
Cal-QL:高效的在线微调、离线强化学习,注重先验学习。
三个要点
✔️ 对离线强化学习+在线微调挑战的实验研究
✔️ 提出一种用于预训练的离线强化学习方法 Calibrated Q-Learning (Cal-QL),该方法在讨论研究结果的基础上改进了现有方法
✔️ 离线强化学习学习 + 在线微调场景,取得比现有方法更好的性能。
Cal-QL: Calibrated Offline RL Pre-Training for Efficient Online Fine-Tuning
writtenby Mitsuhiko Nakamoto, Yuexiang Zhai, Anikait Singh, Max Sobol Mark, Yi Ma, Chelsea Finn, Aviral Kumar, Sergey Levine
(Submitted on 9 Mar 2023 (v1), last revised 20 Jun 2023 (this version, v2))
Comments: project page: this https URL
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
导言
在深度学习技术的实际应用中,通过大规模数据对模型进行预训练以实现个性化应用的微调框架已显示出其有效性。 在图像识别和自然语言处理领域,大规模图像模型(如 Imagen)和大规模语言模型(如 ChatGPT)已经开发出来,不仅带来了产业发展,也为日常生活带来了便利。
为了应对这一趋势,近年来,强化学习领域一直在积极研究一个框架,利用离线强化学习技术从静态数据中学习策略,在目标环境中以最少的额外交互预训练和微调策略。
一旦这种技术得到确立,预计深度学习技术将进一步应用于自动驾驶和医疗机器人等领域,因为在这些领域中,与环境的交互次数在成本和风险方面都是有限的。
本研究的重点是作为 先验学习的离线强化学习。 如第一个要点所示,本研究包括以下三个部分。 (1) 通过实验调查使用现有离线强化学习方法进行预训练的性能和挑战。 (2) 提出简单的改进建议,以克服调查中发现的挑战。 (3) 通过实验验证所提方法作为预学习方法的有效性。 本文在解释了离线强化学习的基本原理后,将逐步说明上述三点。
离线强化学习
离线强化学习的目的是,在不与环境进行额外交互的情况下,基于从某种措施($\pi_\beta(a|s)$)中收集的交互数据 $D = \{s_i,a_i,r_i,s'_i\}_{i=1}^{n}$,学习最优措施。 由于无法与环境交互,因此无法收集数据中不存在的其他状态-动作对。 因此,无法对数据中不存在的状态-动作对的 Q 值高估等问题进行纠正。 这种由数据中不存在的状态-动作对引起的问题被称为分布外(OOD)问题,是离线强化学习中最大的挑战。 现有的 OOD 问题对策可分为两大类:保守方法和对措施施加约束的方法。 在本文中,我们提出了一种基于保守方法的方法,并对其进行了详细说明。
保守方法
如前所述,为了防止高估 Q 值,该方法通过折现来估算 Q 值,从而使估算的 Q 值成为真实价值函数的下边界。
从不会高估 Q 值的意义上讲,这种方法是保守的。 保守Q 值学习(CQL)是一种具有代表性的保守方法,本研究也对其进行了讨论。 下面将解释 CQL 与使用 Q 函数的常规方法之间的区别。 我们假设 Q 函数由参数 $\theta$ 参数化。
・传统方法
$$\min_\{theta} \frac{1}{2} (Q_{\theta}(s, a) - \mathrm{B}^{\pi}Q(s, a))^2$$
其中,$\mathrm{B}^{\pi}$ 是度量($\pi$)的预期贝尔曼算子,目标函数是估计度量($\pi$)的值函数问题。
・CQL
$$\min_{theta} \underbrace{alpha(\mathbb{E}_{(s, a)\sim \pi}[Q_{\theta(s, a)}] - \mathbb{E}_{(s, a)\sim D}[Q_{\theta(s, a)}])}_{penalty term} + \frac{1}{2} (Q_{\theta}(s, a) - \mathrm{B}^{\pi}Q(s, a))^2$$
在这里,惩罚项限制了度量的 Q 函数预期值($\pi$)不能偏离数据分布的 Q 函数预期值。 这意味着要求 Q 函数是保守的,以防止高估数据中没有的状态行为 。 CQL 论文中的定理 3.2 证明了由上述目标函数估计的 Q 函数的期望值$\pi$是真正的$\pi$值函数的下限。 有兴趣的读者请看
限制$pi$度量的方法
该方法在进行优化的同时施加约束,以确保要学习的策略($\pi$)不会明显偏离生成数据的策略($\pi_\beta$)。 约束可以通过多种方式引入,最常见的是使用 KL-发散,它可以测量分布之间的距离。 约束测量方法包括 IQL、 AWAC 和 TD3-BC�
调查

设置
使用现有的离线强化学习方法(CQL、IQL、AWAC 和 TD3-BC)进行预训练和微调,并比较微调期间的性能。 用于比较的基准是一项操作任务,该任务以图像为输入,拾取一个物体并将其移动到特定位置。
结果
从图 1 中可以看出以下两点。
- 基于约束的方法、IQL、AWAC 和 TD3-BC 的学习速度都很慢。
- 保守方法 CQL 在 学习的早期阶段表现出明显的性能下降,尽管最终的学习效果良好。
审议

在本文中,我们认为 CQL 是一种很有前途的预训练方法,因为它的最终性能很高,我们还讨论了 CQL 面临挑战的原因:它在早期微调阶段的性能不佳。
在保守方法中,由于惩罚项的存在,Q 值估计总体上较小。 在使用 Q 函数选择行动时,即使值标度是错误的,只要能学习到行动之间的大小 Q 值关系,就能在推理过程中选择最佳行动。
但是,一旦开始在线微调,Q 值函数就会恢复到实际值标度[图 2]。 使用一个与实际 Q 值相比被低估的 Q 值作为初始值,在线执行的次优行动的值 在 学习的早期阶段就会被 估计得相对较高,原因很简单,因为它已经恢复到了实际规模 。他们认为, 这将 导致策略学习以次优行为为目标,从而导致性能低下(无法学习)。

作为支持这一假设的证据,他们绘制了 CQL 通过预研究和微调估算出的平均 Q 值和性能[图 3]。 微调从 50k 步开始,可以观察到平均 Q 值急剧上升,性能急剧下降。
技术
上述实验证实了使用保守方法进行预训练时的 "未学习 "现象,即 Q 函数的规模变得比实际规模小,这使得学习过程不稳定,因为次优行动在在线微调过程的早期阶段具有相对较高的值。在本文中,我们提出了一种更有效的预学习方法,通过估计 Q 函数,使其相对于实际 Q 函数保守,但高于次优措施的 Q 函数,从而避免这种现象。上述 "取值高于次优度量的 Q 函数 "的 Q 函数定义为 "校准",如下所示
定义 4.1 校准
如果对于任意状态 $s$, $\mathbb{E}_{a\sim \pi}[Q^{\pi}_\theta(s, a)]\geq \mathbb{E}_{a\sim \mu}[Q^{\mu}(s, a)]$ 是成立的。
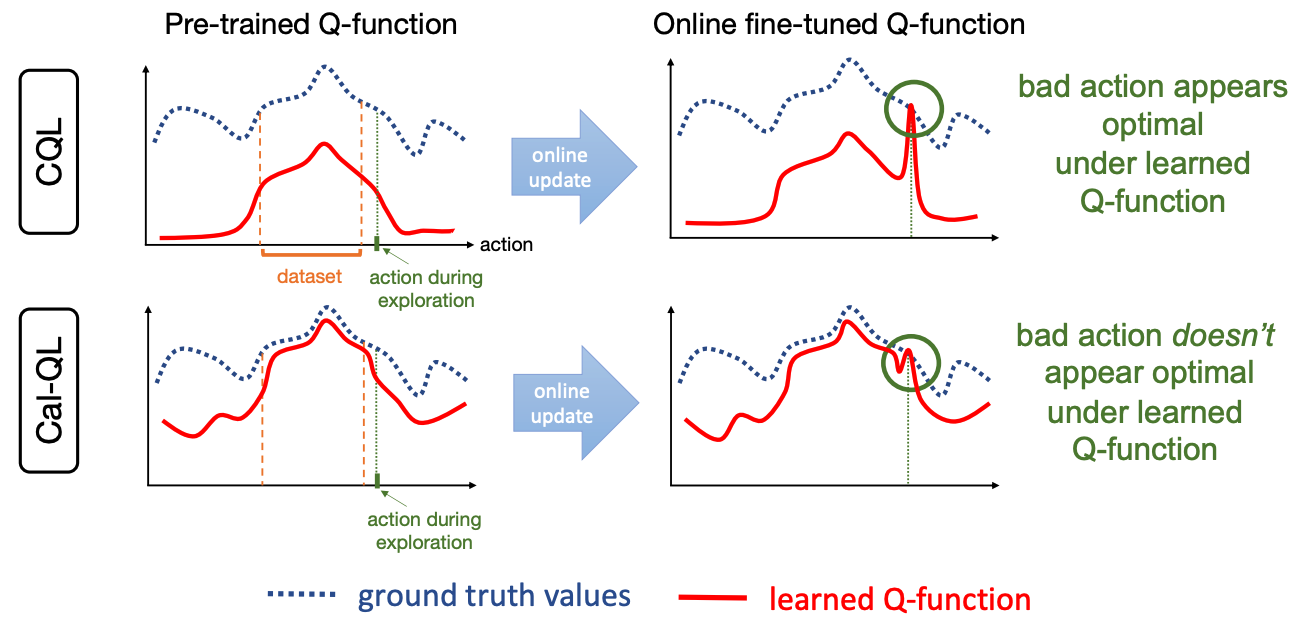
如果对所有次优度量 $\mu$ 的估计 Q 函数进行校准,就能保证 Q 函数为具有次优行为的度量设定上限。 因此,次优行为的 Q 值永远不会超过预训练估计的最大 Q 值,从而防止 "未学习"。[图 4]
Cal-QL
作为一种在预训练中实现校准的实用方法,我们提出了校准 Q-学习(Cal-QL)算法,它可以对给定的次优度量 $\mu$ 进行校准。 在 Cal-QL 中,CQL 的惩罚项修改如下。
$$alpha (\mathbb{E}_{s\sim D a\sim \pi}[\max(Q_\theta(s, a), V^{mu}(s))] - \mathbb{E}_{s, a\sim D} [Q_\theta(s, a)])$$
我们可以看到,这个目标函数同时实现了$\mu$校准和保守性。 因为 $\max\{Q_{\theta}(s, a), V^{\mu}(s)\}$ 有两个值,分别是 $Q_{\theta}(s, a)$ 和 $V^{\mu}(s)$,所以我们要考虑在每种情况下惩罚对学习的影响。
- 当$\max\{Q_{\theta}(s, a), V^{\mu}(s)\} = Q_\theta(s,a )$,即 $Q_{\theta}(s,a)>V^\mu(s)$,并且对 $\mu$进行校准时,惩罚项与 CQL 中的惩罚项相同,并且通常的保守主义也起作用。保守主义起作用。
- 当$max\{Q_{\theta}(s, a), V^{\mu}(s)\} = V^{\mu}(s)$,即估计的Q值低于次优度量的值函数且 校准没有实现时,惩罚项为$\alpha (\mathbb{E}_{s\sim D a\sim \pi}[V^{\mu}(s)]) - \mathbb{E}_{s, a \sim D} [Q_\theta(s, a)])$ 。 这种惩罚会导致参数更新,使 $Q_{\theta}(s, a)$ "赶上"$V^\mu$,从而实现校准。
总之,参数经过优化后,当 $Q_\theta(s, a)$ 经过校准时,保守主义就会起作用,而当 $Q_\theta(s, a)$ 没有经过校准时,校准就会实现。 由此可见,只要对 CQL 目标函数稍作改动,保守主义和校准就能兼容。
本文的定理 6.1 从理论上证明,在在线微调过程中,该目标函数可以改善 riglet 的阶次。 有兴趣的读者也可以参阅本节。
在实施过程中,价值函数 $V^{\pi_\beta}$ 是由收益的经验平均值近似得到的,行为度量 $\pi_\beta$ 是参考度量。
试验
在实验中,我们与现有的离线预训练和微调方法进行了比较,这些方法适用于各种任务。
基准

- 蚂蚁迷宫:四足机器人必须到达目标的迷宫任务 [图 5]。
- 弗兰卡-基钦:厨房的工作环境[图 5]。
- 灵巧:抓取物体和开关门的操作任务 [图 5]。
比较法
- 利用现有离线 RL 进行预学习 + 利用 SAC 进行微调
- 离线 RL 方法:IQL、CQL
- 离线强化学习 + 现有的在线微调方法
结果

上图显示了每个基准在微调过程中的性能比较。 可以看出,在许多任务的在线微调过程中,Cal-QL 提高了收敛速度和最终性能。
为了完全防止 "不学习",有必要校准所有次优度量,但在上述实验中,只对行为度量进行了校准,可以看出,仅此一项就稳定并提高了学习效率。 这些实验还证实,用神经网络而不是经验平均值来估算值时,性能并没有明显下降,而且性能对参考测量值函数的估算误差并不敏感。
摘要
本期,我们关注作为预训练方法的离线强化学习,并介绍了一篇论文,该论文提出了一种离线强化学习方法,可以实现高效的微调。 这一想法得到了实验的支持,实现起来也很简单,其有效性也得到了实验的证实。 离线强化学习+在线微调是一个具有高度实用性的热门话题,研究者们对它的研究与日俱增。 今后请继续关注这一关键词。



与本文相关的类别

