
SegFormer: Segmentation With Transformer
三个要点
✔️ 开发了一个基于Transformer的分割模型,SegFormer,。
✔️ 编码器使用层次化的Transformer来输出多尺度特征,而解码器则使用一个简单的MLP来结合每个输出,以输出高级的表示数量。
✔️ SegFormer记录了SOTA,尽管与传统方法相比其计算成本较低。
SegFormer: Simple and Efficient Design for Semantic Segmentation with Transformers
written by Enze Xie, Wenhai Wang, Zhiding Yu, Anima Anandkumar, Jose M. Alvarez, Ping Luo
(Submitted on 31 May 2021 (v1), last revised 28 Oct 2021 (this version, v3))
Comments: Accepted by NeurIPS 2021
Subjects: Computer Vision and Pattern Recognition (cs.CV); Machine Learning (cs.LG)
code:

本文所使用的图片要么来自论文、介绍性幻灯片,要么是参考这些图片制作的。
背景
语义分割是计算机视觉的主要研究领域之一,有多种应用。与普通的图像分类不同,它在像素层面上进行分类。目前,主要的模型是基于FCN(全连接网络),存在各种推导。此外,由于其与图像分类的亲和力,随着图像分类的进展,更好的骨干架构也被研究出来。另一方面,最近Transformer在自然语言处理领域的成功,导致人们试图将Transformer也应用于图像识别。因此,在本文中,我们开发了SegFormer,一个基于Transformer的分割模型,考虑到了效率、准确性和鲁棒性。
技术
SegFormer包括(1)一个分层的Transformer编码器,产生高分辨率和低分辨率的特征;(2)一个轻量级的MLP解码器,结合这些多尺度的特征,产生一个分割掩码,如下图所示。在这里,给定一个$H\times W\times 3$的图像,它被分割成$4\times 4$的斑块。然后这些被用作编码器的输入,编码器输出{$1/4, 1/8, 1/16, 1/32$}比例的原始图像大小的特征。这些特征被放入解码器,最终预测出一个$frac{H}{4} \frac{W}{4} \times N_{cls}$的分割掩码。然而,$N_{cls}$是类别的数量。
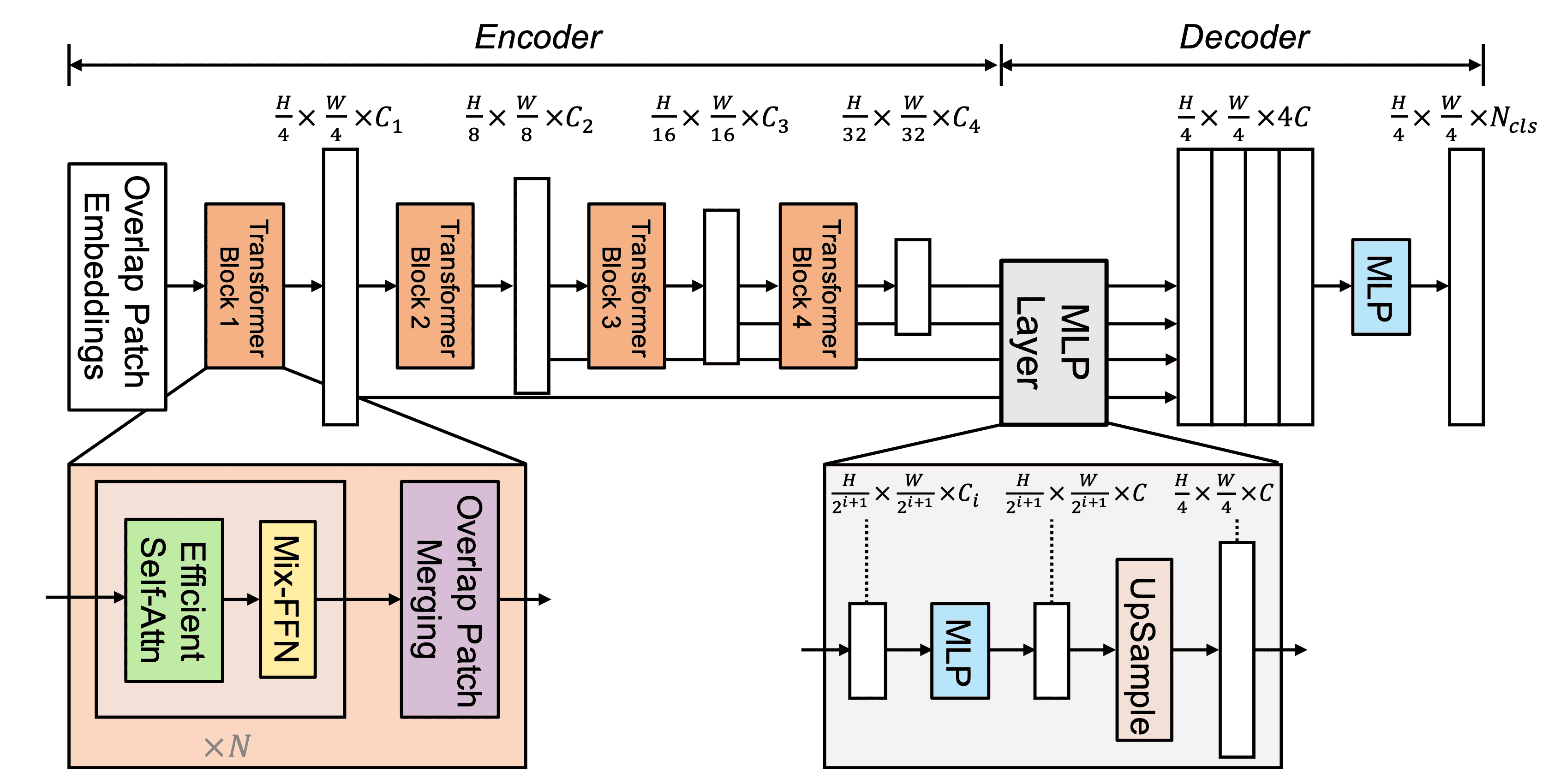
层次化的变压器编码器
本文设计了一系列混合变压器编码器(MiT),MiT-B0至MiT-B5。它们具有相同的结构,但尺寸不同,MiT-B0是最轻和最快的猜测,MiT-B5是最大和最好的性能。
分层特征表示
与生成单一分辨率特征图的Vision Transformer(ViT)不同,该模块旨在生成多尺度特征,如CNN。这是因为高分辨率和低分辨率的特征通常会提高语义分割的性能。更确切地说,给定一个$H\times W\times 3$的图像,进行补丁合并以生成$frac{H}{2^{i+1}} \times \frac{W}{2^{i+1} \times C_i$ 特征$F_i$。然而,$i\in{1,2,3,4\},C_{i+1}>C_i$。
重叠补丁合并
给定一个补丁图像,ViT中的补丁合并过程是将一个$N乘以N乘以3$的补丁变成一个$1乘以1乘以C$的矢量。这是通过将$F_1(\frac{H}{4} \times \frac{W}{4} \times C_1)$转换为$F_2(\frac{H}{8} \frac{W}{8} \times C_2)$而模仿的。这个过程被设计为结合非重叠的图像,所以不能保留局部的连续性。因此,进行了重叠补丁合并,调整了内核大小、跨度和填充大小,以产生相同大小的特征。
高效的自我关注。
编码器计算的瓶颈是自我注意层。在传统的多头自我注意过程中,注意力的估计方法如下。
$$Attention(Q,K,V)=Softmax(\frac{QK^T}{sqrt{d_{head}}) V$$
然而,$Q,K,V$是$N次C$维的向量,$N=H次W$。这个计算复杂度是$O(N^2)$,所以它不能应用于大型图像。因此,为了减少序列长度,引入了以下过程。
$$hat{K}=Reshape(\frac{N}{R}, C\cdot R)(K)$$
$$K=Linear(Ccdcdot R, C)(`hat{K})$$。
然而,$K$是要减少的序列,$Reshape(\frac{N}{R}, C\cdot R)(K)$将$K$转换为大小为$frac{N}{R}\times (C\cdot R)$,$Linear(C_{in}, C_{out})(\cdot) $是$C_{in}$维的张量到$C_{out}$维的张量,代表输出$C_{out}$维张量的线性层。R$是还原率,将计算复杂性降低到$O(\frac{N^2}{R})$。
混合-FFN
ViT使用位置编码(PE)来纳入本地信息。然而,PE的分辨率是固定的,当测试数据的大小不同时,这导致了性能不佳。因此,我们引入了Mix-FFN,它在前馈网络(FFN)中使用了3元/次3元的卷积层。
$$x_{out} = MLP(GELU(Conv_{3\times 3}(MLP(x_{in}))))+x_{in}$$)
然而,$x_{in}$是来自自我注意模块的特征,Mix-FFN将每个FFN与3/times 3$卷积层和MLP相结合。
轻量级全MLP解码器
Segformer采用了一个轻量级的解码器,只由一个MLP层组成。这是可能的,因为分层的Transformer编码器比普通的CNN有更宽的有效接收域(ERF)。All-MLP解码器由以下四个步骤组成。
$$hat{F_i}=Linear(C_i,C)(F_i),/forall i$$$
$$\hat{F_i}=Upsample(\frac{H}{4}\times \frac{W}{4})(\hat{F_i}),\forall i$$$
$$F=Linear(4C,C)(Concat(\hat{F_i})),forall i$$$
$$M=Linear(C,N_{cls})(F)$$。
然而,$M$是一个预测性掩码。
实验
实验中使用了公共数据Cityscapes、ADE20K和COCO-Stuff。平均IU(mIoU)被作为评价指标。
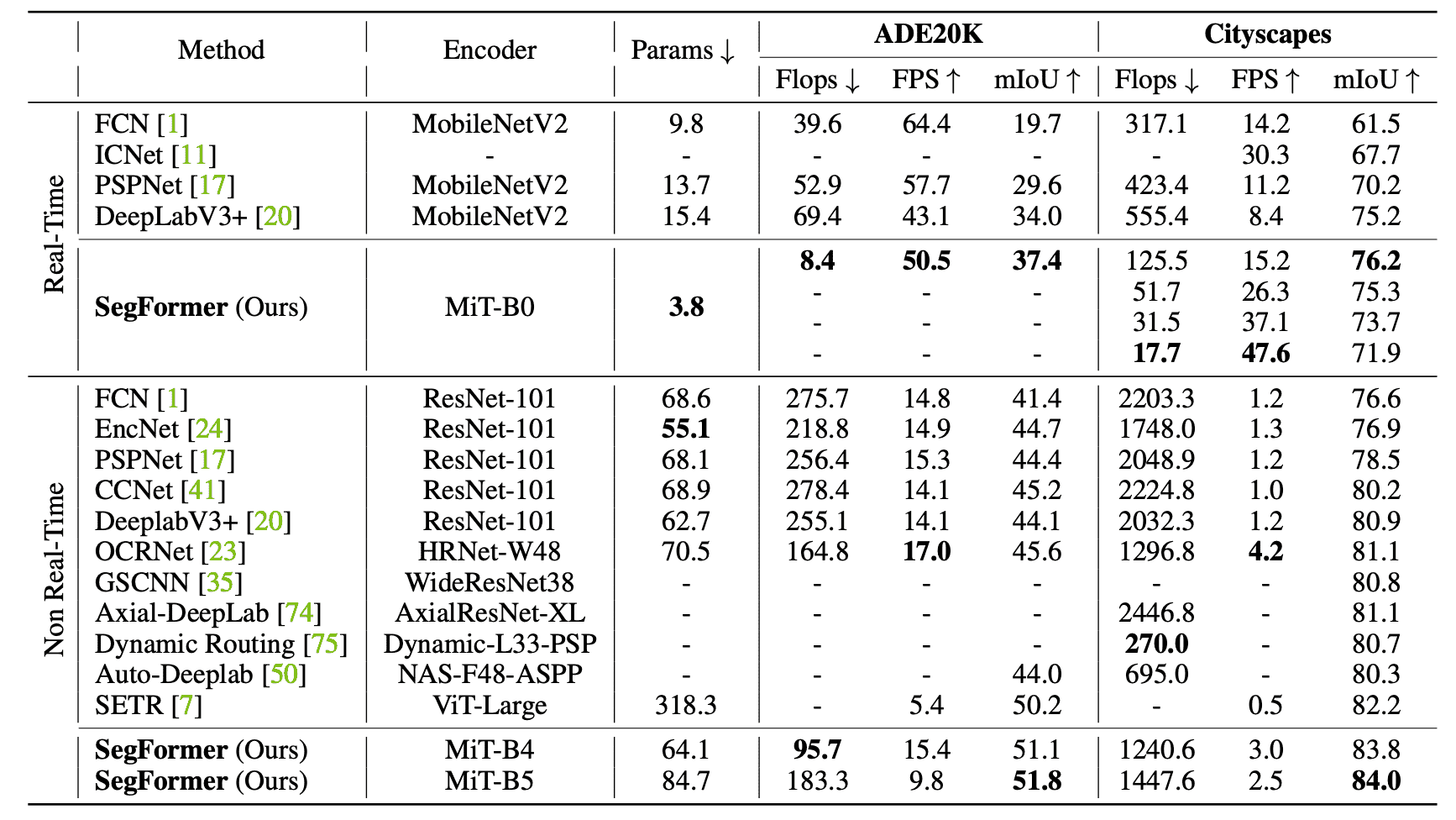
ADE20K和Cityscapes中现有的SOTA模型的性能比较如下表所示。上边是结构较轻的实时模式,以提高计算速度,下边是非实时模式,以提高性能。
对于这两个数据集,尽管与以前的模型相比,参数数量较少,但性能很高,计算速度和准确性都得到了提高。
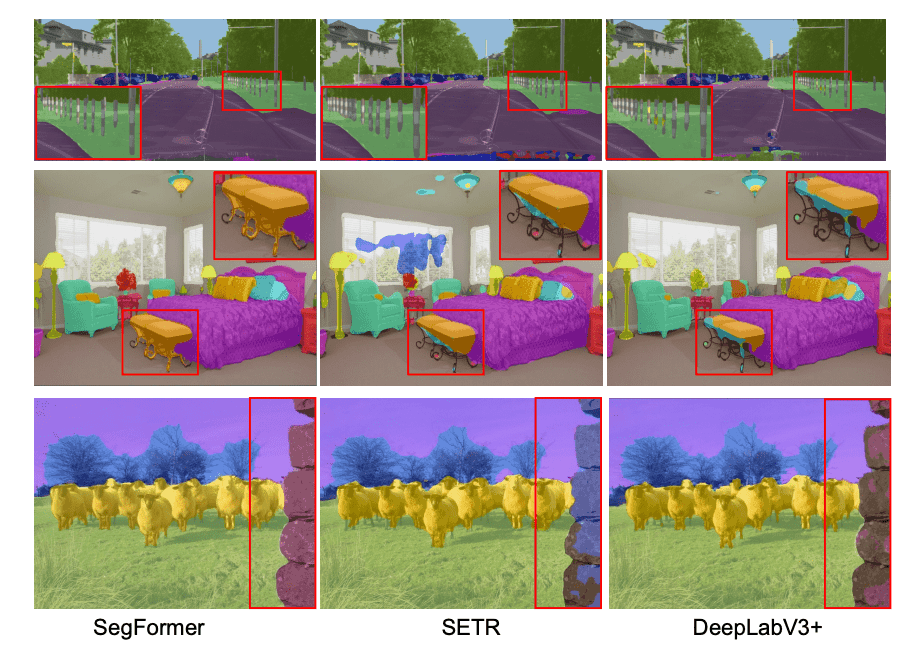
定性结果也显示在下图中:SegFormer编码器能够纳入更高精度的特征,这使得它能够存储更详细的纹理信息,猜测结果能够更精确地预测物体的边界和其他细节。
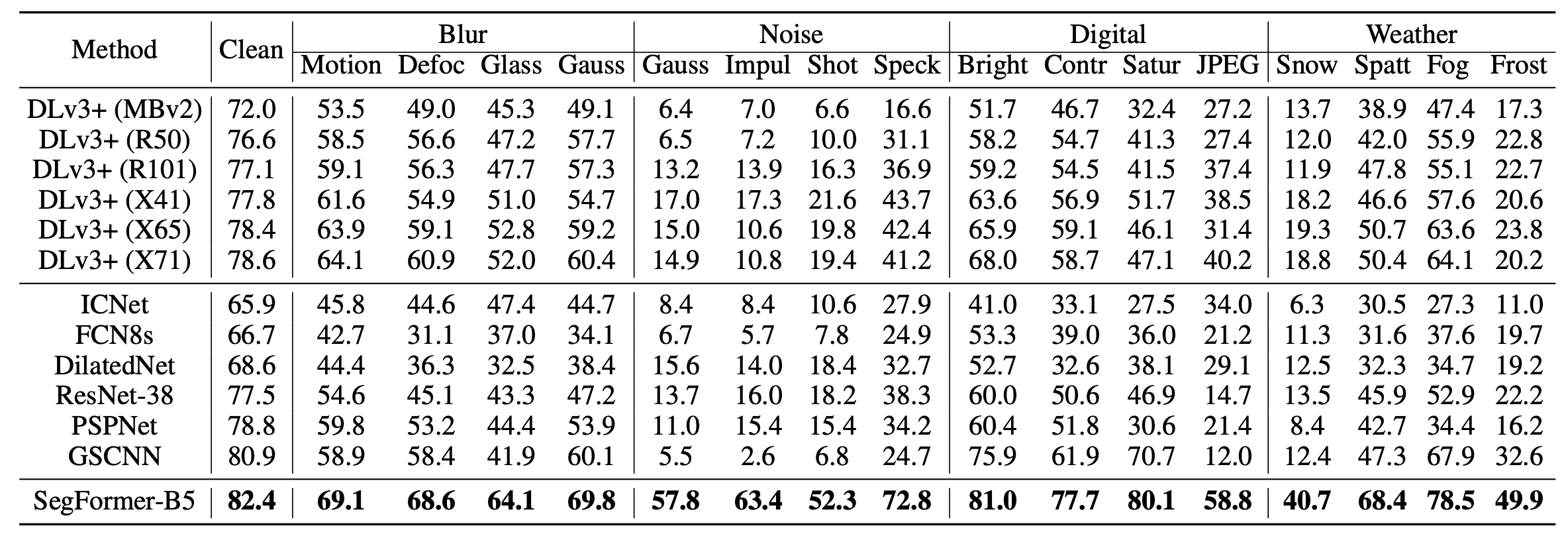
最后,稳健性很重要,例如在自动驾驶方面。为了评估这一点,我们在Cityscapes-C数据集上进行了实验,在Cityscapes的验证数据中加入了各种噪音。结果显示在下面的表格中。
SegFormer显示出比以前的模型明显更高的IoU,其结果对安全关键行业的应用很有希望。
摘要
本文提出了一个基于变换器的分割模型SegFormer。与现有模型相比,它通过消除沉重的计算处理部分,获得了高性能和高效率。它还被认为是高度稳健的。虽然参数的数量已经大大减少,但目前还不清楚它是否适用于低内存容量的边缘设备,确定这一点是未来的一个挑战。



与本文相关的类别

![[任何分割] 零镜头分割模型](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/June2024/segment_anything-520x300.png)


![[PiCIE] 用于无监督语义分割的像素](https://aisholar.s3.ap-northeast-1.amazonaws.com/media/November2021/picie-520x300.png)
