
ByteTrack+外观特征最强:SMILETrack
三个要点
✔️ 考虑到外观特征的基于字节跟踪的跟踪
✔️ 建议的基于注意力的稳健识别同一类个体的机制
✔️ 建议的门函数对闭塞和运动模糊的稳健性
SMILEtrack: SiMIlarity LEarning for Multiple Object Tracking
written by Yu-Hsiang Wang, Jun-Wei Hsieh, Ping-Yang Chen, Ming-Ching Chang
(Submitted on 16 Nov 2022 (v1), last revised 17 Nov 2022 (this version, v2))
Comments: Published on arxiv.
Subjects: Computer Vision and Pattern Recognition (cs.CV)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
毕竟,ByteTrack也需要一个外观功能我们提出了SMILETrack,一个用于物体追踪的SoTA模型。我对ByteTrack持怀疑态度,它只使用运动信息(IoU)来进行关联,但有人提出了一种方法,表明仍应使用外观特征。
物体追踪可分为单独检测和嵌入模型(SDE)和联合检测和嵌入模型(JDE),前者基于检测器,并将每一帧之间的检测结果联系起来,后者从检测到追踪都使用单一的模型。SDE往往更准确,因为它允许单独的模型对检测和跟踪进行优化。另一方面,它使用单独的模型,这给实时估计带来了挑战。
JDE有望提供实时估计,因为它可以在一次估计中同时输出检测和跟踪,但由于竞争性学习,这导致了准确性的下降。建议的方法SMILETrack是一种SDE方法。继承了ByteTrack的方法,该方法只使用运动信息实现了SoTA,提出了一个基于注意力的外观特征提取器,并在MOT17和MOT20中实现了SoTA。
SMILETtack的主要贡献包括。
- 提出了一个外观特征提取器,即相似性学习模块(SLM),以明确区分使用注意力检测的个体。
- 人们指出了ByteTrack的低鲁棒性,并提出了相似性匹配级联(SMC),以实现加入鲁棒性外观信息的关联。
- 通过控制外观和运动信息的门函数与闭塞和运动模糊进行鲁棒性关联。
现在我们来看看SMILETrack。
字节跟踪
跟踪是指截至前一帧的跟踪与当前帧中检测到的物体之间的关联。通常,有两类信息被用来进行关联:基于运动预测的位置信息和物体外观信息。另一方面,ByteTrack只使用运动信息来实现SoTA。只使用运动信息是因为外观特征如果没有用的话,可能会降低准确率,对MOT17和MOT20来说,SoTA是通过简单的两阶段关联过程实现的:在只关联具有高检测置信度的物体和关联低置信度的物体之后。
然而,本文指出了没有外观信息的ByteTrack的弱点。它指出,由于MOTChallenge的动作很简单,所以只用动作信息就能达到很高的准确度,而对于复杂的动作,准确度就会下降,而且由于缺乏外观信息,所以不可能支持ID切换。
SMILETrack。
由于上述原因,SMILETrack结合了ByteTrack和外观特征提取的优点。它通过在使用检测置信度的两阶段关联中考虑到使用Attention的稳健外观信息,实现了高度精确的跟踪。整体情况如下图所示。
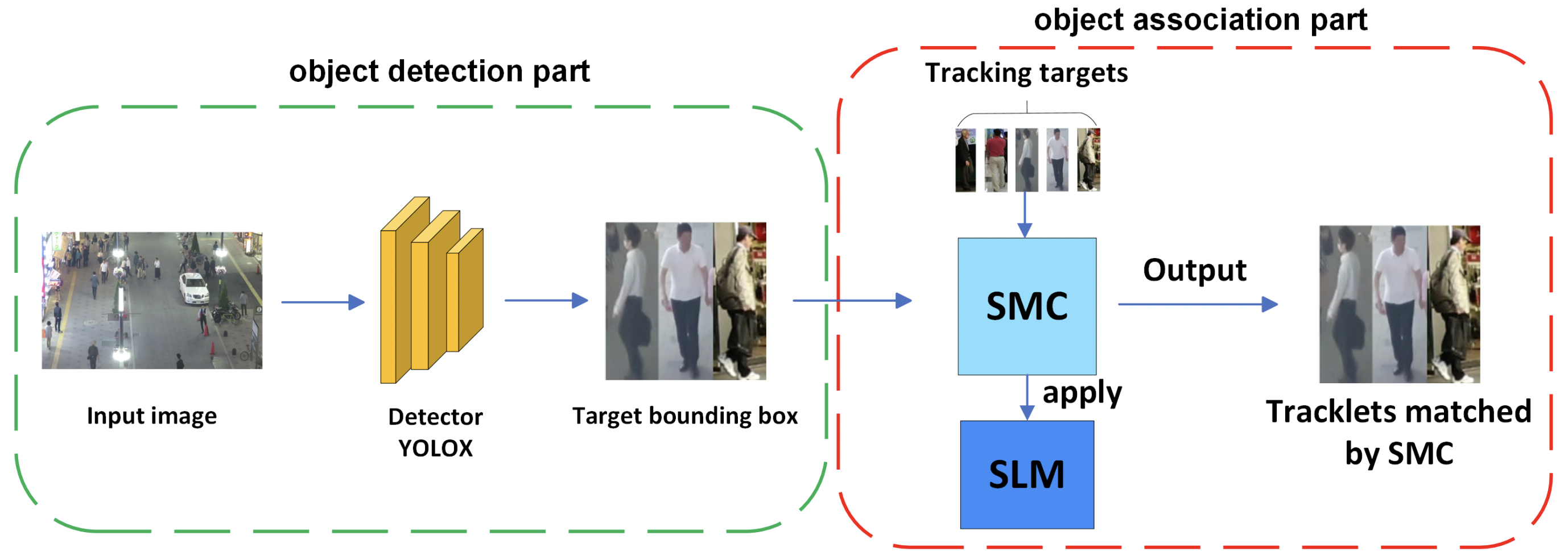
相似性学习模块(SLM)
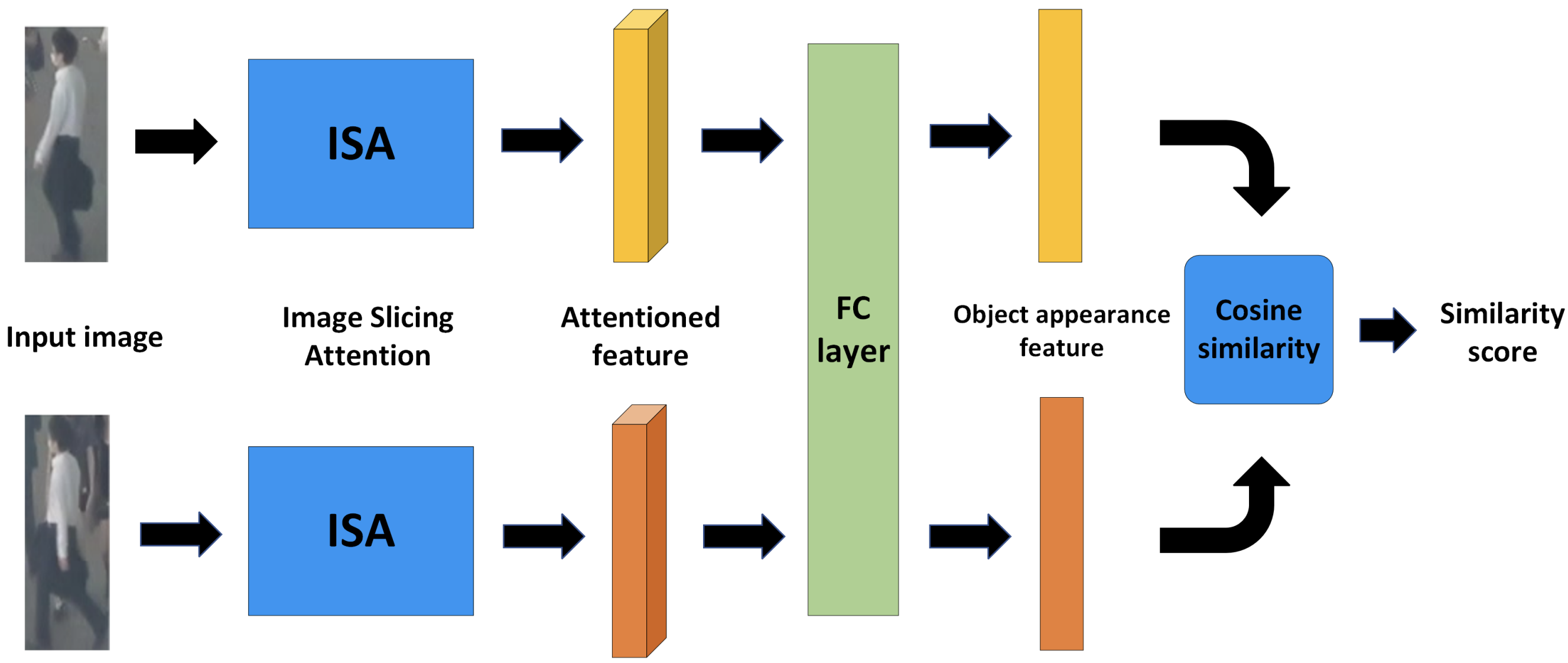
追踪中所处理的对象的外观特征需要比检测中更加严格。区分不同类别的高层次特征对检测很重要,而区分同一类别中不同个体的低层次特征对跟踪很重要。本文提出了一个名为相似性学习模块(SLM)的外观特征提取器,它由图像切片注意(ISA)块组成,可以灵活地提取每个个体的特征,更适合于分辨。
SLM具有下图所示的Sham网络机制,它学习并评估检测到的物体之间的相似度。其目的是对相同的个体(个人)给予较高的相似度,对不同的个体给予较低的相似度。由ISA提取的特定个体特征被整合到所有的联合层中以获得外观特征。通过计算它们之间的余弦相似度,得到关联的成本。
ISA块将检测到的物体分成四个切片图像,并提取它们之间的关系与Attention。首先,输入被重新调整为固定大小并输入到ResNet-18。然后将得到的特征图分成四个部分,形成一个切片图像。四个分割的位置被嵌入到线性投影Q、K、V中,并输入到Q-K-V注意力。
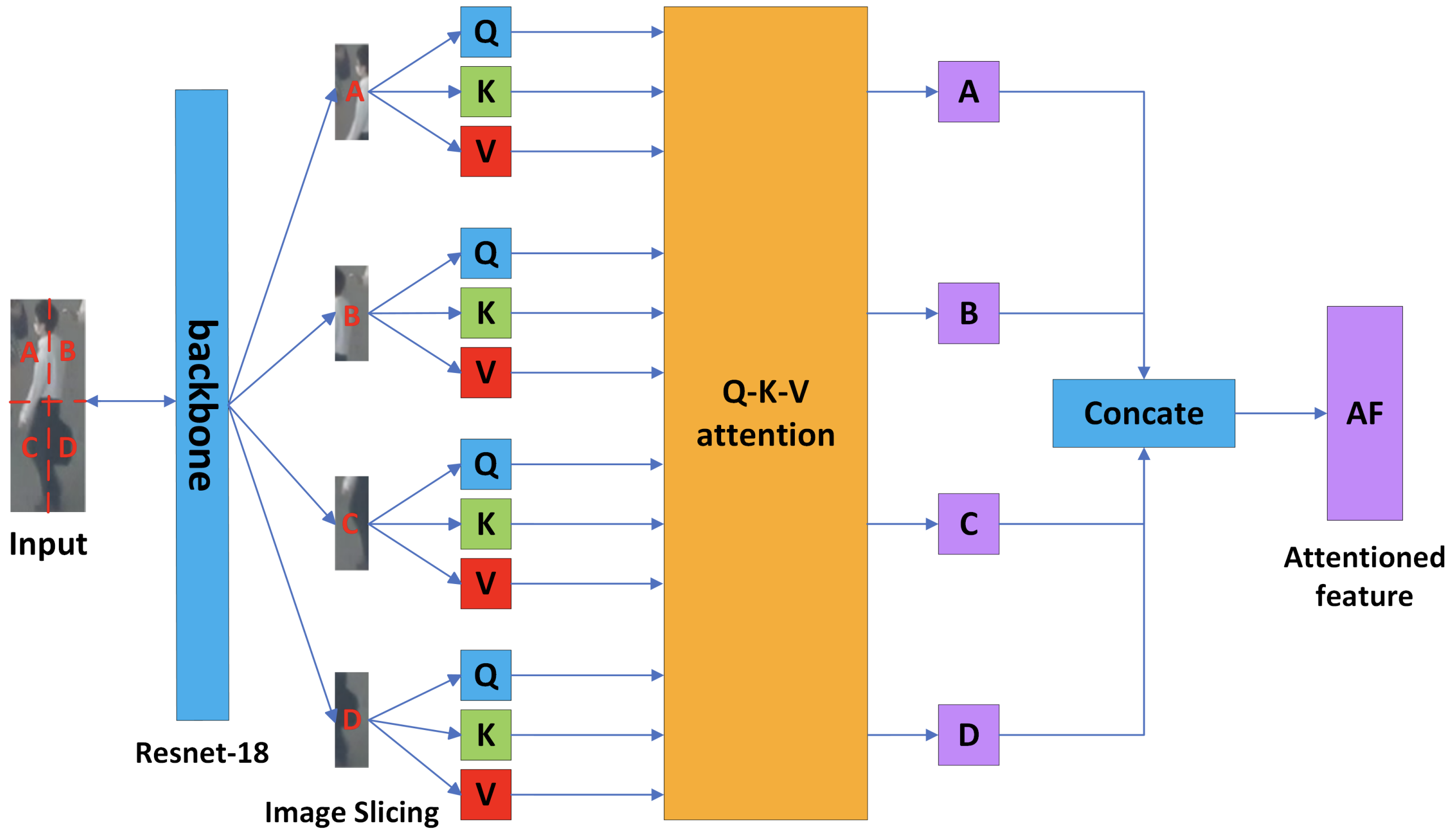
Q-K-V注意力模块计算出切片之间的自我注意力和交叉注意力。获得的切片特征最终被结合起来,以获得被检测物体的特征。通过评估与这些基于注意力的可靠特征的相似性,实现了一种能够以高精确度区分同一类别的不同物体的机制。
%2BCA(Q_%7BS1%7D%2CK_%7BS2%7D%2CV_%7BS2%7D)%0A%20%20%5C%5C%26%26%2BCA(Q_%7BS1%7D%2CK_%7BS3%7D%2CV_%7BS3%7D)%2BCA(Q_%7BS1%7D%2CK_%7BS4%7D%2CV_%7BS4%7D)%0A%5Cend%7Beqnarray*%7D&f=c&r=300&m=p&b=f&k=f)
(SMC)
SMC使用卡尔曼滤波器将获得的外观信息(SLM)与运动信息(IoU)联系起来。下图显示了整体情况。浅蓝色显示的第一关联和第二关联是ByteTrack中也有的两阶段关联。
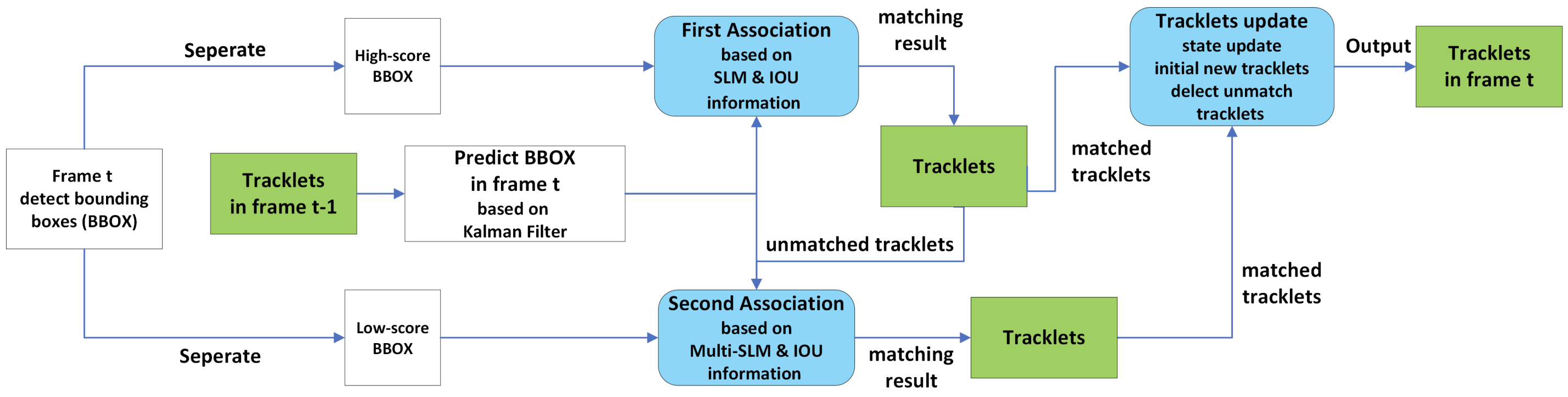
首先,检测器将当前帧t的检测结果(BBOX)按照置信度分为三类。首先,置信度低于0.1的检测结果被视为背景或噪音,不用于关联。具有较高置信度的检测被一个阈值thres分割:BBOX按置信度下降的顺序排列,BBOX前半部分的平均置信度为thres。高于此值的BBOX被归为高分BBOX,低于此值的BBOX被归为低分BBOX。
第一阶段。
第一阶段优先考虑高分的BBOXes进行关联:直到第t-1帧的跟踪结果(tracklet)和高分的BBOXes通过外观信息(SLM)和位置信息(IoU)进行关联。这使得只用高质量的信息就能实现可靠的跟踪。
第二阶段。
第1阶段将第2阶段中没有绑定的小轨与低分的BBOX联系起来。然而,这里使用的是一个稍加修改的SLM,即多模板SLM。这样做的原因是为了应对低置信度的检测。
低置信度检测可能是由于闭塞或运动模糊造成的特征提取困难。因此,跟踪小帧方面不只使用一个帧,而是使用几个跟踪的帧。每一帧的BBOX被保留下来作为特征库,并分别输入到低分BBOX和SLM中以获得相似度。相似度的最大值被用来作为最终外观信息的成本。这在本文中被描述为多模板-SLM。
闸门功能
在第一和第二阶段中,都使用了一个门函数进行关联。这是一种控制外观和运动信息的机制。在通常的实践中,外观信息的成本和IoU的成本是同等权重的。下面的公式中,α=0.5。
![]()
然而,当两个不同的行人之间的IoU超过了他们的外观特征的相似度,这就产生了一个问题。换句话说,即使外观信息表明他们是不同的个体,如果他们在位置上有很大的重叠,那么IoU就会很高,导致身份转换的问题,将他们与不同的人联系起来。
本文提出了一个门控函数,它拒绝具有高IoU但外观信息相似度低于0.7的匹配。这就减少了不正确的匹配,在这种情况下,不同的外观只要是重叠的就更好。
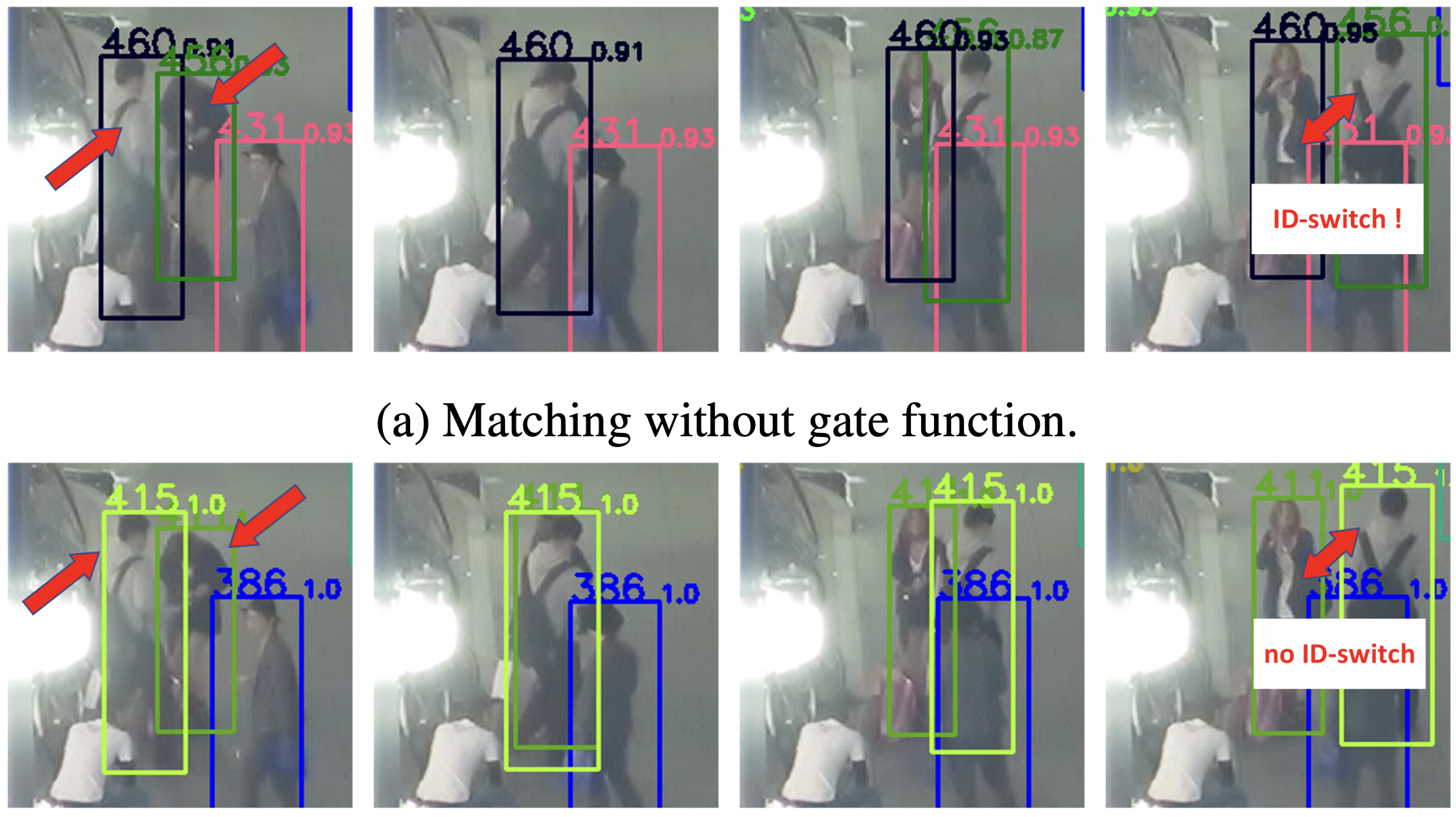
实验
在实验中,对MOT17数据集的准确性进行了与SoTA模型的比较和消融研究。在消融方面,MOT17训练数据的前半部分用于训练,后半部分用于验证;为了与SoTA模型进行比较,对MOT17、CrowdHuma、ETHZ和Cityperson的组合进行训练。
安装
所提方法的检测器使用一个名为PRB的模型,该模型在COCO数据集上进行了预训练,然后在MOT16和MOT17上进行了微调;SLM在其自身的数据集上进行了训练,该数据集是从MOT17训练集中挑选出来的。无法关联的小轨被删除,多模板-SLM特征库被保留到50帧以上。
与SoTA模型的比较
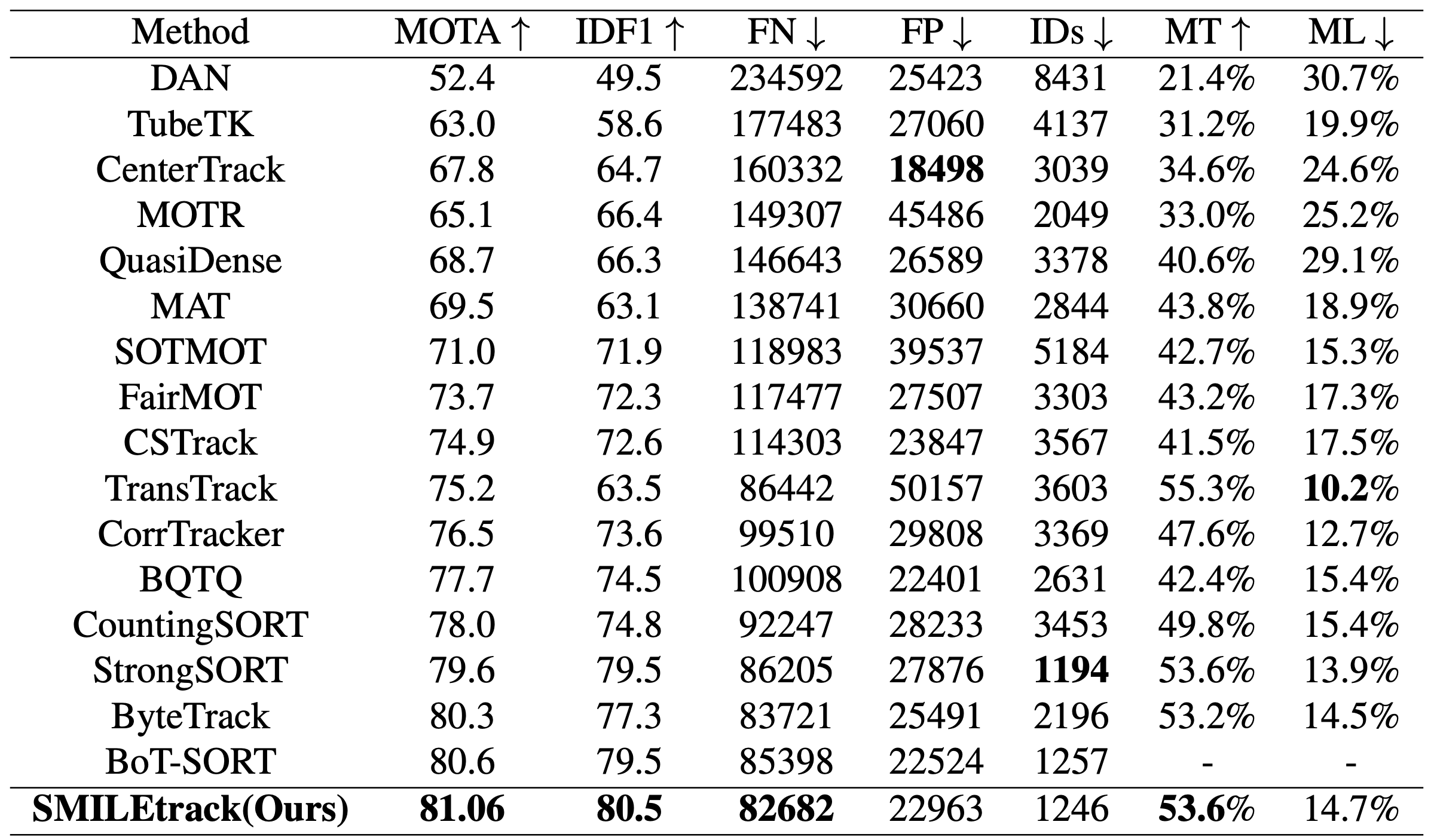
MOT17测试集的准确度。准确率与SoTA模型进行了比较,如ByteTrack(只使用运动信息)、StrongSORT(是DeepSORT的改进方法)和TransTrack(建立在Transformer上,用于检测和跟踪)。SMILETrack取得了所有方法中最高的准确率,MOTA为81.06,而80.5,是所有方法中准确度最高的。在接下来的消融研究中,这是在准确率最高的设定下进行的测试。
消融
首先是SLM的有效性。我们比较了在关联的每个阶段采用或不采用外观信息(SLM)的准确性。我们也使用普通的SLM来代替第二阶段的多模板SLM。因此,如下表所示,采用SLM的模型只有在置信度较高的第1阶段才有最高的准确率,说明基于置信度的外观信息的使用是合适的。
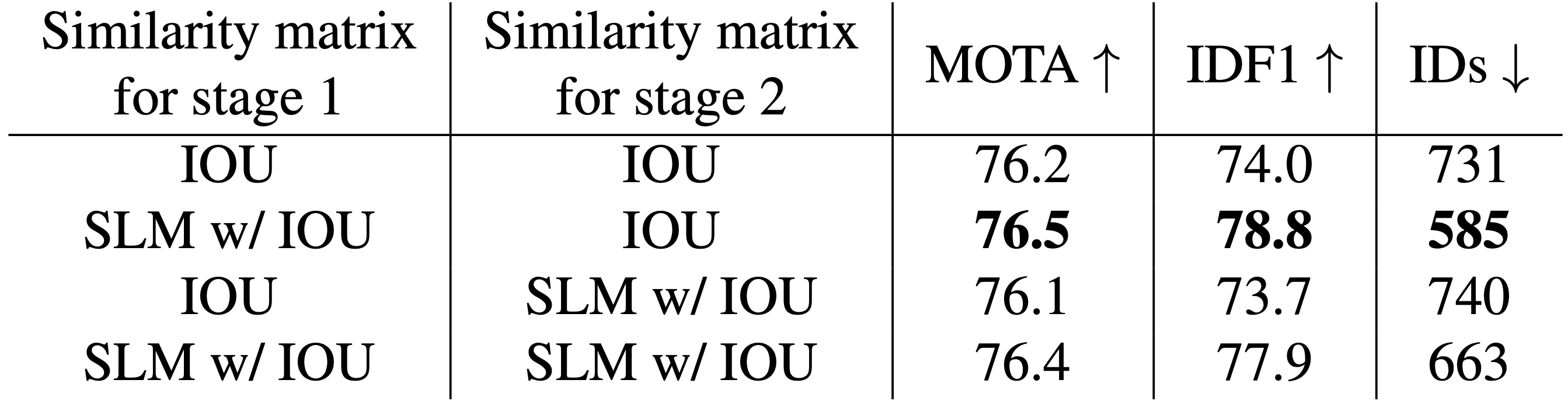
最后,对门函数和有无多模板-SLM进行了比较。基于一个将运动信息(IoU)和外观信息(SLM)用于阶段1和阶段2的模型,比较了将阶段2改为多模板-SLM或在两个阶段都采用门函数的结果。可以看出,当采用门函数或多模板-SLM时,准确性有所提高。采用这两种方法的模型在消融方面达到了最高的精度,证明了该方法的优越性。

印象
尽管过去已经引入了几种跟踪方法,但SoTA模型似乎是一个相当简单的机制。没有提到预处理,如相机抖动补偿,或后处理,如全局链接以补偿跟踪中断。尽管如此,似乎有必要验证SoTA的实现是因为ByteTrack方法和基于注意力的连体网络起了作用,还是因为检测器PRB的良好性能。
摘要
我们引入了一种名为SMILETrack的MOTChallenge SOTA方法。它继承了ByteTrack的优点,即在检测的置信度上进行两阶段的关联,并通过使用带有Attention的连体网络提取稳健的外观特征来提高准确性。在低置信度关联中使用多模板-SLM和门控函数对有问题的外观特征进行了适当的处理,以减少准确性的损失。
作为一个挑战,这种方法比JDE模型要慢,因为它是一个SDE模型。他们计划考虑能够改善这种权衡的方法。我们期待着未来的发展。



与本文相关的类别

