MAUVE
三个要点
✔️ 开发了一种自动评估原始编码的人为性的方法。
✔️ 使用KL发散法建立的I型和II型误差模型
✔️ 与人工评估的相关性大大高于现有方法,实现了最高的准确性
MAUVE: Measuring the Gap Between Neural Text and Human Text using Divergence Frontiers
written by Krishna Pillutla, Swabha Swayamdipta, Rowan Zellers, John Thickstun, Sean Welleck, Yejin Choi, Zaid Harchaoui
(Submitted on 2 Feb 2021 (v1), last revised 23 Nov 2021 (this version, v3))
Comments: NeurIPS 2021
Subjects: Computation and Language (cs.CL)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的 。
简介
有一项任务叫做开放式语言生成。一些最著名的是聊天对话和故事生成。你知道如何自动评估这些任务吗?
机器翻译和摘要有一个明确的正确答案,所以我们试图用BLEU或ROUGE来衡量与正确答案的距离。然而然而,在开放式的语言生成中,没有明确的正确答案。因此我们使用语言模型来间接估计一个句子是否像人,是否有趣。在本文中,有几个指标被引入作为基线,包括
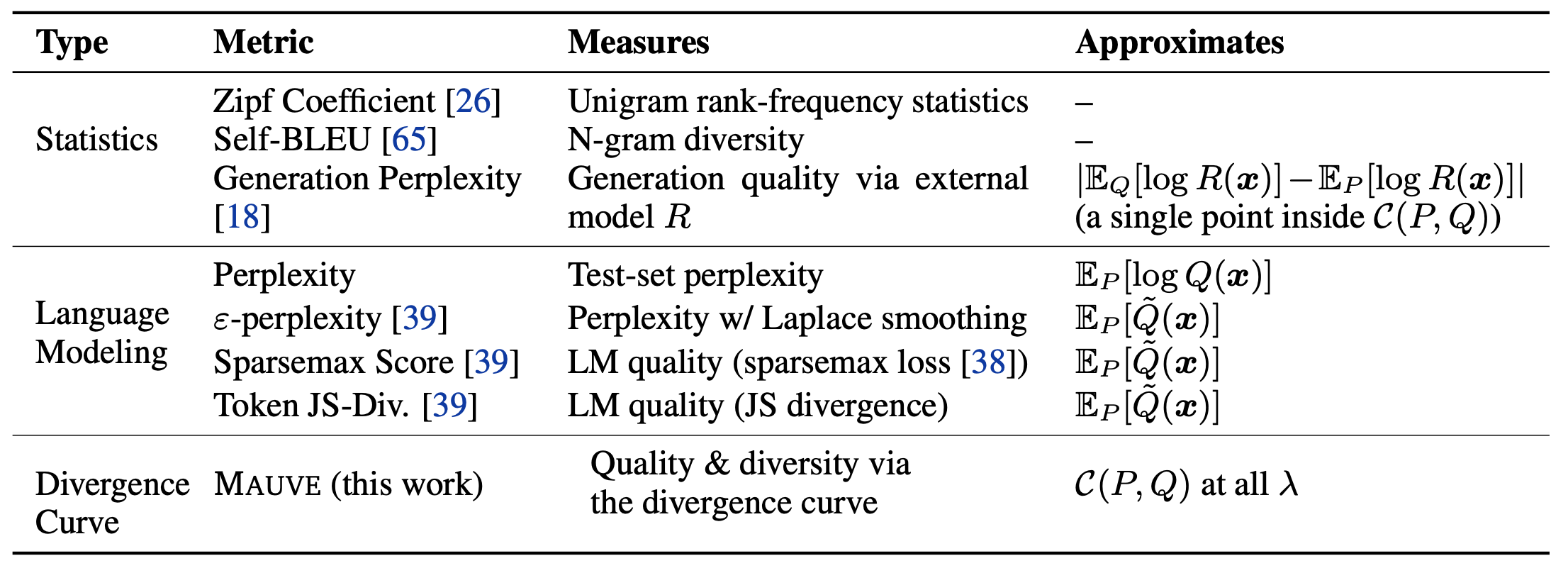
在这些表格中,最著名的可能是《困惑》。它评估了生成的句子的可能性。例如,Self-BLEU通过比较生成的句子之间的BLEU来评估多样性。所提出的方法MAUVE,如表底所示,通过使用KL-分歧,实现了与人类评价的更高的相关性,比以前的那些研究。
本文概述了MAUVE,它也被NeurIPS选为优秀论文。
茂华
I型和II型错误的建模
I型和II型错误的概念经常被用来对模型中的错误进行分类。它们也分别被称为假阳性和假阴性,在语言生成的背景下,它们是
- 第一类错误:产生不太可能是人类写的句子(重复是一个典型的例子)。
- 第二类错误:无法生成看起来像人类书写的文本
其结果是在下图中(Q是生成的文本,P是人类文本)。
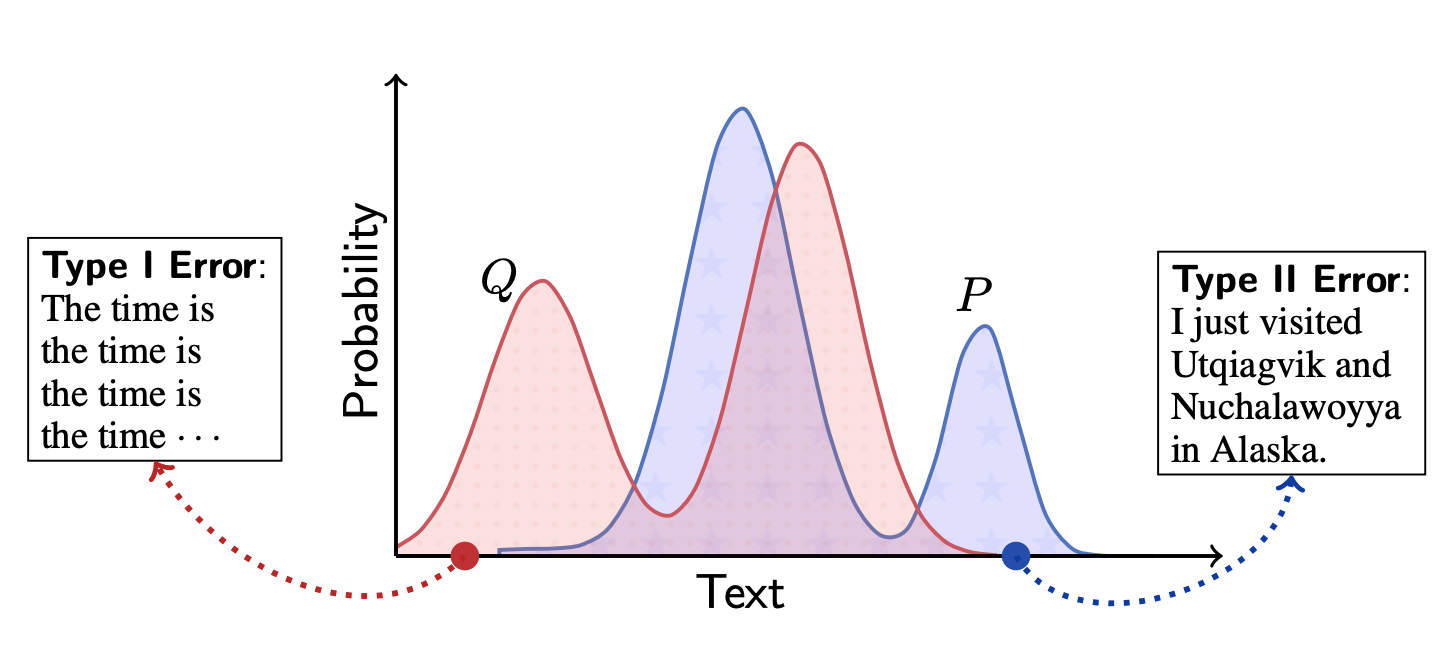
在图中,模型和人类文本的出现概率被绘制成一个概率分布。KL-分歧是一个衡量概率分布之间差距的指标,差距越大,两个分布的差异越大。KL-分歧是非负的,并且根据作为参考的概率分布的不同而不同。
在MAVE,我们在引入KL-发散时做了两个重大改变。我们将在本节中对它们进行解释。
设计1:使用文本向量创建概率分布
当我们在NLP中使用KL-divergence时,我们经常为Vocabulary创建一个概率分布。然而,在本研究中,我们通过预训练模型(GPT-2)生成文本向量,进行聚类,并根据向量创建一个概率分布。通过这样做,我们成功地将更多的上下文含义纳入了比通过词汇量测量KL-分歧更多的内容,同时也降低了计算的复杂性。程序如下
- 分别对生成的文本和人类的文本进行采样(论文中为5000)。
- 使用GPT-2将每个文本变成一个矢量
- 混合文本向量,用k-means对其进行聚类(论文中有500个聚类)。
- 为每个生成的文本和人类文本创建一个集群的概率分布
如果你有兴趣,请参考附录,其中包含关于样本数量、聚类和聚类算法的详细实验。
设备2.用混合分布测量KL-分歧
KL-分歧的一个重要属性是,如果分布差异过大,数值可能会出现分歧。因此,KL-分歧不适合作为评价指标。在这项研究中,我们不直接测量两个分布,即生成的文本和人类文本之间的KL-分歧,而是测量两个分布的混合物和两个分布中的每一个。人类文本的KL-分歧是通过以下公式计算的
$mathrm{KL}\left(P\mid R_{lambda}\right)==sum_{boldsymbol{x}} P(\boldsymbol{x}) \log\frac{P(`boldsymbol{x})}{R_{lambda}(`boldsymbol{x})}$
其中$R_\lambda$是生成的文本和人类文本的混合分布(或$Q(\boldsymbol{x})$为通常的KL-分歧)。 $R_\lambda$的生成方式如下。
$R_{lambda}=P+(1-\lambda)Q$
$lambda$是一个超参数,取值范围为[0,1],它控制P和Q的混合比例。MAUVE使用在[0,1]中移动$lambda$得到的发散曲线。
$mathcal{C}(P, Q)=\left{left(\exp \left(-c \mathrm{KL}\left(Q mid R_{lambda}\right) \right), \exp \left(-c \mathrm{KL}\left(P \mid)R_{lambda}\right)\right): R_{lambda}=lambda P+(1-lambda) Q, \lambda \in(0,1)\right}$
这里,c是一个用于缩放的超参数,c>0,exp被处理为使KL-分歧值的范围为[0,1]。生成文本和人类文本的混合分布的KL-分歧图如下。
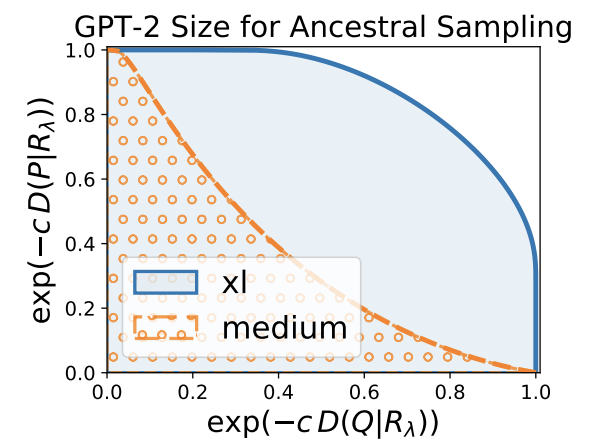
这张图读起来有点复杂,但从生成的文本来看,与混合分布的差距显示了横轴上的$lambda$的值和纵轴上的$exp\left(-c KL\left(Q_{\lambda}\right)}\right)$的值。另一方面,如果我们看一下人类文本中与混合分布的差距,纵轴显示$lambda$的值,横轴显示$exp \left(-c KL\left(P \mid R_{\lambda}\right)\right)$的值。
这个分歧曲线下的面积就是MAUVE分数。在上图中,我们比较了GPT-2 xl和medium文本生成的分数,并根据经验证明了MAUVE的合理性,因为xl的分数大于medium的分数。
实验
在实验部分,除了一些经验性的评价外,还进行了人工评价。
- 任务:文本完成
该任务是一项网络文本、新闻和故事领域的文本完成任务。给出第一个单词序列,任务是预测其余的单词序列。为了完成任务,我们将使用原始词序作为人类文本,但任务没有明显的正确答案。 - 解码算法(参考):考虑了三种解码算法。一般来说,模型的准确性是按照贪婪解码<祖先采样<核子采样的顺序。
- 贪婪的解码
在每个解码步骤中,总是选择出现概率最高的词。 - 祖先采样
根据语言模型的概率分布,对下一个词进行概率性选择。 - 细胞核取样
截断除最上面的p个词以外的所有词,并根据剩余词的分布比例来选择下一个词。
- 贪婪的解码
准确性是否随着句子的长度而降低?
当然,模型生成的文本越长,准确性就越差(即它与人类文本的偏差越大)。我们将进行实验,看看自动评价指标,包括以前研究中的指标,是否能够捕捉到这种现象。
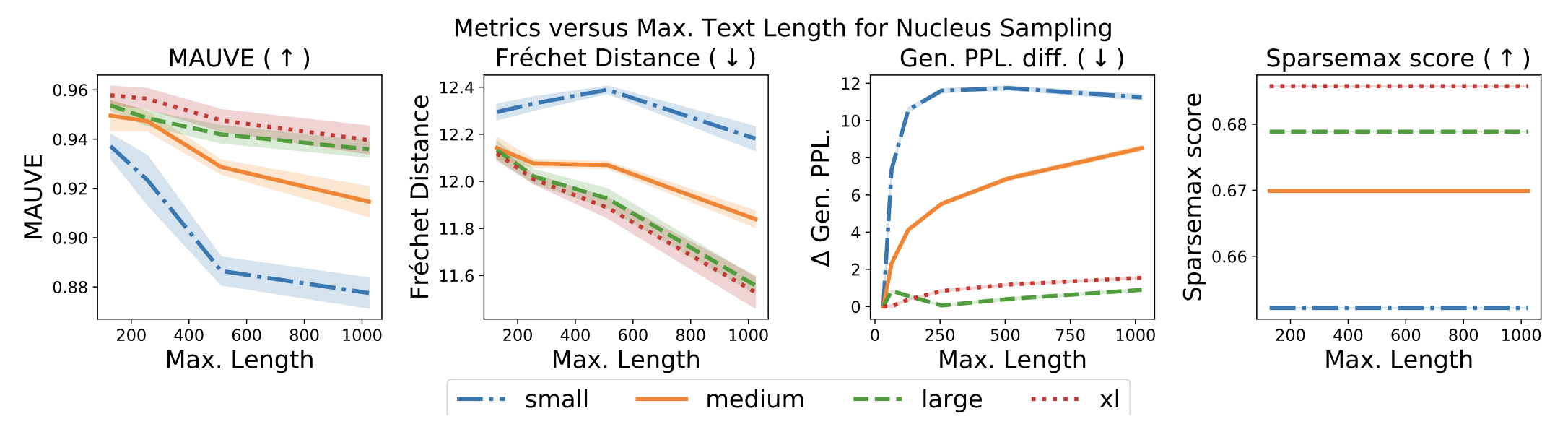
我们可以看到,左边的MAUVE是唯一捕捉到变化的人。没有其他指标能够捕捉到所有模型尺寸的变化。
你能抓住解码算法和模型大小的差异吗?
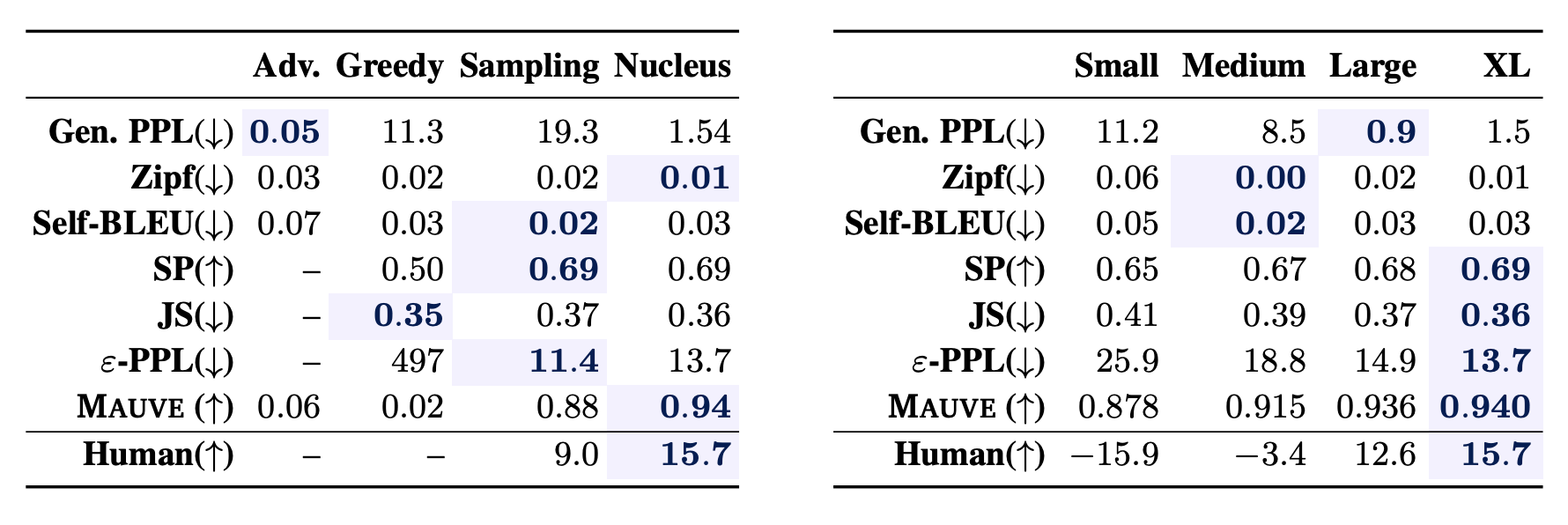
左边的表格显示,MAUVE的得分顺序是贪婪解码<祖先采样<核子采样。右边的表格还显示,MAUVE在GPT-2模型的小号、中号、大号和XL号上得分更高。
与人力评估是否有关联?
到目前为止,我们使用的是经验性评价,但我们将看看它是否与最重要的人类评价相关。我们采用了通常用于评价开放式任务的三个指标:类人、有趣和合理,并针对模型生成的文本对它们进行了注释。各项指标与人类得分之间的相关系数见下表。

MAUVE显示出明显高于以往研究的相关性。高相关性表明,有可能以高精确度评估开放式任务。
摘要
在这篇文章中,我们介绍了MAUVE,它可以让你高度准确地评估生成文本的质量。
除了准确性,它似乎也很容易使用,因为它已经可以通过pip获得,而且不需要对模型进行任何训练。它很可能成为评价开放式任务的新的事实上的标准。
另一方面,大量的高paras,如抽样数量和聚类算法的选择,在我们想用新的数据构建指数时,可能是一个障碍,但本文在附录中进行了相当仔细的实验,我们认为这也促成了高评价。对开放式任务的自动评估仍无定论,而分数增加的方式表明近年来有了很大的改进,所以这是一个研究领域,我们期待着看到它在未来的发展。



与本文相关的类别






