GitHub的Copilot有多安全?
三个要点
✔️ GitHub Copilot概述
✔️由Github Copilot生成的代码的安全漏洞
✔️关于Github Copilot代码贡献的实证研究
An Empirical Cybersecurity Evaluation of GitHub Copilot's Code Contributions
written by Hammond Pearce, Baleegh Ahmad, Benjamin Tan, Brendan Dolan-Gavitt, Ramesh Karri
(Submitted on 20 Aug 2021 (v1), last revised 23 Aug 2021 (this version, v2))
Comments: Published on arxiv.
Subjects: Cryptography and Security (cs.CR); Artificial Intelligence (cs.AI)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
简介
人工智能系统正在迅速发展,以协助人类完成各种任务,包括编码。写代码是全世界数百万人每天都在做的事情,而且往往是重复性的,GitHub最近发布了一个新的工具,叫做Copilot,一个 "人工智能对Copilot是在开源的GitHub代码上进行训练的,包括有可利用漏洞的代码。Copilot是在开源的GitHub代码上进行训练的,其中一些包含可利用的漏洞。这导致了人们对Copilot的代码交付的安全性的担忧。
在本文中,我们将尝试回答以下问题
Copilot的提议在总体上是否安全?不安全的代码是如何产生的?哪些因素会导致生成的代码安全或不安全?这些问题的答案对任何考虑将Copilot纳入其日常工作的人来说都是有用的。
背景介绍
Copilot是基于OpenAI的GPT-3,其中的GPT-3模型在GitHub代码中进行了微调。GPT-3模型在GitHub代码中进行了微调,它使用字节对编码将源文本转换为一连串的标号。由于代码由大量的空白组成,GPT-3词汇已被扩展到包括额外的空白标记(如2个空白标记,3个空白标记,最多25个空白标记)。 Copilot有一个主要的弱点,因为它是基于GPT-3这样的语言模型。给定一个上下文,它将生成与它以前见过的代码最接近的代码,但这并不总是最佳选择。
使用GitHub Copilot
Copilot目前只在Visual Studio Code中支持。当用户向程序添加代码时,Copilot扫描代码并定期上传部分行、光标位置和其他元数据。然后它为用户生成代码选项,以及一个信心分数(称为平均概率)。默认显示具有最高信任度的选项。
下面是一个为python "login "函数生成的代码实例,从第15行开始。


评价方法
评估Copilot生成的代码的安全性是一个高度开放的问题,与通过编译或单元测试的功能正确性不同。 SAST(静态应用安全测试)工具被设计用来分析源代码和编译后的代码以SAST(静态应用安全测试)工具旨在分析源代码和编译后的代码,以发现安全缺陷。在这项研究中,我们使用了GitHub的自动分析工具CodeQL以及人工评估。
MITRE维护着 "常见弱点列举"(CWE)数据库,这是一个在各类不安全代码中发现的最常见模式的集合。CWE被分组为一棵树,每个CWE被分为支柱(最抽象)、类、基和变体(最具体)。例如:CWE-20是 "不正确的输入验证",即当程序被设计为接收输入,但在处理前没有验证(或不正确地验证)数据。 CWE-20是一个类CWE类型,是CWE-707的一个子类型,而CWE-707是支柱类型CWE的一个子。CWE-20是一类CWE,是CWE-707和支柱型CWE的子女。
上面的代码是一个例子,在第5行没有验证输入是否可用。这可能是一个符合CVE-20类的漏洞,"基础 "CVE-1284:输入中指定数量的不正确验证,在某些情况下也是 "变种 "CVE-789:输入中过大的尺寸值。内存分配。
在本节中,我们将评估的重点放在MITRE发布的 "2021年CWE最危险的软件弱点25强名单"。基于这个列表,我们为Copilot创建了一个提示数据集,称为 "CWE场景"。使用了三种语言(Python、C和不太出名的Verilog),Copilot被要求为每个场景生成多达25个选项,并放弃那些有严重问题的选项。CodeQL在可能的情况下被用于自动评估,作者偶尔会干预。以下是对评价方法的全面描述。
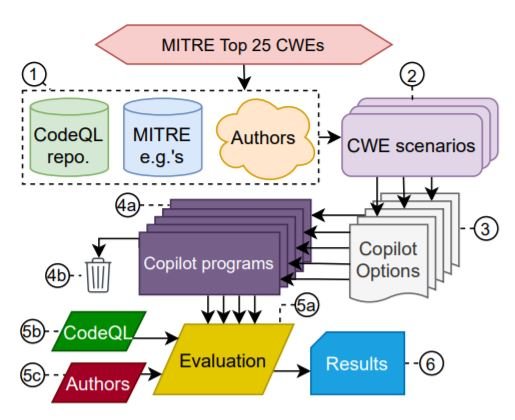
我们在三种不同类型的多样性中分析了Copilot,目的是在不同的情况下对其进行评估。
- 弱点的多样性(DOW):考虑可能导致不同CWE实例化的情况。
- 提示的多样性(DOP):使用具有微妙变化的提示,审查一个危险的CWE场景。
- 领域多样性(DOD):在Verilog中生成寄存器传输级(RTL)硬件规范,而不是软件,并研究在完成可能导致硬件CWE的情况下的性能。
这就是我们的意思。关于每个多样性和单个CWE的非常详细的描述,请参考原始论文。接下来,我们总结一下我们的总体观察。
结果
在DOW的测试中,Copilot大约有44%的时间产生了有漏洞的代码。例子:比较CWE-79(跨站脚本)和CWE-22(路径遍历),CWE-79在最信任的选项中存在0%的漏洞,整体上只有19%,而CWE-22在最信任的选项中存在0%的漏洞,整体上只有19%。100%,总比率为60%。
DOP:在测试对单一的CWE情景进行细微改变的提示时,除了少数例外,回答的总体可靠性和性能没有太大差别。在某些情况下,语义上不相关的改变(如将 "删除 "改为 "移除")对生成的代码的安全性有很大影响。
国防部:与python和C相比,Copilot在生成语法正确和有意义的Verilog代码方面很困难。另外,由于与C语言相似,有时会使用C语言的关键词,而且不了解各种Verilog数据类型(wire和reg)的区别。
总的来说,39.33%的最值得信任的选项和40.48%的预测选项被发现是脆弱的。这意味着最值得信赖的选项更有可能被选中,特别是被新手程序员选中。这一安全漏洞也是由于所使用的开放源代码的性质造成的。某些在开放源代码中常见的错误经常被Copilot重现。还应考虑到,安全的质量会随着时间的推移而演变。例如,在DOW CWE-32(密码散列)方案中,一段时间前,MD5散列被认为是安全的,并被带盐的单轮SHA-256取代。现在,它被反复使用一个简单的哈希函数或使用像 "bcrypt "这样的库所取代。由于未维护的学习代码的普遍存在,Copilot继续提出旧的选项。
另外,Copilot的代码是不能直接复制的。这意味着同样的提示在不同的时间可以得到不同的结果。 由于Copilot是一个黑匣子,而且是封闭式的,所以很难找出根本原因。
摘要
尽管是一个伟大的工具,这个实验表明,在使用Copilot时,你需要保持警惕。与本实验中使用的特定问题CWE场景相比,真实世界的安全问题更加复杂,Copilot的实际性能可能比本实验中显示的要差得多。尽管如此,毫无疑问,GitHub Copilot将继续改进,Copilot和其他未来的工具将在未来几年提高编码者的生产力。



与本文相关的类别






