代理人应该在什么时候探索?
三个要点
✔️ 关注何时进行搜索,而以前只考虑搜索的数量
✔️ 增加变量的数量可以灵活地进行搜索设计
✔️ 关于各变量影响的实验
When should agents explore?
written by Miruna Pîslar, David Szepesvari, Georg Ostrovski, Diana Borsa, Tom Schaul
(Submitted on 26 Aug 2021 (v1), last revised 4 Mar 2022 (this version, v2))
Comments: Published on arxiv.
Subjects: Machine Learning (cs.LG); Artificial Intelligence (cs.AI)
code:
本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
介绍
强化学习已经在多个领域取得了巨大的成功,包括棋盘游戏、视频游戏和机器人控制,但探索问题仍然是一个核心挑战。
强化学习的一个基本考虑是探索(exploit)和利用(exploit)之间的平衡。问题是如何在从我们拥有的信息中采取最佳选择,或出去收集信息以找到更好的选择之间取得平衡。
其中,探索的 "量 "的问题,即应该做多少探索,一直是很多研究的主题,包括熵最大化的强化学习,如epsilon-ready和SAC,它们也被用于DQN中。然而,关于何时搜索的问题,还没有太多的研究。在这篇文章中,我们介绍了一篇由DeepMind研究团队撰写并被接受在2022年ICLR上发表的论文,该论文解决了何时搜索这个问题。
技术
搜索方法
第一个假设是,该方法有一个搜索模式和一个利用模式。开发模式是在当前价值函数范围内采取最佳行动,而搜索模式则是为了寻找更好的行动。本文在搜索模式上考虑了两种类型的搜索方法:一种是统一探索,顾名思义,完全随机选择行动,例如ε-greedy。另一种是内在动机搜索,这是RND中使用的方法。
搜索的颗粒度
下一步是考虑搜索的颗粒度。这可以归纳为四种模式
阶梯水平 (C)
最常见的设置决定了是否每一步都要进行搜索。一个突出的例子是epsilon-greedy。
实验水平(A)
所有的行为都是在探索性模式下确定的,并在政策性关闭类型中学习。这也是一种常见的方法,与那些使用内在奖励的方法相呼应。
剧集级别(B)
选择是否探索每一集。
在外显期内(D、E、F、G)
这种方法介于步骤层面和偶发层面之间。探索持续了几个步骤,但并没有延伸到整个情节。这是研究最少的环境,本研究主要涉及这一环境。
这些方法中的每一种都在下图中得到了说明。在左边,粉红色代表探索模式,蓝色代表开发模式。右图显示了探索量和探索长度之间的关系。px显示了在每个动作中包含多少探索,而medx显示了一旦进入探索模式,就会持续进行多少探索。皮肤颜色所包围的区域对应的是episodic内,从这一点可以看出,该方法是相当灵活的。

切换方法
我们现在将看看在搜索和开发模式之间的切换。在算法上主要有两种可能性。
盲目切换
这是最简单的方法,只考虑开关的频率,不考虑状态。例如,可以准备一个计数器并以恒定的速率进行切换,或者考虑采用概率选择方法,如ε-greedy。
知情切换
该方法利用代理人的内部状态进行更高层次的决策,由两部分组成。首先,代理发出了一个每一步都有标量值的触发信号。第二,根据该信号做出模式切换的决定。作为一个实际的例子,本文使用一个被称为价值承诺差异的量,由以下公式表示,作为触发信号。
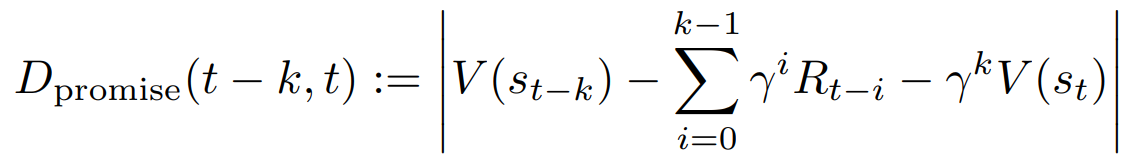
这代表了k步之前的预测和实际行动之后的实现值之间的差异,该方法是这样的:如果这个值很高,即预测不起作用,它就切换到探索模式。
另一个重要的问题是,在一集的开始,初始模式应该是什么。当然,这取决于要适应的任务,但在许多情况下,人们认为从开发模式开始是有效的。这是由于初始状态邻域被访问的次数相对多于其他状态,因此预测更准确。
实验
设置
使用了七个雅达利游戏。其中,最困难的,如蒙特祖马的复仇,已经被选中。
R2D2被选为主要的强化学习算法。这是一个分布式的DQN,使用RNNs来表示Q-函数。我们将这个R2D2与一个包含了上面介绍的搜索粒度和模式切换算法的基础进行比较。当然,模式切换只在训练期间进行,而贪婪策略则在评估期间使用。
基准线
我们考虑了以下四种基线,以比较表内法和其他方法
- 所有搜索模式(实验-水平-X)。
- 所有开发模式(实验-水平-G)
- ε-greedy ε=0.01 (步骤级-0.01)
- 匪徒元控制器在剧情之间进行选择和修复(剧情级别-*)。
对于上述每一种情况,都有统一搜索(X_U)和内在动机搜索(X_I)的搜索模式。

图中比较了这些基线与所提出的方法的外延(红色实线)。左边两幅图显示的是统一搜索的情况,而右边两幅图显示的是内生性激励搜索的情况。可以看出,在这两种情况下,表内的情况都比较好。
表内变体
可以考虑对 "内 "的许多变体。接下来将列举它们。括号中的符号对应于表示方法的符号。
- 如何搜索:统一搜索(XU),内在动机搜索(XI)。
- 搜索周期:固定(1,10,100),由Bandit自适应选择(*),或由切换到搜索模式的相同算法处理(=)。
- 切换:盲目、知情
- 开发模式的持续时间:。
- 用于盲目切换。固定的(10,100,1000,10000),随机的(0.1,0.01,0.001,0.0001),通过强盗的适应性选择(n*, p*)
- 对于知情的转换。目标利率的选择。固定的(0.1, 0.01, 0.001, 0.0001),强盗的适应性选择(P*)。
- 开始时的模式:开发(G)或搜索(X)。
基于这些,有一种方法表示如下。

这表明搜索是均匀进行的,搜索模式是100步连续的,由Bandit选择的概率性盲切换,初始模式是利用。
业绩
我们现在要看一下这种表象内的变化是如何影响探索性表现的。下面的数字显示了随着剧情的发展,探索的数量如何变化(第1栏和第3栏)。训练的开始也用一个正方形表示,训练的结束用一个X表示。值得注意的是,尽管统一搜索和内在动机搜索是非常不同的搜索方案,但这两张图却很相似。

开关
然后对切换进行比较。

左图和中图分别显示了在盲目和知情模式切换时,开发(蓝色)和探索(红色)的分布情况。可以看出,在知情的情况下,探索的密度是有变化的。右边的图显示了每种方法的收益,最后知情者表现更好。
开始时的模式
接下来,我们看一下这一集开始时模式的影响。
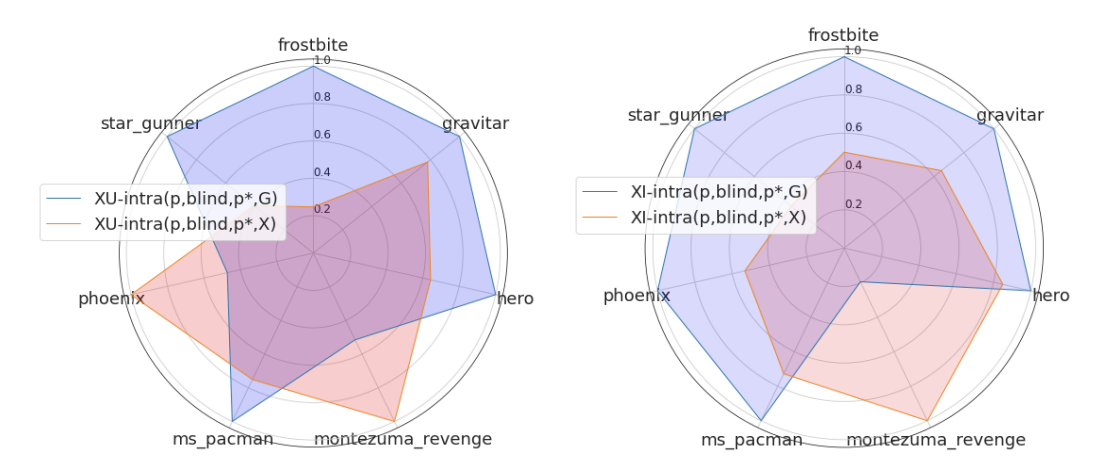
上图显示了七个游戏中每个游戏的搜索开始(红色)和利用开始(蓝色)的回报,左边是统一搜索,右边是内部激励搜索。基本上,可以看出,剥削开始的情况比较好。这可以解释为剧情开始时的状态被访问得更频繁,预测也更稳定。然而,在诸如《蒙特苏马的复仇》这样需要长时间探索的游戏中,探索开始时的表现更好,你需要对你所适应的环境有充分的了解。
盲目切换中的模式切换
最后,比较了盲切换中模式切换方法的计数和概率公式。
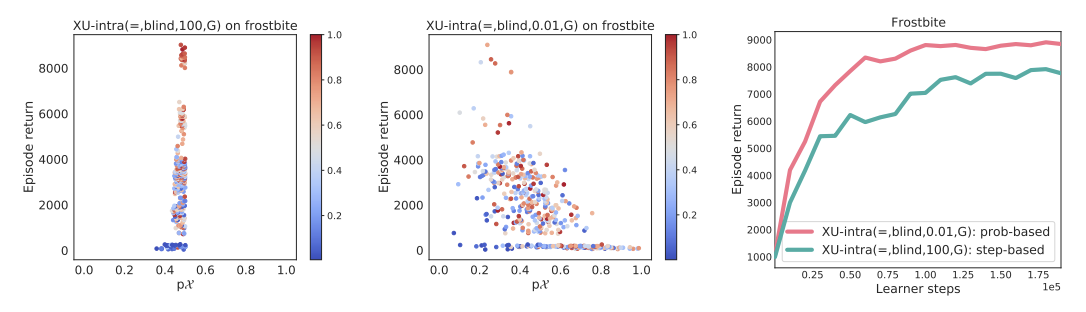
左边的两个数字显示了每集的搜索量和回报率之间的关系。随着训练的进行,点的颜色会从蓝色变为红色。左图(计数公式)显示,搜索费用在各集之间没有明显的变化,而且随着各集的进展,回报率稳步上升。在中间(建立公式),可以读出各集之间的搜索费用有很大的变化,而且随着探索的增多,回报率会下降。右边的图显示了这些方法的收益,表明概率公式的表现更好。
摘要
在这篇文章中,我们介绍了一篇论文,该论文深入探讨了代理人搜索的 "何时 "方面。本文作者提出的表内区分,使得代理探索的设计比以前更加灵活。然而,挑战在于,这只限于探索和开发模式之间有明确区别的情况。目前,连续值控制的主流方法是基于熵值最大化的强化学习,如SAC,这些算法不切换模式,可以说在某种意义上是一直在探索。未来的研究有望将这一内省概念发展到包括SAC和其他。



与本文相关的类别






