
先进的基于离线模型的强化学习! 用真实的机器人从图像数据中解决任务?
三个要点
✔️我们提出LOMPO,一种新的基于离线模型的RL方法论
✔️关于潜伏空间不确定性潜在空间上的量化
✔️我们能够解决现实世界机器人的任务
Offline Reinforcement Learning from Images with Latent Space Models
written by Rafael Rafailov, Tianhe Tu, Aravind Rajeswaran, Chelsea Finn
(Submitted on 21 Dec 2020)
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI); Robotics (cs.RO)

首先
近年来,在线RL(强化学习)以及离线RL因其各种优势而备受关注。然而,重要的是使用图像作为真实世界机器人的输入来学习策略,而不是模拟。因此,在本文中,我们引入了一种名为基于离线模型的策略优化(LOMPO)的方法,该方法即使在使用图像作为输入时也可以学习策略。因为这种方法是基于模型的,它通过对环境中的过渡进行建模,然后根据建模进行策略优化,从而获得策略。下图是本文介绍的方法的整体流程,由于是离线RL,所以任务数据都是提前给定的。然后,通过提出的方法LOMPO来学习策略,最后用机器人对其性能进行评估。
那么,为什么基于离线模型的RL如此困难,尤其是当输入是图像时?到目前为止,基于离线模型的RL是用来量化训练模型产生的观测值的不确定性(如取预测值的方差),当不确定性较大时,对观测值进行惩罚,以避免外推误差。和未知观测值引起的误差(分布外误差)。但是,由于生成的图像维度较高,这种方法效率低下,不适合图像。因此,所提出的方法LOMPO可以学习潜伏空间中的动态,并量化潜伏空间中的不确定性,因此即使输入的是图像,也可以学习策略。现在,小编就为大家介绍一下详细的方法。
技巧
最终目标是获得一个基于离线模型的RL,可以处理图像作为高维输入。如上所述,以往基于离线模型的RL对生成的观测数据的不确定性进行了量化,但生成图像并量化不确定性的成本很高,也不实用。因此,所提出的方法LOMPO可以学习一个latent dnamics模型(在latent空间上的动力学模型),并在latent空间上通过合集量化不确定性。换句话说,LOMPO在低维空间学习动态,而不是在图像等高维空间学习动态。首先,将原问题的MDP(Markov Decision Process)定义为不确定性惩罚的潜伏MDP,即在奖励的基础上加上不确定性惩罚的MDP,然后,由于输入是图像做出不确定性惩罚的POMDP(Partial Observable MDP),并在此基础上优化政策和潜伏的dyanmics模型。下面我将详细解释这个流程。
论模型不确定性在潜空间上的量化作用
为了量化潜伏空间的不确定性,我们将围绕MDP进行整理。首先,我们将潜伏空间$\mathcal{S}$上的MDP定义为$M_{\mathcal{S}}=(\mathcal{S}, \mathcal{A}, \mathcal{T}, r, \mu_{0}, \gamma)$,同理,我们将潜伏空间上的估计MDP定义为$\widehat{M}_{\mathcal{S}} = (\mathcal{S}, \mathcal{A}, \widehat{\mathcal{T}}, r, \mu_{0}, \gamma)$。让$\widehat{T}(s'|s, a)$成为一个潜在的动力学模型。所提出的方法的最终目标是找到$\widehat{M}_{\mathcal{S}}$。在在$\widehat{M}_{\mathcal{S}}$中,同时使$M_{\mathcal{S}}$中的报酬最大化。为此,我们首先学习$M_{\mathcal{S}}$和$\widehat{M}_{\mathcal{s}}$。以创建一个不确定性惩罚的MDP $\widetilde{M}_{\mathcal{S}}=(\mathcal{S}, \mathcal{A}, \widehat{T}, \tilde{r}, \mu_{0}, \gamma)$。这里$\tilde{r}$表示为$\tilde{r}(s,a)-\lambda u(s,a)$,其中$u(s,a)$是不确定度估计器。那么,在不确定性惩罚的MDP中,政策$pi$的收益是实际MDP中收益的下限,收益的差异取决于潜动态模型的误差。如果你对详细的定义感兴趣,请参考本文。在本文中,我们使用这种不确定性惩罚的MDP来训练模型和优化策略。
论利用不确定性惩罚的ELBO对Latent Model和Policy的优化作用
在本节中,我们将根据上一节介绍的不确定性惩罚MDP,介绍潜动力模型和政策的优化。首先,基于不确定性惩罚的MDP,不确定性惩罚的POMDP $\widehat{M} = (\mathcal{X}, \mathcal{S}, \mathcal{A}, \widehat{T}, D, \tilde{r}, \mu_{0}, \gamma)$的定义。这里,$\mathcal{X}$代表图像空间。动态$\widehat{T}(s_{t+1}|s_{t}, a_{t})$,政策$pi(a_{t}|x_{1:t},a_{1:t-1})$如下。
$$\widehat{q}\left(s_{1: H}, a_{t+1: H} \mid x_{1: t+1}, a_{1: t}\right)=\prod_{\tau=0}^{t} q\left(s_{\tau+1} \mid x_{\tau+1}, s_{\tau}, a_{\tau}\right) \prod_{\tau=t+1}^{H-1} \widehat{T}\left(s_{\tau+1} \mid s_{\tau}, a_{\tau}\right) \prod_{\tau=t+1}^{H} \pi\left(a_{\tau} \mid x_{1: \tau}, a_{1: \tau-1}\right)$$
而从这个$\widehat{q}$中,我们可以将报酬的期望值表示如下。

详细介绍请参考本文。这里特别重要的是,不确定性惩罚的MDP下的预期报酬值表示为真实MDP下的预期报酬值的下限。那么,利用这个公式,我们可以将下面的公式(见),也就是正常POMDP下的ELBO(Evidence Lower Bound),表示为:。
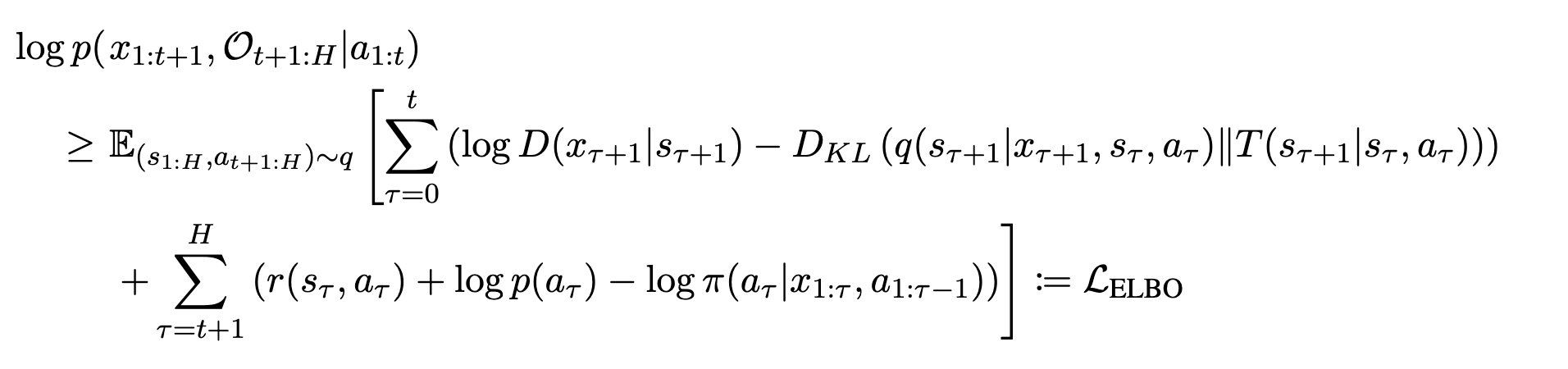
如下图所示,它可以做成一个与$\widetilde{\mathcal{L}}_{ELBO}$和$\mathcal{L}_{ELBO}$有关的方程,这就是不确定度惩罚的MDP中的ELBO。
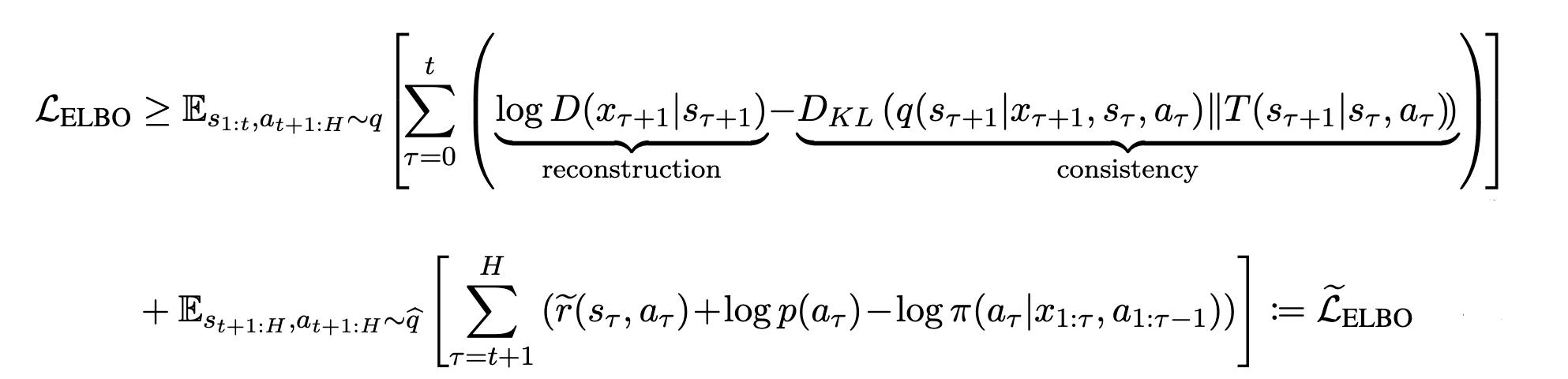
同样,需要注意的是,这个$\widetilde{\mathcal{L}}_{ELBO}$是$\mathcal{L}_{ELBO}$的下限。利用这一点,我们可以优化潜动力模型和政策。在下一节中,我将告诉你如何在实践中实施该系统。
关于LOMPO的执行情况
下图为该款车型的整体情况。图像通过编码器$E_{\theta}$映射到潜伏空间,并表示为$s_{t}$,然后通过解码器$D_{\theta}$重新映射到原始图像上。那么,如前文ELBO公式所示,潜动力模型$\widetilde{T}(s_{t}|s_{t-1},a_{t-1})$和推理$q(s_{t+1}|x_{t+1},s_{t},a_{t})$的分布一定很接近。因此,这些模型是根据以下目标函数进行优化的。
$$\sum_{\tau=0}^{H-1}\left[\mathbb{E}_{q}\left[\log D\left(x_{\tau+1} \mid s_{\tau+1}\right)\right]-\mathbb{E}_{q} D_{K L}\left(q\left(s_{\tau+1} \mid x_{\tau+1}, s_{\tau}, a_{\tau}\right) \| \widehat{T}_{\tau}\left(s_{\tau+1} \mid s_{\tau}, a_{\tau}\right)\right)\right]$$
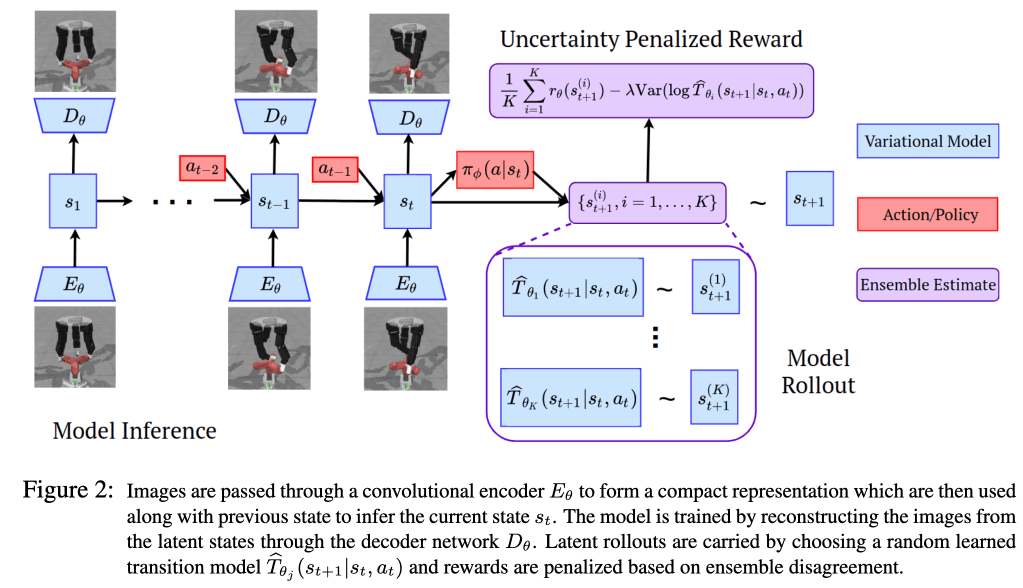
这里重要的是学习一个潜伏过渡模型的集合,即潜伏空间中的过渡模型,以获得不确定性惩罚的POMDP的不确定性。假设我们有K个模型$\{\widetilde{T}_{1}...\widetilde{T}_{K}\}$要学习的不确定性$u(s_{t}, a_{t})$定义为$u(s_{t}, a_{t})=Var(\widetilde{T}_{\theta_{i}}(s_{t}|s_{t-1}, a_{t-1)})\})$ ($i=\{1,...,K\}$).在优化上述目标函数时,我们对其进行训练,从潜动态模型的集合$\{\widetilde{T}_{1}...\widetilde{T}_{K}\}$中随机抽取样本。
接下来,我们关注的是政策的优化。本文在潜伏空间上学习政策$pi_{\phi}(a_{t}|s_{t})$和批评$Q_{\phi}(s_{t},a_{t})$。为此,我们准备了两个重放缓冲区$\mathcal{B}_{real}$和$\mathcal{B}_{sample}$。$\mathcal{B}_{real}$包含从真实数据中得到的$s_{t},a_{t},r,s_{t+1}$,状态使用真实数据集$x_{1:H}$来计算$s_{1:H} \sim q(s_{1:H}|x_{1:H},a_{1:H-1})$,可得如下。另一方面,在$\mathcal{B}_{sample}$。它包含了由训练好的前向模型的集合所得到的数据。这样做的回报是对不确定因素的制裁。
$$\widetilde{r}_{t}\left(s_{t}, a_{t}\right)=\frac{1}{K} \sum_{i=1}^{K} r_{\theta}\left(s_{t}^{(i)}, a_{t}\right)-\lambda u\left(s_{t}, a_{t}\right)$$
表示为
实验
本文的实验旨在回答以下四个问题。
- LOMPO是否能够在复杂的动态环境中解决任务问题。
- 与现有方法相比,LOMPO的性能有所提高。
- 数据集质量和规模的影响。
-. LOMPO可以用来对抗真实的机器人环境吗?
为了获得这些问题的答案,我们在本文中主要对以下基于机器人的任务进行了实验。

模拟结果
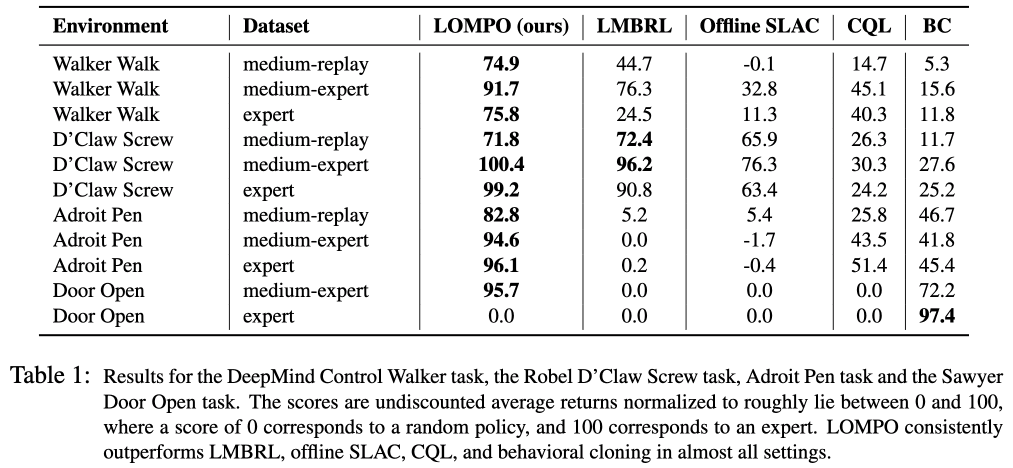
我们采用行为克隆(BC)、保守Q-learning(CQL)、离线SLAC和LMBRL作为与LOMPO的对比方法。结果如下表所示。下表中,medium-replay是测试在收集离线数据时,是否可以从一个不完整的数据集中学习策略,直到策略达到专家策略性能的一半。中专家是指在数据收集过程中学习到的策略的重放缓冲区的后半部分包含次优数据的数据集。最后,专家数据集代表了从专家政策中抽取的数据,但数据分布非常狭窄。下表的结果表明,所提出的方法LOMPO基本表现良好。但对于开门任务,BC表现出较好的性能,这是因为数据分布较窄的缘故。在专家数据集的情况下相比之下,D'Claw在Door Open任务上的表现优于BC,这说明它无法在数据分布狭窄的专家数据集上学习动力学模型。另一方面,专家数据集在D'Claw Screw和Adroit Pen任务上表现更好,说明该任务比Door Open任务简单,因此训练更成功。
真实世界的机器人实验
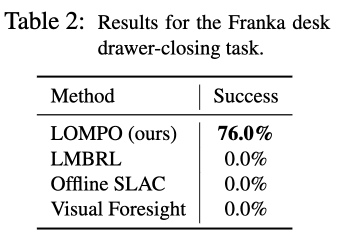
在这个实验中,我们使用一个真实的机器人来评估LOMPO。使用的机器人是Franka Emika Panda机器人手臂。如下图所示,只有LOMPO成功学习并解决了任务。相比之下,其他所有的比较方法都不能解决这个任务。

摘要
在这篇文章中,我们介绍了LOMPO,这是一个提出的方法,它可以使基于离线模型的RL从图像输入中学习。 离线RL是目前备受关注的领域,从图像中学习是一个非常重要的问题,当它应用于现实世界的机器人时。 这是一个非常重要的问题。 预计未来能够学习更复杂的任务。
要阅读更多。
你需要在AI-SCHOLAR注册。
或


与本文相关的类别




