
小的神经网络应该是Augmentation的网络!
三个要点
✔️ 提出NetAug(网络增强)以提高小型神经网络的准确性
✔️ 扩展网络以减轻欠拟合程度
✔️ 在图像分类和物体检测任务中持续提高性能
Network Augmentation for Tiny Deep Learning
written by Han Cai, Chuang Gan, Ji Lin, Song Han
(Submitted on 17 Oct 2021 (v1), last revised 24 Apr 2022 (this version, v2))
Comments: ICLR 2022
Subjects: Computer Vision and Pattern Recognition (cs.CV); Artificial Intelligence (cs.AI); Machine Learning (cs.LG)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
各种正则化技术(如数据增量和剔除)已被用于改善深度学习的性能,并取得了很大的成功。
然而,这些现有的正则化方法可能反而会损害小规模神经网络的性能,因为小规模的神经网络不太可能发生过度拟合。在本文介绍的论文中,提出了NetAug,一种增强网络而不是数据的方法,以提高小规模神经网络的性能。
结果包括小规模模型在ImageNet上的准确性提高了2.2%。
NetAug(网络扩增)
网络扩容的制定。
首先,让$W_t$为待训练的小(微小)神经网络的权重,$L$为损失函数。在训练过程中,权重被优化以最小化$L$。
$W^{n+1}_t = W^n_t - \eta\frac{partial L(W^n_t)}{partial W^n_t}$
这时,小的神经网络往往会陷入局部最优解,由于容量较小,其训练和测试性能比大的神经网络要差。
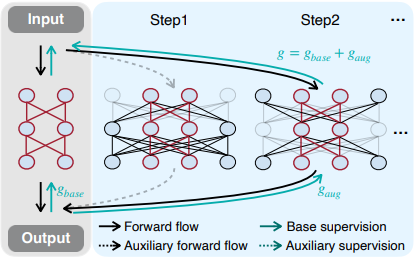
所提出的方法,即网络增强(Network Augmentation),引入了一个较大的神经网络的额外监督,以协助较小的神经网络的训练。
这可以说是与drop-out方法相反,后者只对网络的一部分进行预测,并将你要训练的小神经网络的宽度扩大,形成一个巨大的神经网络。
这个想法可以概括为下图所示。
那么,网络扩增中的损失函数$L_{aug}$就变成了
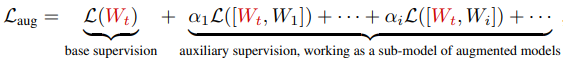
其中$[W_t,W_i]$代表你要训练的小型神经网络$W_t$和包含新权重$W_i$的扩展模型。
$alpha_i$是一个超参数,用于整合不同增强模型的损失。
关于增强的模型
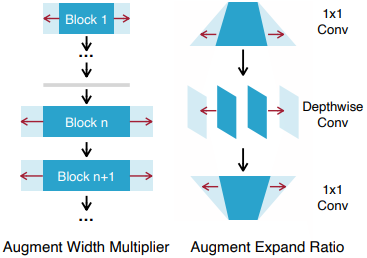
当对网络进行增强时,很难使增强的模型$[W_t,W_i]$独立于计算资源方面。因此,以选择最大模型的子网络的形式构建各种增强模型(见前述图中的步骤1和步骤2)。
这个想法与One-Shot NAS相似,但不同的是,重点是提高一个特定的小型神经网络的性能,而不是获得一个最佳的子网络。
此外,在网络加固过程中,加固是以增加模型的宽度的方式进行的。
学习过程
当训练一个增强的网络时,模型通过在每一步对一个子网络进行采样来更新。
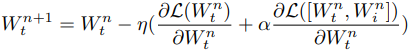
这里,$[W^n_t,W^n_i]$对应于每个学习步骤中采样的网络。增强部分的$W_i$以及待训练的小型神经网络的权重被更新。
请注意,在所有实验中,超参数$alpha$被固定为1.0。
学习和推理过程中的开销
首先,网络增强只发生在训练期间,所以在推理期间没有开销。对于学习时间,实验表明,学习时间只增加了16.7%。
这是由于网络增强的目的是用于训练小型网络,数据加载和通信成本在训练期间的计算处理上占主导地位。
实验装置
实验中使用的图像分类数据集和训练设置如下
- ImageNet:16个GPU,150个epochs,批次大小2048。
- ImageNet-21K-P(winter21版本):16个GPU,20个epochs,批次大小2048。
- Food101:用ImageNet中的预训练权重进行初始化,在4个GPU上进行50个epochs的微调,批次大小为256。
- 花卉102:与食品101相同。
- 与Cars:Food101相似。
- Cub200:与Food101相同。
- 与Pets:Food101相似。
此外,图像检测数据集如下。
- 帕斯卡尔VOC:8个GPU,批次大小64,200个历时。
- COCO:16个GPU,120个epochs,批次大小为128。
实验结果
首先,ImageNet的结果如下
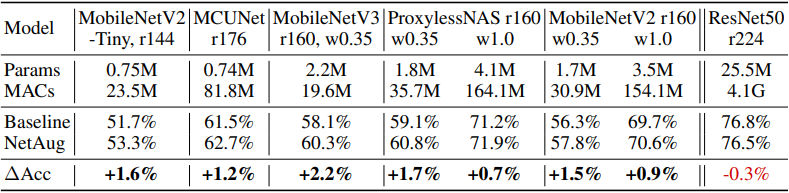
总的来说,人们发现,对于不同的神经网络架构,所提出的方法能够持续改善小型神经网络的准确性。
请注意,网络增强是一种应该适用于小型神经网络的方法,所以具有足够模型容量的ResNet50不会导致准确性的提高。准确率与训练历时数的关系图也显示在下面。
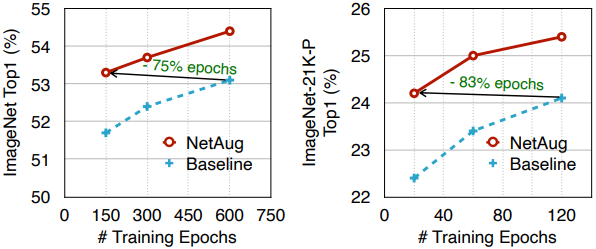
图中显示,与没有增强的情况相比,达到相同精度所需的训练历时数明显减少。
与知识蒸馏法(KD)比较
接下来,与使用Assemble-ResNet50作为监督模型的知识提炼的比较如下所示。

总的来说,与知识蒸馏法相比,精确度有了很大的提高。研究还发现,所提出的方法可以与知识蒸馏法相结合,在这种情况下,精确度会进一步显著提高。
与正则化方法的比较
然后将结果与辍学和数据增强等方法进行比较,这些方法导致大型神经网络的准确性提高,具体如下。
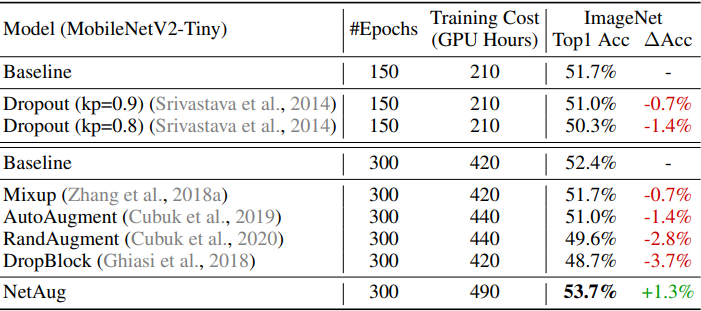
一般来说,小型神经网络受欠拟合的影响要大于过拟合,所以防止过拟合的方法会产生反作用。
相反,所提出的网络增强方法是为了缓解小型神经网络的欠拟合,所以将其应用于大型神经网络会产生反作用。这些都显示在下面的学习曲线中。
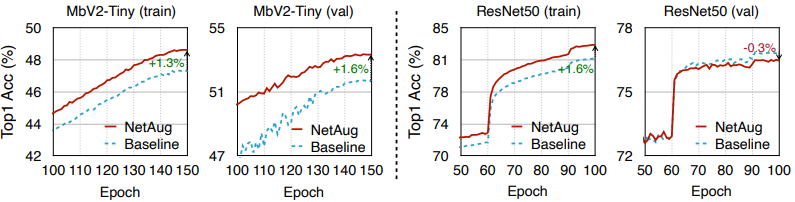
该图显示了一个小型神经网络(MobileNetV2-Tiny)和一个大型神经网络(ResNet50)的训练/评估准确率图。
如前所述,在小型神经网络中,训练/值的准确性都有所提高,而在ResNet中,值的准确性有所下降,显示出过拟合的迹象。
转移学习的结果
最后,在ImageNet中预训练的模型的转移学习结果如下。
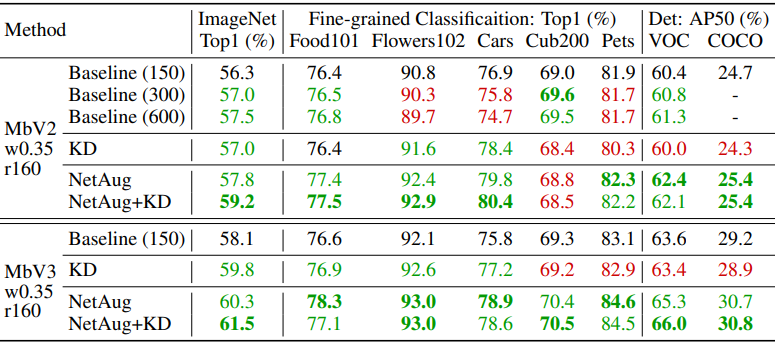
与基线(Baseline(150))相比,更好的结果显示为绿色,更差的结果显示为红色。总的来说,结果表明,网络增强在过渡学习期间也显示出良好的效果。
所提出的方法在较小的分辨率下也表现良好,导致推理效率的提高。下图显示了不同分辨率下的物体检测结果。
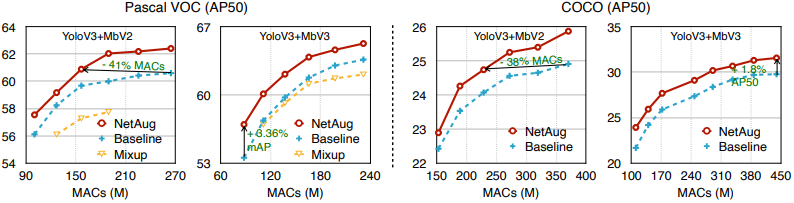
该图显示,在较小的分辨率下也能达到相当的性能。
摘要
本文介绍了Network Augmentaion,这是一种改善容易出现欠拟合的小型神经网络性能的方法。该方法被证明能够持续提高图像分类和物体检测等任务的准确性。
现有的正则化方法主要是为了处理大型神经网络的过拟合问题,但鉴于小型模型可能用于边缘设备等,这种针对小规模神经网络的改进方法也很重要。



与本文相关的类别
